알아둬야 할 사전 지식
(1) iptables 란
네트워크 담당 직무인 개발자 분들이라면 직접 관리까지 하시겠지만, 앱 개발자로서는 낯설 수 있어 간단히만 짚고 넘어가려 한다. 리눅스 계열 OS 에서 사용하는 방화벽 프로그램이라고 보면 된다. iptables 는 요청 단위가 아닌 개별 패킷 단위로 머신에 적용된 규칙을 확인하고 적용한다. 다음 예시를 살펴보자.
$ sudo iptables -L -n --line numbers # iptable 에 적용된 규칙들 확인
...
Chain FORWARD (policy DROP)
num target prot opt source destination
1 DOCKER-USER all -- 0.0.0.0/0 0.0.0.0/0
2 DOCKER-ISOLATION-STAGE-1 all -- 0.0.0.0/0 0.0.0.0/0
3 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
4 DOCKER all -- 0.0.0.0/0 0.0.0.0/0
...
위와 같은식으로 규칙들의 모습을 확인할 수 있는데, 위 상황은 Docker Container가 외부 트래픽을 받을 수 있도록 설정되어 있는 규칙이라고 한다. (User 로 인해 설정된 정책 -> 격리된 Docker Network 처리 정책 -> 허용 저책 등등..)
해당 머신으로 수신되고 송신되는 모든 패킷들에 대해서 iptables 란 방화벽이 규칙을 통해 보호해주고 있으나, 패킷별이기 때문에 오버헤드가 큰 건 아닌가라는 생각까지 들었다. GPT 를 통해 알아보니 다음과 같은 최적화 기법들이 적용되어서 오버헤드가 최소화되어 있다고 한다.
- 위 규칙들을 통한 패킷 필터링은 Kernel 공간에서 실행된다 → 공간 전환에 대한 컨텍스트 스위칭 비용이 없고, 처리 속도가 빠름
- 연결 추적 사용 → iptables 는 기본적으로 기존에 허용된 연결의 후속 패킷을 다시 검사하지 않는다 (conntrack) (위 ESTABLISHED, RELATED 등 지칭이 이를 제어하는 부분이다)
- 규칙 매칭 최적화 → SSH, HTTP 와 같이 자주 일어나는 규칙을 앞쪽에 배치하는 등의 방식을 활용해서 최적화에 신경씀
(2) kube-proxy 란
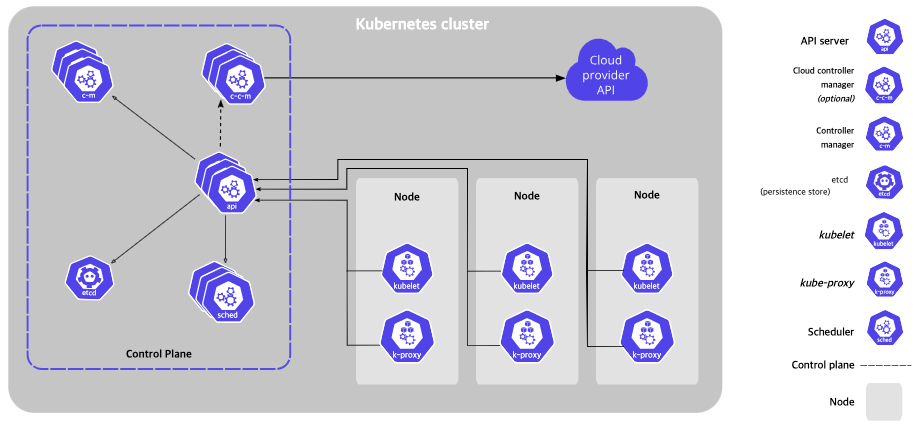
K8s 는 위 모습과 같은 구조를 하고 있고 (자세한건 K8s 관련 포스트들을 참고), 각 Node 별로 Kube-Proxy 가 api-server 와 연결되어 있는 것을 볼 수 있다. Kube-Proxy 는 각 노드의 네트워크 규칙을 제어 (생성/수정/삭제) 하여 해당 규칙을 통해 클러스터가 외부와 통신을 할 수 있도록 지원한다. (1) 에서 살펴본 iptables 와 뭔가 연관이 있을 것 같은 생각이 들면 된다. kube-proxy 는 각 Node 에서 iptables 를 직접 제어한다 (iptable mode 일 경우).
모든 규칙을 다 제어하는 것은 아니고, 일반적으로 정리하면 외부에서 들어오거나 나가는 트래픽에 대한 규칙은 Kube-Proxy 가, 클러스터 내부에 Pod 간 네트워크에 대한 규칙은 클러스터 내부 CNI가 관리한다. 그렇다면 이를 K8s 개념과 매칭해 본다면 Pod 가 노드에 배치될 때는 CNI 플러그인이 동작하여 iptables 를 설정하고, NodePort / LoadBalancer 와 같은 Service 와 EndPoint 가 추가되면 kube-proxy 가 동작하여 iptables 를 설정한다고 볼 수 있다 (물론 100% 는 아닌 것 같으나, 이렇게 이해해보는게 쉬운 것 같다).
(2) K3s 와 K3s 의 Kube Proxy

K3s 는 경량형 쿠버네티스로, 간단하게 SU 을 하여 운영할 수 있도록 제작된 K8s 이다. 정확하게 확인하진 않았지만, K8s 와 대표적으로 다른 점, 그리고 가장 중요한 점을 꼽자면 다음과 같다.
- K3s 는 단일 노드 클러스터를 지원한다 → Master Node 의 역할을 하는 Server Node 하나만으로도 Pod 를 스케줄링 할 수 있다
- K3s 는 주된 K8s 시스템 인스턴스 (kube-system) 들이 합쳐진 싱글 프로세스로 운영된다 → 별도로 kube-system 에서 api-server, kube-proxy 등을 찾을 수 없음
Trouble Shooting
회사에서 K3s 로 SU (K8s 경량 버전) 되어 있는 쿠버네티스 클러스터가 있는데, 해당 클러스터에서 Airflow 가 Helm Chart 로 배포가 되어 있다. Helm Chart 에서 배포 모드를 K8s 모드로 다음과 같이 바꿔주면 Pod 를 띄워서 Task 를 실행하는 방식으로 자동으로 설정된다고 한다.
# values.yml
...
# Airflow executor
# One of: LocalExecutor, LocalKubernetesExecutor, CeleryExecutor, KubernetesExecutor, CeleryKubernetesExecutor
executor: "KubernetesExecutor"
...
Airflow 에 대해선 잘 모르지만, DAG 라는 작업 단위가 있고, DAG 안에서 Task 들을 수행하면서 Workflow 가 흘러가는데, 이 때 Task 단위로 Pod 를 기동해서 일을 수행하도록 설정된다고 한다. 현재 우리 프로젝트에서는 Task 가 약 30~50개 정도 동시에 실행이 되며, 새벽에 2~3시간에 걸쳐서 총 300개~400개 이상의 Task 가 실행되는 구조였다. 즉, 그만큼 Pod 가 여러번 띄워지고 종료되는 상황이다.
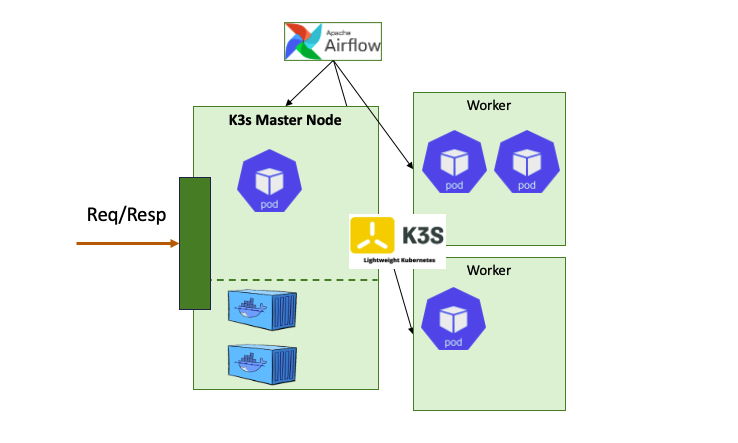
문제는 Master Node 과 진행하는 통신들이 매우 느려지고, K3s 관련 뿐만 아니라 다른 목적으로 수행되는 Container 프로세스들과의 통신, 그리고 클러스터 Pod 에서 외부 서버로 보내는 요청까지 사용하지 못할 정도로 느려지는 현상이 발생하였다. 해당 Node 로 접속하여 자원 활용률을 보니 특정 CPU 가 거의 100% 에 도달한 모습을 확인할 수 있었고 (물론 멀티 코어다), 수행하고 있는 CMD 가 다음과 같은 것을 확인하였다.
/usr/sbin/iptables -t filter -C KUBE_ROUTER_INPUT -m comment --wait
# 문제를 지속 모니터링한 결과, 다른 CMD 들도 한번씩 수행 중 (but 모두 iptables 명령어)
# 100% 도달한 CPU 의 번호는 한번씩 변경됨 (n CPU)
iptables 프로세스에서 100% 가량의 CPU 를 소모하게 된다면, 무한 루프에 빠져 있거나, 실제로 너무 많은 iptables 에 규칙이 추가되어서 요청들을 점검하는데 매우 오래걸리는 현상일 것으로 보여, 다음과 같은 명령어들로 iptables 규칙의 모습을 확인하였다. 모든 규칙 확인시 다음과 같은 출력들이 반복적으로 출력되었다.
$ iptables-save | wc -l # iptables 에 등록된 규칙 갯수 확인
1055488
$ iptables -L -n --line-numbers # iptables 에 등록된 모든 규칙 출력
...
Chain KUBE-ROUTER-FORWARD
...
4716 RETURN all -- 0.0.0.0/0 10.43.0.0/16 /* allow traffic to primary/secondary cluster IP range - EKROEGTNIJ3AP3LC */
4717 RETURN tcp -- 0.0.0.0/0 0.0.0.0/0 /* allow LOCAL TCP traffic to node ports - UNJ5WQL66AAZ6HFY */ ADDRTYPE match dst-type LOCAL multiport dports 50001:50049
4718 ~~
...
Chain KUBE-ROUTER-INPUT
...
Chain KUBE-ROUTER_OUTPUT
...
iptables 에 등록된 규칙이 백만개가 넘어가므로, iptables 를 거쳐야 하는 요청에 대해서 처리를 하는 과정이 매우 오래걸렸던 것이고, 그 중 하나가 $ iptables -t filter -C ~~ 명령 이였던 것이다 (참고로 이 명령어는 'filter' 란 테이블에서 -C 에 해당하는 규칙이 존재하는지 확인하는 용도로, full scan 이 필요한 명령어이다).
출력되는 수많은 규칙에 공통적으로 적힌 부분이 "node port, cluster ip" 따위가 있으며, 이렇게 많은 규칙들이 추가가 되어 있는 모습은 분명 K3s 가 Airflow 의 일을 하기 위해 Pod 를 띄우고 삭제하고를 반복하며 누적된 규칙들로 보였다. 대시보드를 통해 확인해보니 현재 띄워진 Pod 는 없었기 때문에, "네트워크 규칙들이 삭제되지 않는 상황"인 것으로 결론을 내릴 수밖에 없었다. 그렇다면 드는 의문은 다음과 같았다.
1 - Airflow 는 띄운 Pod 에서 외부와 통신을 하는데, iptable 제어를 kube-proxy 가 해주는걸까?
2 - 왜 k3s 의 kube-proxy 는 종료된 pod 에 대한 규칙들을 삭제해주지 못하고 있을까?
3 - 왜 Server Node 에만 백만 개 이상의 규칙이 묶여 있고, Agent Node 는 1000개 정도만 묶여있을까?
1_
알아본 결과 Airflow 에서 Pod 를 띄우고 외부와의 Connection 설정을 해줄 때는, 별도의 NodePort Service 나 Endpoint 를 생성하여 kube-proxy 에게 iptable 제어를 트리거시키지 않는다고 한다. 내가 헷갈렸는데, Pod 가 "외부로 보내는 통신" 과 "외부에서 보내는 통신"은 당연히 다르게 제어된다 (아니 이거 헷갈려서 종일 고민했다..). 즉, iptable 을 직접 수정하지 않아도, 기본적으로 Pod 가 외부로 보내는 트래픽은 SNAT 룰을 자동으로 적용해서 허용된다고 한다 (정확히는 잘 모르겠다). 내 Task 들이 외부와 통신이 가능했던 이유는 이 덕분이였다. 그리고, 외부와의 통신을 위한 규칙은 별도로 제어하지 않는 것으로 결론을 내릴 수 있었다.
2_
k3s 가 규칙들을 제어하지 못하는 상황에 대해서는 k3s 팀에서 다룬 discussion 이 있는 것으로 보인다 (https://github.com/k3s-io/k3s/issues/7244). 최종적으로 follow 를 해보니, K3s 에서는 Network Policy Controller 가 꺼져 있을 경우, 종료된 자원들에 대한 iptable 규칙을 삭제하지 않으며 이것은 의도대로 동작하는 부분이라고 한다. 따라서 삭제를 하고싶으면 추가된 killer.sh 스크립트 혹은 다음과 같은 명령어를 사용하라고 discussion 이 끝난 것으로 보인다 (킬러 스크립트는 오픈 소스를 뒤졌는데 찾지 못했다..).
$ iptables-save | grep -v KUBE-ROUTER | iptables-restore
해당 명령어는 "KUBE-ROUTER" 를 제외한 규칙들을 제외하고 필터링하여 iptable 에 다시 적용하라는 의미로, "KUBE-ROUTER" 가 포함된 명령어들을 모두 삭제한다 (iptable 을 리프레쉬 시켜줌). 위 명령어를 통해서 iptable 을 원복시킬 수 있었고, CPU 사용률과 통신 속도는 모두 정상화 되었다. 하지만 확인 결과 K3s 의 Network Policy Controller 는 disabled 되지 않았었다. 따라서 의문은 그대로였다. 참고로 Network Policy Controller 는 K8s 에서 세밀한 Network 제어를 위해 만드는 리소스인 Network Policy 를 감지하고 적용하며, CNI 플러그인과 연계되어 동작한다.
3_
솔직히 잘 모르겠다. KUBE-ROUTER 관련된 규칙들은 CNI 가 Pod 간 통신을 제어하기 위해 쌓인 규칙이라고 하는 것 같다. 근데 Pod 는 동일하게 스케줄링이 될텐데, 심지어 Server Node 가 아닌 Agent Node 에 더 많이 스케줄링되는 양상을 보였다. 따라서 아마 스케줄링에 관련된 문제는 아니고, Server Node 에서 Pod 가 종료된 후 iptable 규칙을 삭제를 함에 있어서 이슈가 있어서 발생한 문제인건 확실한 것 같다.
더 생각해볼 것들

왜 Server Node 에서만!! 삭제를 못하는 상황이 발생했을까?
다음날 Task 를 몇 번 돌려보니, 역시 종료에 맞춰 iptable 규칙들이 잘 삭제되는 것으로 확인이 되었다. 즉, K3s 가 삭제가 안되는게 아니라, K3s 가 분명히 삭제 명령어를 실행시켰음에도, 조회 요청을 처리하는데 굉장히 오래걸렸던 것처럼, 삭제가 되지 않는 것으로 보인다. 즉, 어떤 시점에서 Server Node 에 Burst 가 발생하여 (제일 첫 실행, 해당 노드에 대한 순간적인 요청 과부하 등) iptable 삭제하는 일이 밀리기 시작했다고 볼 수 밖에 없을 것 같다. 이유는 정확히 알아낼 수 없었으며 (내가 못찾아낸 것이니, 누구라도 알려주면 좋을 것 같다...), 이 일이 또 발생하는 지에 대해서는 지속 tracking 을 하고 재발시 더 정확한 이유를 알아내야 할 것 같다.
왜 좋은 서버 성능임에도 다른 CPU 들이 iptable 의 일을 도와주지 않았을까?
해당 서버는 24vCPU 와 메모리도 높은 매우 우수한 성능의 서버이다. 하지만 htop 을 통해 확인했을 당시, 오직 1개의 CPU 만 100% 를 보여주고 있었고 (물론 한번씩 바뀌었지만, 대상 CPU 는 혼자 100%의 사용률을 보여줬다), 나머지 CPU 들은 조금씩 일을 하거나 아무일을 하지 않는 수준이였다. 왜 iptable 의 일을 같이 수행하지 않을까? 같이 수행할 수 있다면, 이 정도로 부하가 발생하지 않지 않았을까?
이는 iptable 이 싱글 스레드로 개발된 프로그램이며, Netfilter 를 제어함에 있어서 Lock 을 활용하기 때문이다. Netfilter 는 리눅스 커널의 프레임워크이므로 커널 모드에서 제어할 수 있다. 따라서 우리는 iptable 을 통해 Netfilter 에게 "이 규칙을 추가해", "이 규칙을 삭제해", "이 요청 통과시켜도 돼?" 등을 물어보는 것이다. 만약 K3s 에서 Service 가 동시에 생성되어 "$ iptables {save-rule- command} 를 여러번 호출했다면, iptable 은 실행되어 각각 단일 스레드로 CPU 를 할당받으려 할 것이다. 할당이 되어도 멀티 코어여도 운영체제는 이를 동시에 처리하지 않고, Netfilter 는 Lock 을 통해 관리되기 때문에 동시성 제어를 하게 된다.
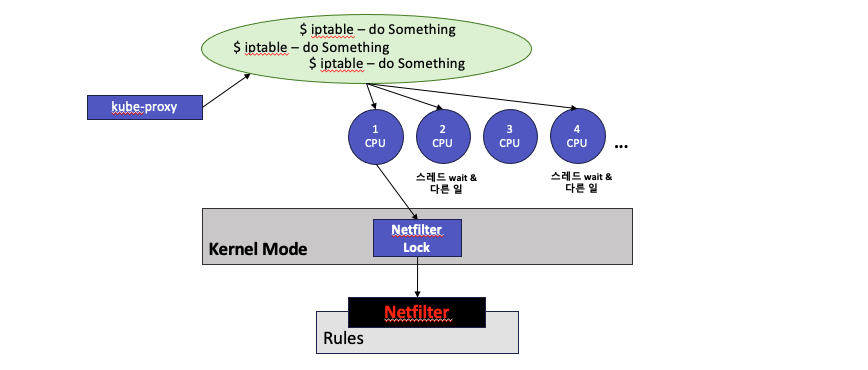
위와 같은 모습으로 Netfilter 에 Rules 들을 락을 통해 관리해서 동시 작업을 못하며, Netfilter 자체가 커널 모드로서의 전환이 지속적으로 필요하기 때문에 다량의 요청시 오버헤드가 발생하기 쉬운 작업인 것으로 보인다. iptables 를 통해 가장 기본적인 패킷 필터링도 진행되는데 (요청에 대한 방화벽), READ 작업이므로 Lock 이 안걸려도 되지 않나 싶었는데 읽는 도중 변경이되면 안되므로 패킷 필터링에 대한 요청시에도 Lock 이 걸리는 것으로 보인다. 따라서 삭제 같은 작업이 밀리기 시작하면서, Rule 들이 쌓이기 시작하고, 패킷 필터링 요청 등 각 작업들은 더 오래걸리기 시작하면서 1번에 말한 시점 이후로 누적이 가속화된 것으로 볼 수 밖에 없는 것 같았다.
글을 마치며
내가 블로깅을 한 이후로 제일 찝찝한 포스트인 것 같다. 재발 방지를 위해 원인을 알고 해결까지 한 깔끔한 포스트였음 좋았을텐데.. Burst 가 존재했다면 시점은 어떤건지 전혀 모르겠고 (사실 발생할 일이 없어보여서 더 이해가 안간다), 내가 생각한 운영체제 관련 상황들도 그냥 내 지식 수준에서 정리한 부분들이라 틀린 소리를 적어놨을 수도 있다.
실제 트래픽이 많고 돌아가는 서비스도 많은 서버들에선 이런 문제는 아무것도 아니겠지... 아무튼 이 문제는 개인적으로는 또 발생했으면 좋겠다 (그냥 적당히 느려진 상태에서 발견했으면 좋겠다 ㅋㅋㅋ). 그 때는 진짜 더 자세히 알아보고 싶다. 특히 다른 컨테이너로 Jupyter 가 하나 떠있는데, 그 Jupyter 에서 하는 액션들도 느려졌었다. 가령, 처음 접속은 오래걸리고, jupyter 에서 파이썬으로 외부로 요청을 날릴땐 오래걸리고, .py 나 파일들 여는건 빠르고.. 이런 현상들에 대해서도 연관관계를 확실히 하면 좋을 것 같다. 단발성이길 바라며 해결은 했지만, 아직 너무 부족하다~~~~ 이 포스트는 꼭 업데이트를 할 수 있도록 해보자!!

'Logging > 인프라' 카테고리의 다른 글
| [문제기록] K8s+Ingress 로 Spring Boot 배포시 Tomcat 400 에러 관련 (0) | 2024.08.12 |
|---|
