
Elasticsearch 는 검색에 대한 요구사항을 해결하기에 도입하기에 굉장히 유용하며, 이제 백엔드 개발 분야에서는 거의 필수적으로 가져가야 하는 지식이라고 생각이 된다. Elasticsearch 를 활용함에 있어서 가장 큰 핵심은 Analyzer, Tokenizer 를 사용하는 것이다. 많은 개발자들이 공감하겠지만, 회사나 프로젝트 내부 도메인 기반으로 검색 기능을 만들려면 존재하는 tokenizer 들로는 어려운 경우가 많다.
검색 자체가 형태소 같은 단위가 아니라 해쉬태그나 연관 검색어 위주로 검색할 때, 도메인 특화되어 있으면 도메인에 특화되게끔 Tokenize 해주는건 Elasticsearch 에선 당연히 어렵기 때문이다. 이번 포스트에선 Custom Tokenizer 적용을 위해 이해가 필요한 영역들과 방법에 대해 적었다.
Lucene 엔진과 Tokenizer 의 동작
Lucene 엔진 소개와 Analyzer
Elasticsearch 를 사용하면서 Tokenizer 개발을 해야겠다 생각한다면, Elasticsearch 내 핵심 엔진인 Lucene 라이브러리에 대해서 알아야 한다. Lucene 은 역인덱스를 사용한 검색 엔진의 핵심이며, Elasticsearch 는 이 Lucene 을 감싸서 하나의 서버로 배포되는 시스템이다. Lucene 은 Java 라이브러리로, 직접 코드로 사용하는 구조이다. 따라서 Custom 한 동작을 정의하기 위해선 이 Lucene 라이브러리의 흐름을 어느 정도 알아야 한다.

Lucene 에서 디렉토리의 저장되는 모습은 위 구조와 같이 흐르게 되어 있고, 그 중 Analyzer 를 통과할 때 역인덱스 저장을 위한 토큰 처리가 진행된다. 기본 포스트에 있듯이 Analyzer 는 Char Filter, Tokenizer, TokneFilter 로 구성되어 있으며, 그 중 핵심이 되는 Tokenizer 와 TokeniFilter 의 구조를 알아보자.
Tokenizer 와 TokenFilter, 그리고 TokenStream
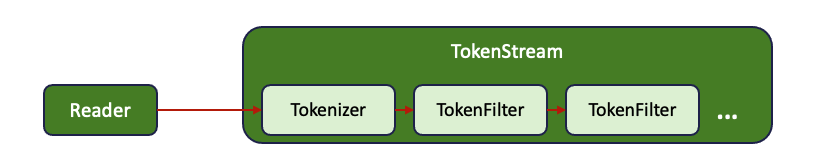
Analyzer 에서 CharFilter 이후에 Tokenizer & TokenFilter 를 처리하기 위해 input 을 전달하게 되는데, 이 때 이 둘의 전체적인 묶음을 TokenStream 이라고 부른다. TokenStream 이란 위 그림 처럼 CharFilter 이후 "토큰 처리를 위한 흐름"이라는 역할 묶음에 대한 추상적인 표현이라고 보는게 이해가 쉽다. 실제로 코드내에서 TokenStream 이라는 객체 안에 Tokenizer 및 TokenFilter 들이 Pipeline 형태로 구성되어 있는데, 이는 관계도를 보면 바로 파악할 수 있다.

TokenStream 이 최상위 인터페이스로, TokenFilter는 Tokenizer를 전달받아 생성된 후 이에 부가 기능들을 입힐 수 있는 완벽한 Decorator 패턴으로 구성되어 있다(데코레이터 패턴 글). 즉 TokenStream을 사용하는 Client 객체는 어떻게 토큰화가 처리될지 정의가 완료된 한 Pipeline (TokenStream) 을 가지고 토큰화를 진행하는 것인데, 이 때 Client에게 적합한 TokenStream 을 생성해 전달하는 역할을 Analyzer가 한다.
코드를 살펴보자. Lucene Analyzer 를 사용하는 Client 측을 개발한다면 (우리의 경우 Elasticsearch 코드가 Client), 다음과 같은 형태로 설계하도록 Baeldung 에서 안내하고 있다.
public List<String> analyze(String text, Analyzer analyzer) throws IOException {
List<String> result = new ArrayList();
TokenStream tokenStream = analyzer.tokenStream(FIELD_NAME, text);
...
while(tokenStream.incrementToken()){
result.add(attr.toString());
}
...
}이처럼 Client 는 완성된 TokenStream 을 Analyzer 에게 전달받고, Tokenize 요청인 incrementToken() 함수를 호출하게 된다. 중요한 점은 TokenStream 의 가장 Root 객체는 항상 Tokenizer 로 사용해야 정상적으로 동작한다. 다음 예시를 통해 데코레이터 패턴으로 형성된 TokenStream 이 어떻게 동작하는지 알아보자.
class MooncakeTokenizer extends TokenStream {
CharTermAttribute cta = addAttribute(CharTermAttribute.class);
...
@Override
public boolean incrementToken(){
if(!isProcessing)){
// 토큰화 및 Queue 저장
}
if(!tokens.isEmpty()){
termAttr.append(tokens.poll());
return true; // 다음 필터에게 true 상태로 전달
}
return false;
}
}
Tokenizer의 incrementToken() 함수는 기본적으로 Token 화 및 Filter 들에게 Token 전달을 메인 동작으로 진행한다. 세부 동작은 실제 Tokenizer 클래스 만들면서 살펴보고, 지금 당장은 위 incrementToken 함수가 "가장 먼저 실행되는 함수" 임을 아는 것이다. 일단 "true 를 반환하면 토큰을 cta 에 담아 Filter 에게 전달"한다고 보면 된다.
class LowerCaseTokenFilter extends TokenFilter {
CharTermAttribute cta = addAttribute(CharTermAttribute.class);
...
protected LowerCaseTokenFilter (TokenStream input){
super(input);
}
@Override
public boolean incrementToken() throws IOException {
if(!input.incrementToken()){ // 상위에서 false 였으면 같이 false 반환
return false;
}
String mine = termAttr.toString().toLowerCase(); // input 이 cta 에 토큰을 저장해둠
cta.setEmpty().append(mine); // 자신이 할 일을 하고 새롭게 저장
return true;
}
}
---
// 실제 TokenFilter 클래스를 보면 기존 input 을 반드시 가지고 선언하라고 되어 있다
public abstract class TokenFilter extends TokenStream implements Unwrappable<TokenStream> {
protected final TokenStream input;
protected TokenFilter(TokenStream input) {
super(input);
this.input = input;
}
...
}
TokenFilter 는 구조상 반드시 input 을 가지고 선언하게 되어 있는데, TokenStream Pipeline 에서 첫번째가 될 수 없기 때문이다. 상위 Tokenizer 혹은 TokenFilter 에서 토큰을 전달할 때, cta 를 통해 전달하는데, 여기서 토큰을 꺼낸 뒤 할 일을 수행 후 다시 저장하고 다음 Filter 로 보낸다. 참고로 addAttribute 는 AttributeSource 란 객체 내에서 관리되는데, 저장된 속성이 있다면 해당 속성을 반환하고 없다면 새로 빈 값을 만들어서 반환한다 (아래에서 더 살펴보게 됨).
class MooncakeAnalyzer extends Analyzer {
...
@Override
public TokenStream tokenStream(String fieldName, Reader reader){ // 라이브러리 봤을 때 사실상 이렇게 흐르진 않아 보였는데, 역할적인 측면에서 이해하자
...
TokenStream tokenizer = new MooncakeTokenizer();
TokenStream lowerCasefilter = new LowerCaseTokenFilter(tokenizer);
TokenStream htmlFilter = new HtmlTokeFilter(lowercaseFilter)
...
return htmlFilter;
}
}
만약 Analyzer 까지 만들어야 할 일이 있다면, 아마 위와 같이 만들어질 것이다. Client 측에서 사용할 Analyzer 를 구성해서 전달해야 하므로, 위와 같이 TokenStream 을 tokenizer 를 시작으로 구성하여, 전체 TokenStream Pipeline 을 전달하는 모습이다. 이 analyzer 를 위에서 Baeldung 예시와 연결지으면 되겠다. 지금 중요한건 "데코레이터 패턴으로 TokenStream이 동작하는 모습"만 이해하면 된다.
Elasticsearch 에 사용할 Custom Tokenizer 개발
Tokenizer를 만들려면 Lucene을 사용해야 하기 때문에 Java 프로젝트를 만들어서 적절한 Library 들을 import 해야 한다. 나는 gradle 로 만들었고, Elasticsearch 에 넣어줄 것이기 때문에 다음과 같이 import 하였다.
# build.gradle 파일 dependencies 내부
...
// 설치된 elasticsearch 버전과 완전히 동일해야 함
implementation 'org.elasticsearch:elasticsearch:8.17.4'
// Elastic 8 버전은 Lucene 9를 사용하도록 안내
implementation 'org.apache.lucene:lucene-analysis-common:9.7.0'
...
AttributeSource 와 Attribute
public abstract class TokenStream extends AttributeSource implements Closeable {
public static final AttributeFactory DEFAULT_TOKEN_ATTRIBUTE_FACTORY;
...
}
위에서도 등장했듯이, Attribute 은 Tokenize 개념에 있어서 빠질 수 없는 정보이기 때문에, 간략히 알고 가는게 좋다. 우선 Attribute 란, 각 토큰에 붙는 정보들이다. CharTermAttribute 은 토큰 텍스트 값 자체를 말하며, 그 밖에도 Offset Attribute, Position Attribute 등이 있다고 한다 (토큰 부가정보로 같이 저장되기도 함). TokenStream 은 위와 같이 AttributeSource 를 상속받는데, AttributeSource 는 이 Attribute 들을 관리하는 객체이다 (addAttribute 요청을 처리하는 객체).
따라서 TokenStream 들은 자신의 역할에 맞게 AttributeImpl들 (다양한 Attribute들) 을 준비한다. 대부분 TokenStream 객체들은 Token 텍스트 값을 가지고 행동 들을 하기 때문에 CharTermAttribute 은 모두 들고 있다고 생각하면 된다. Tokenizer 에서 input 을 가지고 CharTermAttribute 을 AttributeSource (TokenStream 의 한 역할) 에 저장해두면, 후속 TokenFilter 들이 이를 꺼내와서 사용한다 (addAttribute 함수).
AttributeSource 는 Attribute 들을 관리하는 역할을 주로 하고, 내부적으로 AttributeFactory 를 가지고 있는데 이 객체에게 각 Attribute 생산을 위임한다는 정도만 일단 알아도 된다.
Custom Tokenizer
public class MooncakeTokenizer extends Tokenizer {
private final CharTermAttribute cta = addAttribute(CharTermAttribute.class);
private final Queue<String> tokens = new ArrayDeque<>();
private boolean isProcessing = false;
@Override
public boolean incrementToken() throws IOException {
clearAttributes();
if (!isProcessing) {
isProcessing = true;
char[] writingGround = new char[1024];
StringBuilder rawBuilder = new StringBuilder();
int length;
while ((length = input.read(writingGround)) != -1) {
rawBuilder.append(writingGround, 0, length);
}
String inputText = rawBuilder.toString(); // rawText 를 추출한다
doMyExtract(tokens); // Token 을 모두 뽑아서 Queue에 넣어둔다
}
if (!tokens.isEmpty()) {
termAttr.append(tokens.poll());
return true;
}
return false;
}
@Override
public void reset() throws IOException {
super.reset();
tokens.clear();
isProcessing = false;
}
}
Custom Tokenizer 를 만들려면 사실 이론을 몰라도 위 형태만 갖추면 바로 되긴 한다 (그냥 궁금해서 이것 저것 공부했다). doMyExtract() 함수 부분에서 도메인별로 토큰화하는 방식을 Java 코드로 개발해서 넣으면 된다. 필드들은 위에서 살펴 본 토큰을 담는 CharTermAttribute 이 있고, Token 화 이후 저장하는 공간인 Queue, 그리고 processing 현황이 있다. 함수별로 살펴보자.
incrementToken()
한가지 중요한 점은, Token 화 된 모든 텍스트를 Queue에 담아서 TokenFilter 로 전달하지 않고, (1) isProcessing = false 일 때 전체를 토큰화 이후 Queue 에 보관하고, (2) isProcessing = true 일 때 하나씩 꺼내서 Filter 처리를 하는 방식인 것이다. 즉 10개의 토큰이 있다면 이 함수는 10번 호출된다. 다시 한번 Baeldung 예시 코드를 살펴보자.
public List<String> analyze(String text, Analyzer analyzer) throws IOException {
List<String> result = new ArrayList();
TokenStream tokenStream = analyzer.tokenStream(FIELD_NAME, text);
...
while(tokenStream.incrementToken()){
result.add(attr.toString());
}
...
}
while 문으로 tokenStream 이 false 를 반환할 때까지 순환을 하는 모습을 확인할 수 있으며, false 일 때는 Token Queue 에 더 이상 남은 토큰이 없는 경우이다. 그 때가지 Queue 에서 하나씩 꺼내고 Filter 처리를 한 이후, Client 단에서 토큰화된 결과 자료구조에(result) 담는 방식이다. 즉, CharTermAttribute 에는 토큰 한 개씩만 담기며, 다음 incrementToken 호출 때 다음 토큰이 담기기 때문에, 맨 위에서 clearAttribute() 라는 함수를 호출해 주는 것이다.
결과적으로 최초 호출시 (isProcessing=true) Tokenizer 는 토큰화 대상 text 를 Tokenizer 부모 클래스의 Reader 로 부터 읽어오게 되고, 각자 토큰화(개발자가 직접 개발)를 하여 Queue 에 저장을 한다. 이후 호출시에는 Queue 에 있는 Token 들을 하나씩 꺼내면서 CTA에 담고 return true 하는 방식으로 개발하면 Custom Tokenizer 는 완성된다.
reset()
말 그대로 초기화를 담당한다. TokenStream 은 Analyzer 가 사용될때마다 인스턴스를 재활용하는데, 이 때 이전 상태로부터 초기화를 해주기 위해, "TokenStream 사용 전"에 자동으로 호출된다. Custom Tokenizer 에서 사용한 자원들을 초기화해주면 된다. super.reset() 도 당연히 필수이며, Reader input 객체 (요청 input 읽는 친구) 를 초기화 해주기도 한다.
clearAttribute 과 분리되어 있는 이유는 생각해보면 알 수 있는데, reset 함수는 TokenStream 이 사용되는 시점에 호출되지만, clearAttribute 은 Token 이 하나씩 Filtering 될 때마다 호출되기 때문이다.
Tokenizer Elasticsearch 에 넣기
Elasticsearch 에 plugin 설치하기
AnalysisPlugin 코드 추가
이제 개발했으니 Elasticsearch 에 넣어줄 차례이다. Elasticsearch 는 plugin 형태로 customize 한 역할체들을 넣어줄 수 있다 (analyzer, similarity, tokenizer 모두 동일). Tokenizer 같은 경우는 프로젝트 내 다음과 같이 Plugin 선언을 해주면 되는데, 이 부분은 Elasticsearch 에게 알려주는 거라고 생각하고 넘어가자.. ㅎㅎ
public class MyCustomPlugin extends Plugin implements AnalysisPlugin {
@Override
public Map<String, AnalysisProvider<TokenizerFactory>> getTokenizers() {
return Map.of(
"mooncake_tokenizer", // 이 부분은 쿼리에 쓰일 text
(IndexSettings indexSettings, Environment environment, String name, Settings settings) ->
TokenizerFactory.newFactory(name, MooncakeTokenizer::new)
);
}
}
인프라 적용 (Elasticsearch 재기동)
ES에 plugin 들을 넣어주기 위해선 1) Elasticsearch 용 Plugin 형태로 압축과 2) Elasticsearch 의 bin 폴더에 .zip 이 있는 상태로 ES 재기동 이렇게 두 단계로 진행되면 된다. 압축은 폴더 자체를 압축하면 되는데 해당 폴더 안에 개발한 내용을 빌드한 jar 파일을 두고, descriptor properties 파일을 만들어주면 된다. (zip 파일 구성 때문에 꽤나 애먹은 구간)
# plugin-descriptor.properties 파일
name=mooncake-tokenizer
description=This is tokenizer, not analyzer.
version=0.0.1
elasticsearch.version=8.17.4
java.version=17
classname=com.mooncake.MyCustomPlugin
위 구성은 Elasticsearch 가 저장할 메타데이터들로, 요청에 대한 응답에 표기되기도 하기 때문에 형식을 잘 지켜줘야 한다. 필수 항목이 없으면 plugin 설치 실패한다. 이후 다음과 같이 진행하자
$ ls ~/custom-tokenizer
plugin-descriptor.properties mooncake-tokenizer.jar
---
$ zip -r ../mooncake-tokenizer.zip . -- 외부에 해당 폴더 전체를 압축한 mooncake-tokenizer.zip 을 생성
---
$ unzip -l ../mooncake-tokenizer.zip -- 압축한 폴더 내용 출력으로 확인 가능
Archive: mooncake-tokenizer.zip
Length Date Time Name
--------- ---------- ----- ----
169 2025-07-09 13:49 plugin-descriptor.properties
14652 2025-08-01 14:42 mooncake-tokenizer.jar
--------- -------
14821 2 files
위와 같이 zip 파일을 준비했다면, 해당 zip 파일을 Elasticsearch 설정 /bin 폴더에 넣어주고 기동시키면 된다. 만약 이미지를 사용해 ES를 사용하고 있다면, 다음과 같이 Dockerfile 을 작성해주고, 컨테이너를 기동시키면 Elasticsearch 에 성공적으로 plugin 을 설치할 수 있다. 이후 이미지 생성하면 성공적으로 plugin 설치된 로그를 확인할 수 있다.
FROM elasticsearch/elasticsearch:{ver}
COPY {경로}/mooncake-tokenizer.zip /tmp/
RUN bin/elasticsearch-plugin install file:///tmp/mooncake-tokenizer.zip
Test 해보기
Elasticsearch 에 요청(Kibana DevTools)을 보내서 설치된 플러그인을 확인할 수 있고, 특정 텍스트를 개발한 토크나이저를 통해 토큰화시켜볼 수 있다. 만약 둘 중 하나라도 응답하지 않는다면 제대로 설치된 것이 아니니 확인이 필요하다.
$ GET /_cat/plugins --- HTTP 요청
RESP:
{노드-ID} mooncake-tokenizer 0.0.1
{노드-ID} another-plugin 0.3.3
$ GET /_analyze
{
"tokenizer": "mooncake_tokenizer",
"text": "테스트 해볼 텍스트!"
}

'인프라 기술 > Elasticsearch' 카테고리의 다른 글
| [Elasticsearch 기본] - 2. Search 쿼리와 활용 가능 기능들 (9) | 2025.07.03 |
|---|---|
| [Elasticsearch 기본] - 1. 기본 개념, 동작 원리와 Analyzer (7) | 2025.06.27 |