
Elastic Search 란
오픈 소스이며, Restful한 검색 및 분석 엔진, 확장 가능한 DB 저장소로, 쉽게 말해서 검색 / 데이터 분석에 최적화된 DB이다.
대표적인 활용 사례로는 우선 데이터 수집 및 분석에 사용된다. 로그와 같은 대규모 데이터를 수집 및 분석하는데 최적화되어 있고, ELK 스택이 통합적으로 사용된다. 또한 Elasticsearch 는 자체적인 검색 엔진을 가지고 있어 검색 최적화에도 굉장히 많이 사용된다. 뛰어난 검색 속도를 자랑하며, 오타와 동의어 등 일반적으로 개발자들에게 높은 난이도의 개발을 요구하는 부분을 해결해준다.
동작 방식
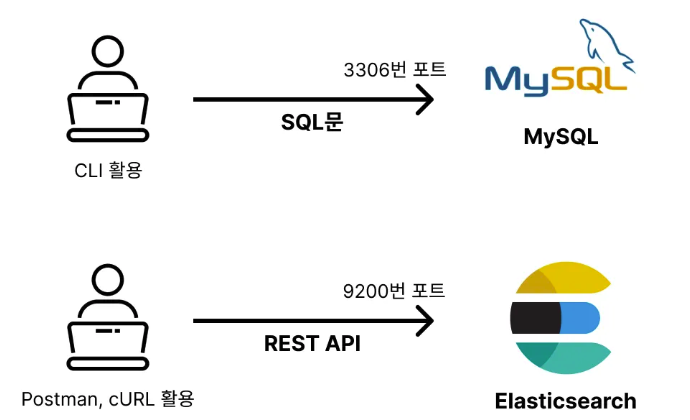
MySQL은 SQL 문으로 3306 포트에 있는 프로세스와 통신을 하는 것이며, Elasticsearch는 REST API 방식으로 9200 포트에 있는 프로세스와 통신을 하는 것이다.
가령, 데이터 삽입을 하기 위해서는 MySQL 에서는 INSERT 문을 사용한다. Elasticsearch 에서는 우리에게 익숙한 POST 로 JSON Body 를 날리면 된다. SELECT는 GET 요청을 사용하면 된다. API 명세서는 Elasticsearch에서 제공해주는 것을 활용하면 된다.
이렇게 API 방식으로 DB를 사용할 수 있어서, 복잡한 SQL 을 따로 구현하지 않아도 되어 개발자들이 사용하기 쉽다. 또한, 확장성 및 커스터마이징이 좋다. 자체적인 웹을 구축 후 사용하는 ES로는 API 를 활용해서 연계할 수 있기 때문이다.
기본 용어 정리
- MySQL은 저장을 시작하기 위해 Table을 만들고, Elasticsearch는 Index를 만든다. 처음에는 우리가 아는 그 "index"와 아예 아무 상관 없다고 생각하는게 좋다
- MySQL은 어떻게 DB에 넣을지 Table의 Schema 를 정의하고, Elasticsearch는 Mapping을 정의한다
- MySQL은 Schema 내의 저장될 칼럼들을 정의하고, Elasticsearch는 Mapping 안에 필드들을 정의한다
- MySQL은 Table에 실제 데이터인 레코드들을 넣고, Elasticsearch 는 Document들을 넣는다.
인덱스 가지고 놀아보기
인덱스 제어
만약 Users 라는 인덱스 (테이블)을 만들고 싶으면, PUT 요청을 보내면 된다.
- PUT /users -- 인덱스 생성
- GET /users -- 해당 인덱스에 대한 모든 정보 조회 (매핑 정보, 존재하는 데이터들 등)
- DELETE /users -- 인덱스 삭제
매핑 정의
Users 라는 인덱스에 매핑을 정의할 수 있다. 인덱스를 먼저 생성한 다음에 mapping 을 정의할 수도 있고, 위에서 PUT /users 요청으로 인덱스를 생성하는 시점에 Body로 매핑 정보를 보내줄 수도 있다.
$ PUT /users/_mappings
{
"properties": {
"name" :{"type": "keyword"}, // String 같은거라고 일단
"age": {"type": "integer"},
"is_active": {"type": "boolean"}
}
}
$ PUT /users
{
"mappings": {
"properties": {
...
}
}
다큐먼트 삽입
인덱스에 생성한 매핑에 맞게 다큐먼트를 넣어볼 수 있다 (RDB로 치면 생성한 테이블의 스키마에 맞게 레코드 삽입)
$ POST /users/_doc
{
"name":"Alice",
"age" : 28,
"is_active": true
}
참고로 Document 생성은 POST /users/create 요청을 통해서도 진행할 수 있다. 이 요청은 보통 /users/create/22 와 같은 형태로 Elasticsearch 내 고유 id에 원하는 값을 사용해서 생성하기 위해 사용되는 요청이다. 하지만 _doc 요청에서도 동일하게 동작한다. 특히, _doc 요청에서 뒤에 {id}를 붙이면, UPSERT를 시키는 요청이므로, version conflict 도 방지할 수 있으니, /_doc 명령어를 일반적으로 사용한다고 알아두자.
다큐먼트 조회
인덱스에 들어있는 다큐먼트들을 조회하는 명령어를 수행할 수 있다. 이 명령어는 elasticsearch 의 핵심 명령어로, 앞으로 다양한 쿼리들, 다양한 옵션들과 기능들을 활용하게 될 검색 API이다. 당장은 SELECT * FROM 의 역할을 수행하는 모습으로 알아두자.
$ GET /users/_search
-- 응답 항목에는 hits 가 있는데, 내부에 반환할 데이터들이 들어 있고, score 라는 항목도 살짝 확인하고 넘어가자
Spring 에서 사용하기
# build.gradle - dependencies
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'
우선 Spring 에서 Elasticsearch 관련 Library를 사용하기 위해서 implementation으로 dependency를 추가해줘야한다. 그러면 코드 내부에서 Elasticsearch와 연계된 Library들을 사용할 수 있다.
# application.yml
spring:
elasticsearch:
urls: http://{elasticsearch-ip}:{port}
일반적인 RDB를 연결할 때 해주듯이, application 설정 파일에 위와 같이 elasticsearch 에 대한 주소를 설정해 두면, Connection 을 준비할 수 있다.
@Document(indexName = "users")
public class UserDocument {
@Id
private String id;
@Field(type = Keyword)
private String name;
@Field(type = Long)
private Long age;
@Field(type = Boolean)
private Boolean isActive;
}
위 설정들을 모두 추가해주면 위와 같이 Document를 (JPA에서 Entity처럼) Java 클래스로 선언할 수 있고, ORM처럼 매핑을 지원받으며 사용할 수 있다.
@Repository
public interface UserDocumentRepository extends ElasticsearchRepository<User, String> {
}
위와 같이 Repository Interface를 만들면 Jpa에서 사용하던 것처럼 제공되는 내장 함수들을 사용할 수 있다. 이렇게 설정을 해두면 Spring 이 기동되는 시점에 @Document로 존재하는 객체에 정의된 indexName을 확인하여, 해당 index들이 실제로 존재하는지 확인하고, 기본적으로 없으면 생성하는 요청을 날리며 동작한다.
아무튼 위와 같은 방식으로 평소에 하던 Spring 개발을 진행하되, Elasticsearch DB와 연계되어 Elasticsearch 엔진의 강력한 기술들을 사용하는 웹 서버를 만들 수 있는 것이다. 이렇게 확장성이 우수한 모습으로 Elasticsearch 의 API 형태의 DB 제어 방식의 장점을 확인할 수 있다.
동작 원리와 Analyzer 소개
우리가 물건을 구매하려 할 때, 물건 이름을 정확하게 기억하고 검색하지 않는다. 예를 들면 맥북 M4 , 파란색 니트 이런식으로 검색한다. 따라서 단어의 순서가 맞지 않아도 검색이 되게끔 구축하는 시스템들인 것이다. Elasticsearch 는 이런 유연한 검색을 잘 지원해주며, 그 중 유연한 검색을 지원하고 싶은 필드는 "text"여야 지원이 된다. 참고로 String 과 같은 정확히 일치를 위한 타입은 "keyword"이다.
$ PUT /products
{
"properties":{
"name": {
"type": "text"
}
}
}
---
GET /products/_search
{
"query":{
"match": {
"name": "맥북 에어 13"
}
}
}
만약 name 필드에 "Apple 2025 맥북 에어 13 M4 10코어" 라고 저장된 제품이 있다면, 해당 제품은 검색된다. 이와 같이 text 타입은 검색 순서가 바뀌어도 검색이 되는 유연한 검색을 지원한다.
Elasticsearch 의 역 Index
- 필드 값을 단어마다 쪼개서 찾기 쉽게 정리해놓은 목록
- "Apple 2025 맥북 에어 13 M4 10코어" -> [Apple, 2025, 맥북, 에어, 13, M4, 10코어] 로 잘라서 저장한다. 이를 토큰화라고 한다.
- 각 토큰을 가지고 있는 Id 를 Value 로 저장한다. (Key Value 과 일반적인 경우와 반대된 상황)
- 검색을 "Apple 2024 아이패드" 라고 검색하면, 이 검색을 다시 토큰화 한다 -> [Apple, 2024, 아이패드]
- Apple 토큰이 있는 ID 들, 2024 토큰을 가진 ID들, 아이패드 토큰을 가진 ID들을 통하 Document 들을 매우 빠르게 조회할 수 있다.
- 이처럼 포함 여부를 가지고 하기 때문에 유연한 검색 가능, 각 아이템 별로 score 를 부여하여 더 많이 가진건 높은 점수 (매우 간단하게 말하면)
Score 시스템은 매우 복잡하며 이 시스템 자체가 Elasticsearch 의 핵심 요소들이다. 가장 대표적으로 다음과 같은 계산 로직들을 통해 검색시 각 Document 의 점수들이 정해진다. 하지만 간단한 기본 적용을 위해서는 일단 위에서 말한 수준만으로도 충분하긴 하다.
- Term Frequency - 검색어가 얼마나 Document 에 많이 있는지
- Inverse Document Frequency - 검색어가 전체 문서 중 얼마나 희귀한지
- Field Length Normalization - Document 가 짧을 수록 점수 높음 (짧은 문서에서 등장하면 더 관련성 높은)
한 단계 더 들어가보는 Analyzer
아까 문자열을 토큰의 배열로 바꿔주는 장치를 Analyzer 라고 부른다 (사실 간단하게 단어 단위로만 자르는건 아니다). 위 그림과 같이 캐릭터 필터, 토크나이저, 토큰 필터로 나뉘어져 있다.
- 캐릭터 필터 - 문자열을 토큰으로 자르기 전 문자열을 다듬는다 (ex : html 태그 제거 - 포함된채로 저장하는 경우 많음)
- 토크나이저 - 문자열을 토큰으로 자르는 역할, 대표적인 것이 Standard 토크나이저 (공백, ,.!?- 와 같은 문장 부호 기준으로 자름, 맨뒤의 . 까지 제거)
- 토큰 필터 - 잘린 토큰을 최종적으로 다듬는 역할, 자주 쓰는 3가지 필터로는 소문자 적용 필터, Stop 필터 (a,the,is 같은 특별한 의미 없는 단어 토큰 제거), -es, -ed 같은 단어들을 원래 단어 형태로 변경해주는 필터 등
Standard Analyzer
Char Filter 는 없고, Standard Tokenizer 를 사용하며, Lowercase Filter 가 적용된 Analyzer 가 가장 기본적으로 적용되는 default analyzer 이다.
Analyzer 의 종류
Analyzer 는 색인 analyzer 와 검색 analyzer 두 가지를 사용할 수 있다 (나중에 적용할 때 진짜 많이 고려하게 되더라). 색인 analyzer 는 지금까지 말한 analyzer, 일반적으로 말하는 analyzer 이다. 검색 analyzer 는 검색할 때 query 로 날린 input text 를 어떻게 토큰화할지 적용하는 analyzer 이다. 당연히 검색 analyzer 는 따로 지정하지 않으면 "색인 analyzer" 와 같은 값으로 적용한다.
이해가 안될 수 있는데, 만약 Product 라는 index (테이블) 이 있다고 하자. Product 안에 description 이라는 필드가 text 로 선언한다고 하면, 이 필드에는 analyzer 를 적용할 수 있다 (안하면 기본적으로 standard analyzer). 하지만, 만약 검색할 때 좀 다른 토큰화가 필요한 경우가 있다. 그런 경우에는 index 생성시 해당 필드에 대하 search_analyzer 를 따로 지정할 수 있는 것. Analyzer 는 필드 단위로 적용하는 것임을 확실히 이해해야 한다.
Analyzer 실습해보기 (다양한 filter 들 실습)
$ Get /_analyze
{
"text":"적용 대상",
"analyzer":"standard"
}
우선 위와 같은 명령어를 통해, 특정 analyzer 가 넣은 text 를 어떻게 토큰화할지 미리 확인할 수 있다. 특히 이는 앱단에서 적용할 때 쿼리에 넣기 위해 사용되기도 하는 use case 까지 봤다. 물론 analyzer 를 char_filter, tokenizer, filter 세 가지 구성 요소를 각각 명시하여 custom 한 analyzer 를 테스트 해볼 수도 있다.
$ PUT /products
{
"settings": { // 이번 요청 안에서 사용할 setting 정의
"analysis": {
"analyzer": {
"products_name_analyzer":{
"char_filter": [],
"tokenizer": "standard",
"filter": []
}
}
}
},
"mappings": { // 테이블 정의 부분
"properties": {
"name": {
"type": "text",
"analyzer": "products_name_analyzer"
}
}
}
}
위 모습 처럼 index 를 생성할 때, analyzer 를 생성 및 지정하고, 필드별로 analyzer를 설정할 수 있다. setting 에는 analyzer 를 명시해서, 원하는 이름 "proucts_name_analyzer"를 선언하였고, index 를 정의하는 mapping 부분에서 이를 사용하였다. 참고로 index 는 테이블 선언이기 때문에, analyzer 를 변경할 수 없다. 변경해야 하면 다시 생성 및 데이터 이전해야 한다. 이 때 검색 analyzer 도 지정할 수 있는 것이다 (필요시).
$ POST /products/_create/1
{
"name":"Apple 2025 맥북 에어 13 M4 10코어"
}
위와 같이 index 를 생성 후 바로 위와 같이 데이터를 넣어줄 경우, 검색을 apple 로 하면 검색되지 않는다! index 생성 요청을 보면 Standard Analyzer 와 다르게 filter 에서 lowercase 를 제외하였기 때문이다.
$ GET /boards/_analyze
{
"field":"content",
"text": "<h1> Running cats, jumping quckly - over the lazy dogs! </h1>"
}
만약 board 라는 인덱스가 있는데, 위와 같이 html 에서 긁어져 오는 데이터들이라 태그들이 포함되어 있다고 해보자. 일반적인 Standard Analyzer 를 적용한다면, h1, h2 와 같은 태그들이 모두 저장된다. 따라서 검색할 때 h1 이라고 검색하면 다 검색이 되는 일이 벌어진다 (h1 같은 태그는 검색 대상이 당연히 아니다). 이럴 때 html_strip 필터를 넣어줄 수 있는 것이다.
...
"analyzer":{
"boards_content_analyzer":{
"char_filter": ["html_strip"], ---> 더 이상 태그들은 저장되지 않는다
"tokenizer" : "standard",
"filter" : ["lowercase"]
}
...
이번엔 다른 경우를 살펴보자. 같은 index 에 다음과 같은 content 를 넣어본다.
$ POST /boards/_doc
{
"content":"The cat and the dog are friends"
}
만약 이처럼 많은 평문이 저장되는 경우라면, 별 의미 없는 a, the, and, are 같은 단어들을 검색하면 정~말 많은 양의 데이터가 검색될 것이다. 우리는 이런 의미 없는 단어들을 검색 점수를 판단함에 있어서 고려해주고 싶지 않을 수도 있는 것이다.
...
"analyzer":{
"boards_content_analyzer":{
"char_filter": [],
"tokenizer" : "standard",
"filter" : ["lowercase", "stop"] ---> a , an, the, or, but, and, ... 다양한 불용어들을 토큰에서 제외시킬 수 있다
}
...
이런식으로 만약에 filter 에 "stemmer" 란 필터를 추가해주면, 위에서 언급했듯이, Running 같은 것은 run 으로, Jumped 같은 것은 jump 로, cats 같은 것은 cat 로 토큰을 "원형"으로 원복시켜 저장해준다.
이렇게 "stop", "stemmer", "html_strip" 기능을 수행하는 친구들은 ES를 간단하게 사용함에 있어서 정말 많이 사용되는 char_filter, filter 들이라고 한다. 하나 더 알아두고 가면 좋은 기능, 정~말 많이 쓰는 기능은 바로 synonym filter 이다. 약간의 노가다가 필요하며, 직접 synonym 들을 정의하는 과정도 필요하다.
$ PUT /products
{
"settings": {
"analysis": {
"filter":{
"products_syn_filter": { ----> synonym filter 를 정의할 수 있고, type 에 synonym 으로 선언해야 한다
"type": "synonym",
"synonyms": [
"notebook, 노트북, 랩탑, 휴대용 컴퓨터, laptop",
"samsung, 삼성" ---> samsung 과 삼성은 같은 토큰으로 취급한다는 뜻
]
}
},
"analyzer": {
"products_name_analyzer":{
"char_filter":[],
"tokenizer": "standard",
"filter": ["lowercase", "products_syn_filter"]
}
}
}
},
"mappings": { // 이제부터 인덱스 정의
...
}
양방향 syn, 단방향 syn
강의에 나오지는 않지만, 위에처럼 정의하면 양방향 synonym 정의이다. samsung <-> 삼성 서로 호환된다는 것이다. 하지만, 검색 시 포함 관계 느낌으로 정의하고 싶을 수 있다. A를 검색하면 a, b 모두 나왔으면 좋겠지만, a 를 검색하면 b까지 나오게 하고 싶지는 않은 경우이다. 이럴 때는 A=>a,b 로 정의해주면, 단방향 synonym 정의를 할 수 있다.
아무튼 위에서 만든 synonym filter 를 사용해서 index 내 특정 필드의 analyzer에 포함시켜서 사용하면, "Samsung Notebook" 이라고 검색만 해도 ["삼성 노트북, 삼성 랩탑, 삼성 휴대용 컴퓨터, samsung labtop, ... "] 등이 모두 검색될 수 있는, 아주 강력한 기능이라 할 수 있다.
한글에서 적용해보기 (Nori 의 등장)
만약 위에서 선언한 boards의 content 필드에, "백화점에서 쇼핑을 하다가 친구를 만났다"라고 데이터를 넣는다고 해보자. 그리고 search 를 match query 로 사용해서, "백화점"을 검색하면, 위 데이터가 조회될까? 조회되지 않는다. 위 데이터는 토큰이 "백화점에서"로 들어가 있기 때문이다. 누가 검색할 때 에서를 붙이는가?
이처럼 standard analyzer, 더 나아가 기본 Elasticsearch 는 한글에 최적화 되어 있지 않다. 사실, 영어를 제외한 어떤 언어에도 최적화 되어 있지 않다. 한글에 최적화된 Analyzer 는 여러개 있지만, 대표적으로 Nori Analyzer 를 일반적으로 사용한다. 사용하려면 Elasticsearch 에 추가적인 plugin 을 넣어줘야 한다. 구글 검색해서 알아서들 설치해보자 ㅎㅎ (참고로 현재 사용하고 있는 Elasticsearch 버전과 정확히 일치해야 한다고 한다)
## Nori Analyzer 의 구성
{
"char_filter": [],
"tokenizer": "nori_tokenizer",
"filter": ["nori_part_of_speech", "nori_readingform", "lowercase"]
}
위 모습은 Nori Analyzer 의 기본적인 구성으로, 새로운 필터 및 토크나이저들은 plugin에 포함된 친구들이다. nori tokenizer 는 standard와 다르게 특수문자가 아닌 의미 단위로 자른다 (형태소 기준으로 자른다고 표현).
$ GET /_analyze
{
"text":"백화점에서 쇼핑을 하다가 친구를 만났다",
"analyzer": "nori"
}
이제 nori analyzer 를 사용해서 토큰화를 시도해볼 수 있는데, 위 결과는 [백화 / 점 / 쇼핑 / 하 / 친구 / 만나] 로 토큰화가 진행된다. 이렇게 되기 때문에, "백화점"이라고 검색을 해도, "쇼핑"이라고 검색을 해도, "친구"라고 검색을 해도 데이터가 조회될 수 있다. nori analyzer 는 정말 많이 사용하고 custom 화 하는 구성 요소로, 한국에선 필수 plugin 이라고 봐도 될 정도라고 한다.
참고로 Elasticsearch 는 기본적으로 NoSQL이기 때문에, NoSQL 의 자연스러운 특성들을 가져간다. 대표적으로 굉장히 테이블이 가변적이고, 특정 column 이 없다고 error 을 던지지도 않는다. 그리고 무조건 NULLABLE 이다 (Not Null 이라는 제약 조건이 없음). 또한 NoSQL 이기 때문에 필드 배열이 가능하다. 참고로 배열로 들어오는 필드에 대해 text 타입으로 선언되었다면, 토큰화 시 ["이젠", "안녕"] 이 들어올 경우 "이젠 안녕" 으로 그냥 띄어쓰기로 만들어 버린 후 생각하고 토큰화한다고 한다.
이 정도로 Elasticsearch 와 가벼운 첫 만남을 마칠 수 있다. 이후로는 Elasticsearch 로 검색하는 쿼리를 어떻게 만드는지, 그리고 이 쿼리를 돕기 위해 어떤 기능들을 사용할 수 있는지 살펴보자.
출처
[Elasticsearch 기본]으로 엮인 모든 포스트들은 교육 사이트 인프런의 지식공유자이신 박재성님의 [실전에서 바로 써먹는 Elasticsearch 입문 (검색 최적화편)] 강의를 기반으로 작성되었습니다. 열심히 정리하고 스스로 공부하기 위해 만든 포스트이지만, 제대로 공부하고 싶으시면 해당 강의를 꼭 들으시는 것을 추천드립니다.
실전에서 바로 써먹는 Elasticsearch 입문 (검색 최적화편) 강의 | JSCODE 박재성 - 인프런
JSCODE 박재성 | 비전공자 입장에서도 쉽게 이해할 수 있고, 실전에서 바로 적용 가능한 'Elasticsearch 입문' 강의를 만들어봤습니다!, 🤬 Elasticsearch는 혼자서 공부하기 왜 이렇게 어려운거야?!비전공
www.inflearn.com
'인프라 기술 > Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] Custom Tokenizer 를 만들어 Elasticsearch 에 넣어보자 (+이론 설명) (10) | 2025.08.10 |
|---|---|
| [Elasticsearch 기본] - 2. Search 쿼리와 활용 가능 기능들 (9) | 2025.07.03 |