지금까지 Process가 관리되는 모습과, CPU 할당을 위해 OS가 Process들을 어떻게 Scheduling하는지에 대해서 알아봤다. Process 들은 서로 다른 목적을 가지고 수행이 되는 Program들이라는 점을 이해했고, Process들이 자기가 수행되는 OS 공간 내에서 System Call 등을 통한 컴퓨터 자원을 사용한다는 점을 이해했다면, Process Synchronization에 대해서 생각해볼 필요가 있다.
병행 제어는 코드들도 등장하여 생각보다 복잡하고 어려울 수 있는 부분이다. 생각보다 긴 포스트가 되었는데 한번에 이해할 수는 없더라도 여러번 읽어보고 다른 포스트, 다른 강의들도 참고하면서 공부하다보면 금방 이해할 수 있을 것이다. (나부터 더 이해할 수 있도록... ^^)

(1) Process Synchronization

일반적으로 Process, OS 등에서 데이터를 사용할 때는, Data를 저장하고 있는 공간에서 조회를 하여, 본인이 할 일을 진행한 후, 필요시 연산 결과를 저장하는 Flow로 진행이 된다. 이 때, Data를 저장하고 있는 공간을 Storage Box (S-Box), 연산 등의 일을 수행하는 곳을 Execution Box (E-Box) 라고 명명해보자. 즉, E-Box로는 CPU, 프로세스 등이 있고, S-Box 로는 당연히 Memory, Disk, 프로세스 내의 주소 공간 등이 있을 것이다.
만약 S-Box가 공용일 경우 (Kernel Data 에 대한 두가지 프로세스, 혹은 프로세스 내 주소공간 공용 Data에 대한 두가지 쓰레드 등), 누가 먼저 사용하였는지가 문제될 수가 있다. 가령, 1번 E-Box 가 일을 수행하고 반납을 했는데, 2번 E-Box가 일을 수행할 때 1번과 반대되는 일을 했다고 하자. 다시 1번 E-Box가 이전에 자기가 저장한 Data가 필요한데, 2번 E-Box로 인해 내가 원하는 값이 아닌 값을 가져오게 될 수 있는 것이다.
Race Condition (경쟁 상태)
Race Condition(경쟁상태)란 둘 이상의 객체가 하는 입력, 저장 등의 순서가 결과값에 영향을 줄 수 있는 상태를 말한다. 운영체제에서 Race-Condition이 발생할 수 있는 상황은 Process들의 Kernel Data에 대한 사용에서 발생한다. 예를 들면, Process A가 Kernel Mode 수행 중 ISR이 실행되어 다른 Kernel Mode Routine이 실행이 되거나, Process A가 Kernel Mode 수행 중 Process B가 System Call을 하여 Context Switch를 야기시켰을 경우 등이 있다. 그러면 이 Race Condition에서 시작을해서, 병행 제어가 어떤식으로 문제가 커져가고, 어떤식으로 해결법을 발전시켜 왔는지 알아보자.

다음 그림과 같이 Process A가 Kernel Mode 중에 Kernel 자원인 count 의 값을 1 증가시키는 instruction을 수행하고 있었다고 하자. Process A는 count 값에 대한 IO를 처리하기 위해 Non-preemptive하게 CPU를 반납했을 것이고, OS가 해당 루틴을 처리하기 위해 count 값을 CPU 내부 Register 로 불러들였을 것이다. 이 때 이 값을 증가시키기 전에, Process B에서 Interrupt를 발생시킨 것이다. CPU는 instruction to instruction 으로 Interrupt Line을 점검하기 때문에, 위와 같은 상황이 발생할 수 있는 것이다.
Process B에서 발생시킨 Interrupt 는 처리 루틴이 count의 값을 1 감소시키는 것이라고 하자. 따라서 최종적으로 두 Kerenel Routine이 모두 끝난 뒤라면, 원래 count 값은 그대로여야 한다. 하지만, OS 정책상 Kernel Mode 중 가로챈 Process B의 ISR은 수행을 취소하게 되어, count 값이 miss가 발생하게 된다. 이렇게 Race-Condition 문제가 발생하게 된다.
그럼 당연하게 이런 생각을 할 것이다.
Interrupt를 잠깐 Disable 시키고, 일 끝나면 Interrupt 를 Enable 시키면 되는거 아닌가?
맞는 말이다. OS가 Kernel Mode에 있을 때는 할당 시간이 끝나도, Interrupt가 발생하지 않게끔 막아놓으면 된다. 그리고 User Mode로 전환될 시 그 때 바로 Interrupt가 발생할 수 있도록 한다.
하지만 Interrupt를 막는다고 완전히 해결되는 것은 아니다. 현재 시스템은 Multi-processor로 운영이 되어, CPU가 여러개이기 때문에 해당 CPU에 대한 Interrupt를 막는다 하더라도 다른 CPU가 가지러 Kernel Mode로 들어갈 수 있기 때문이다 (1CPU는 1 mode state 를 가지고 있다). 이와 같은 경우에도 막연한 Interrupt Disable이 아닌, 해당 Data에 대한 Lock을 걸면 된다. Kernel 전체에 대한 Lock을 활성화 시킬 수도 있으나, 그럼 Multi-core 에서 Kernel Mode를 사용할 수 있는 CPU는 1개가 되므로 비효율적인 시스템일 것이다. 그렇다면 다음과 같은 상황을 살펴보자.
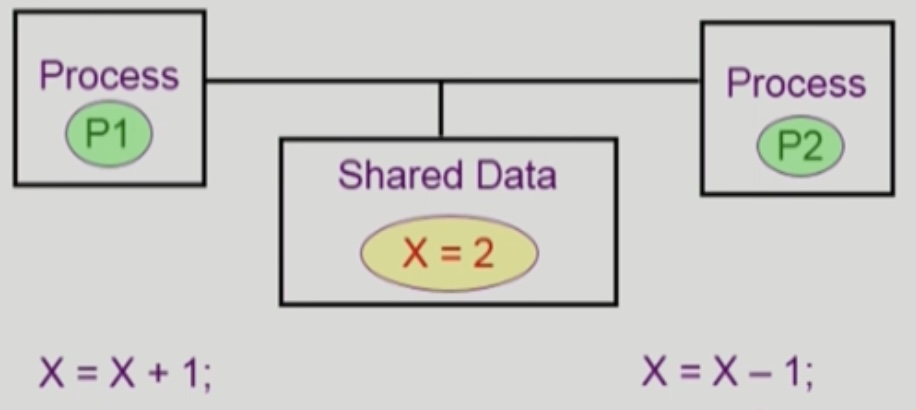
해당 그림과 같이 Process 1이 수행중에 Timer Interrupt가 발생하여 문맥 교환이 발생하여 Process 2가 CPU를 할당받게 되었다. 이와 같은 상황도 문제일까?
일반적인 상황이라면, 전혀 문제가 아닌 상황이다. 일반적인 상황에서는 자신의 주소 공간내에서 데이터를 다루기 때문에 큰 문제가 발생하진 않지만, Kernel Mode 수행중일 때 문제가 생기는 것이기 때문이다. 공유 데이터를 건드릴 때 문제가 발생하는 것이지, 문맥 교환시 문제가 발생하는 것이 아니란 점을 확실히 알아야 하며, 그 차이를 Critical Section을 통해서 정리할 수 있다.
Critical Section이란 공유 데이터를 접근하는 Code의 영역을 말한다 (공유 데이터 그 자체가 아니라, 공유 데이터를 접근하는 코드). 즉, Critical Section은 당연히 Kernel Mode 내의 영역이며, 여러 CPU가 Kernel Mode일 시 똑같이 접근할 수 있는 곳이다. 그리고 특정 Process가 Critical Section에 있을 때, 다른 모든 Process는 Critical Section에 들어갈 수 없어야 한다.
"공유 데이터에 Concurrent 접근시, Race-Condition에 의해 Data가 잘못되는 동기화 문제가 발생할 수 있다."
"공유 데이터에 대한 일관성을 유지할 수 있는 순서 Mechanism이 필요하다"
"문맥교환이 아니라 공유 데이터를 접근하는 Critical Section에 대한 Control이 필요하다"
이렇게 공유 데이터 동기화 문제를 제어하기 위해서는 확실히 Enable, Disable 과 같은 Control을 해야함을 이해했으면 됐다. 이제는 그 Control 문제를 운영체제에서는 어떤식으로 해결이 되는지 확인해보자.
(2) Semaphore

인쇄기가 한 대밖에 없는 사무실이 있다고 해보자. 이 인쇄기는 특이한 인쇄기라서 만약에 인쇄가 여러 요청이 들어온다면, 그냥 들어온 요청을 한꺼번에 출력하는 인쇄기이다. 이 인쇄기를 그냥 아무 제약 없이 쓸 수 있게 해놓는다면, 인쇄한 결과물이 그 어떤 사용자도 원하는 결과물이 아닐 것이다. 따라서 우리는 인쇄방을 만들 것이고, 인쇄방을 들어가기 위한 열쇠를 만들 것이다. 인쇄방에는 한 명만 열쇠를 할당받아 들어갈 수 있고, 사용하는 동안 잠궈놓을 것이며, 다 완료가 된다면 열쇠를 관리인에게 반납을 할 것이다. 관리인은 기다리고 있는 사람에게 열쇠를 할당하게 된다.
당연히 이 예시를 보면 이해가 되었겠지만, 인쇄기는 공유 자원, 인쇄는 공유 자원 사용이며, 사람은 프로세스, 관리인은 운영체제이다. 공유자원인 인쇄기를 사용하기 위해 인쇄방에 들어가므로, 인쇄방은 Critical Section이라고 할 수 있겠다. 이 인쇄방을 들어가기 위해 열쇠를 얻고, 사용을 완료했으면 열쇠를 반납해야 한다.
[열쇠]라는 물품을 통해서 공유 자원 사용에 대한 시스템 뼈대를 만들어 준 것처럼, Semaphore란 공유 자원 사용에 대한 접근 방안을 제시하기 위해 마련된 정수 변수로, 두 가지 함수를 제시하여 방안을 제시하는 추상 자료형을 말한다. 열쇠를 관리인에게 받는, 공유 데이터를 획득하는 과정을 P 연산, 열쇠를 관리인에게 반납하는, 공유데이터를 반납하는 과정을 V 연산이라고 한다. 따라서 그냥 단순하게, "critical section에 들어가기 전에는 P연산, 나온 후에는 V연산을 하라" 라는 추상적인 뼈대를 제시해주고, 해당 함수들은 개발자들이 구현하게 하는 정의를 해놓았다고 보면 된다.
Semaphore Resource S
typedef struct (){
int value; # S양, 자원의 양
sturct process *L # 뒤에나오는 Block & Wakeup 방식을 위한 PCB Pointer 집합, 당장은 무시
} S (Semaphore)
-----
P(S) = while (S.value ≤ 0) : # no-op
S.value--; # while 탈출시 사용 시작
V(S) = S.value++; # 어디에선가 자원이 반납됨
------
Process P do {
P(S) # 열쇠가 있는지 확인후 있으면 획득하고 없으면 기다린다
critical section # 인쇄방에 들어간다
V(S) # 열쇠를 반납한다.
}
위 그림과 같이 자원을 말하는 S값에 대하여, P(S)와 V(S)라는 함수를 추상적으로 제시하여 동기화 문제에 대한 해결방안을 제시할 수 있다.
Counting Semaphore & Binary Semaphore (Mutex)
세마포어는 공유 자원에 대한 접근성을 방안을 제안하기 위해 마련된 정수 변수인데, 두 가지 방식으로 보통 사용된다.
1) Counting Semaphore
제공되는 공유 자원의 갯수를 알려주는 변수이다. 여분이 없다면 해당 자원에는 접근할 수 없게 한다.
2) Binary Semaphore (Mutex)
Mutual-Exclusion (상호배제)을 보장하기 위한 변수로, 0,1 의 TINYINT 값을 가져 Lock, Unlock 과 같은 상태 판단에 사용되는 값이다. Lock이 되어 있다면 현재 해당 자원은 접근 불가능한 상태이다.
만약 Process가 Kernel Mode 를 통해 공유 자원을 사용중에, 다른 Process가 다른 CPU를 통해 Kernel Mode를 통해 공유 자원에 접근을 한다면, 그 Process 는 현재 Critical Section 이 잠겨있기 때문에 접근하지 못하고 기다려야 한다. 그렇다면 현재 그 Process 는 Kernel Mode 의 작업을 기다리고 있으니, CPU가 도는동안 아무일도 하지 못한다. 이를 Busy-Wait, Spin-Lock Problem 이라고 한다.
Block & Wake Up (Sleep Lock)
P(S) = S.value--;
if (S.value <0){ # value가 남아있지 않았음
add this process to S.L # Waiting Queue 에 넣어놓는다.
block(this); # Waiting State 로 전환
} # wake up 시 다시 P(S) 실행되면 자원이 있으므로 if 문 안탐
V(S) = S.value++;
if(S.value == 0){ # 자원이 떨어졌던 상태였음
remove process P from S.L # 깨울 프로세스를 (선정 후) Waiting Queue에서 제거한다
wakeup(P) # wake up 하여 Ready State로 전환, CPU 대기
}
Block & Wake Up 방식이란 Spin Lock에서 지적된 효율성 문제를 해결하기 위해 고안된 방법으로, 기다려야 하는 Process는 쓸데 없이 CPU를 쓰지 않고 Waiting 상태로 전환시키는 것이다. 그리고 공유 데이터를 획득하여 작업을 진행중이던 Process 가 V연산을 마치면 기다리고 있던 애를 Ready 상태로 전환시켜 공유 자원을 사용 시키는 기법을 말한다. 해당 기법은 Process의 상태가 지속적으로 바뀌어야 하기 때문에 critical section이 짧은 경우에는 overhead가 크다.
Semaphore 를 사용함에 있어서는 Deadlock 과 Starvation 등의 문제가 있는데, 이는 앞으로 자세하게 배울 예정이다. 이 세마포어의 대표적인 문제들을 통해 세마포어가 어떻게 활용되는지 자세하게 알아보자.
(2) Process Synchronization 3대 문제
Bounded Buffer Problem (Consumer - Producer Problem)
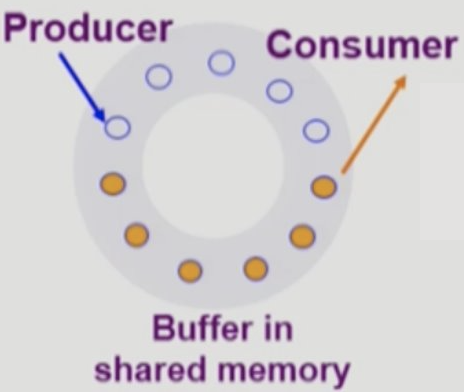
Buffer 란 데이터를 임시적으로 보관하는 장소이며, 많은 양의 데이터를 읽어올 때 CPU 가 사용하기 전에 미리 읽어 잠시 보관해두어 데이터 조회 속도가 빨라질 수 있도록 지원하는 공간을 말한다. 이런 상황에서 데이터를 읽어와서 버퍼에 저장하려는 Producer들이 있을 것이고, 필요한 데이터를 버퍼에서 꺼내가려는 Consumer들이 있기 때문에, 버퍼는 Shared Resource 로 볼 수 있다. Bounded Buffer 상황에서는 두가지 문제가 발생할 수 있는데 다음과 같다.
1) 공유 버퍼 문제 : Producer 둘이, 혹은 Consumer 둘 이상이 도착해서 동시에 저장하려하거나, 데이터를 꺼내가려 한다면 충돌 문제가 발생한다. 따라서, Buffer 접근에 대한 Lock을 걸고 진행을 해야하므로, Mutex(Binary) Sempahore 변수가 필요하다.
2) 유한 버퍼 문제 : 버퍼의 공간은 유한하므로, 버퍼 공간이 가득 찼을 때 Producer만 계속 도착한다면 공간 자원 S가 없기 때문에 소비자가 자원을 소모하기 전까지는 대기할 수밖에 없다. 이처럼 Producer 혹은 Consumer 의 자원 여부를 확인하여 사용 가능성에 대해 판단해야 하므로 Counting Semaphore 변수가 필요하다.
그렇다면 이 문제가 해결되기 위해서 Producer 와 Consumer 가 버퍼 (여기선 Critical Section)에 접근할 때 어떤식으로 접근해야하는지 살펴보자. 각 P와 V가 무슨 역할을 하는지 유념하면서 보면 될 것 같다.
* (P(empty) : 비워져 있는 공간 여부 확인 / P(full) : 채워져 있는 공간 확인)
* (V(empty) : 비워져 있는 buffer +1 / V(full) : 채워져 있는 buffer +1)
Producer (자원 = 공간) Consumer (자원 = Data)
do { do {
.... prepare x .... request y
P(empty) #Producer의 자원이 있다면 받는다 P(full) # full buffer 자원 확인
P(mutex) #Buffer을 잠그고 접근한다 P(mutex) # Buffer 잠그고 접근
.... add x to buffer .... remove y from buffer
V(mutex) V(mutex)
V(full) #Producer 자원반납, full buffer +1 V(empty) # empty buffer +1
} }
생산자는 우선 빈 버퍼가 있는지 확인하고 없으면 기다린다. 생긴다면 Buffer 접근에 대한 Lock 을 걸고 접근한다. 일을 마치면 Lock을 해제하고 내용이 Full인 Buffer를 반납하여 1증가 시킨다. 이 자원은 Consumer가 확인할 변수기도 하다.
소모자는 우선 데이터가 있는 버퍼가 있는지 확인하고 없으면 기다린다. 동일하게 Critical Section을 사용/반납하며, 내용이 Full인 buffer를 사용하여 1감소시킨다.
이와 같은 과정으로 Critical Section을 제어하고, Semaphore 을 사용한다고 보면 된다.
Reader and Writer Problem
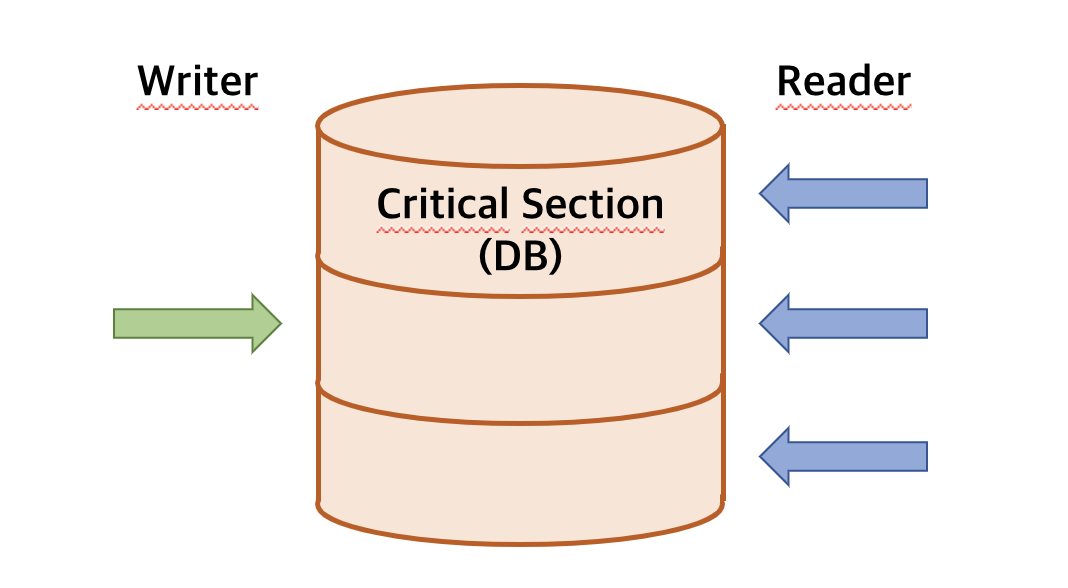
Reader and Writer 문제는 저장되는 Database 를 공유 데이터로 보고, 같은 DB에 동시에 write, read 하려는 문제를 말한다. 우선 위와 같이 문제에 대해서 접근해보면, DB는 공유데이터이므로 여러 프로세스가 접근하면 안될 것 같다. 하지만, write 는 반드시 제어가 필요하지만, read는 여럿이 동시에 해도 된다는 점이 다르다. 그렇다면 이를 Reader and Writer 각각 어떻게 세마포어로 제어를 할 수 있을까? (이 문제부터는 그림으로 하겠다...)
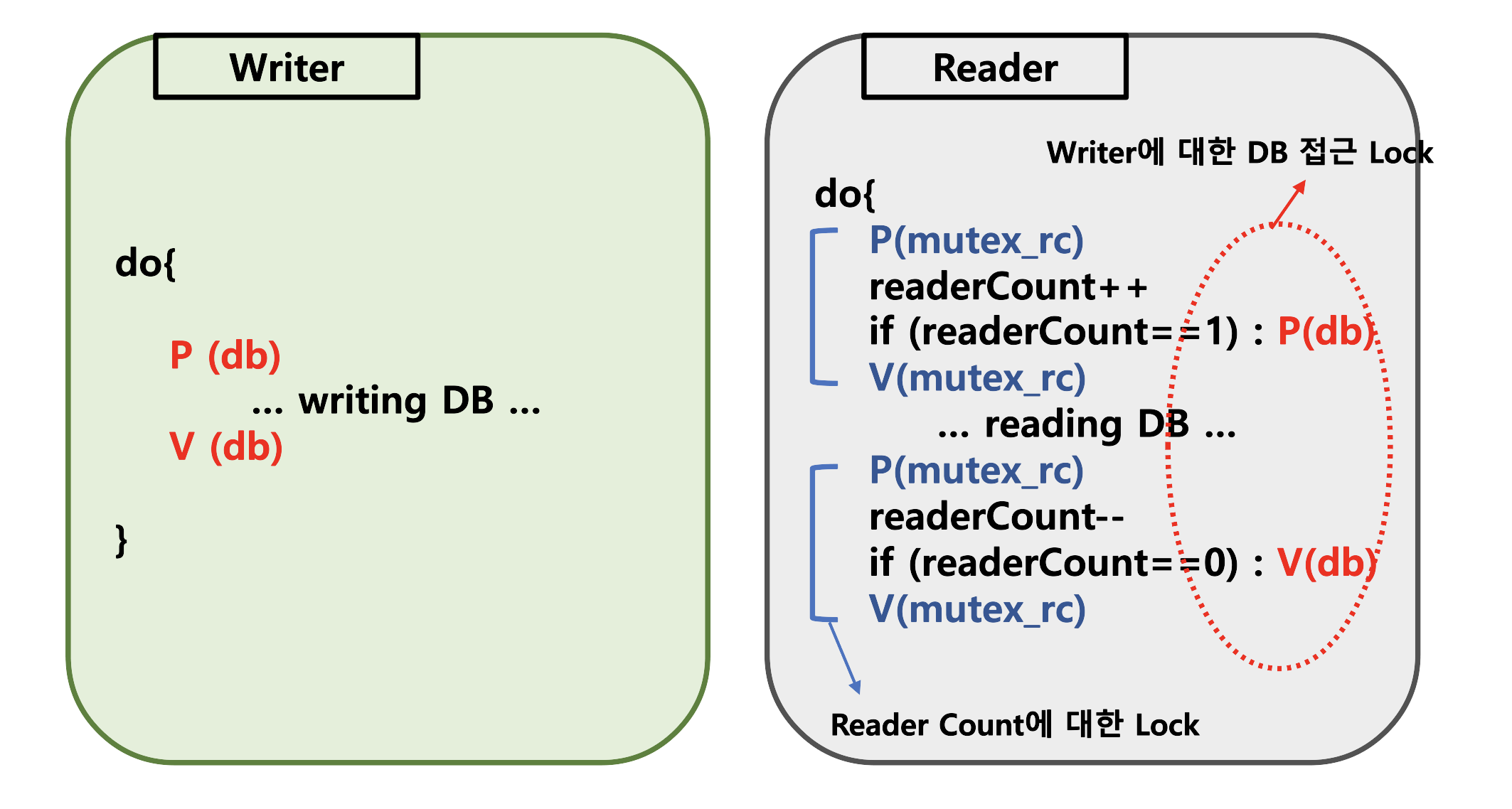
DB 같은 경우는 버퍼와는 다르게 매우 큰 저장소이기 때문에 해당 Problem에서는 무한한 저장 공간으로 가정하겠다. 즉, writing 을 하기 위한 counting semaphore는 필요하지 않다. 그러므로 Writer 같은 경우는 간단하게 DB에 저장을 하기 위해선 P(db), V(db)를 통해 접근 Lock 만 제어해주면 된다.
단, Reader 같은 경우는 여러 친구들이 같이 해도 된다는 점에서 차이가 있다. 우선 DB Lock을 걸지 않으면 Writer가 갑자기 들어와서 써버릴 수도 있기 때문에, P(db), V(db)는 필요하다. 다만 읽기 위해 제어한 Lock Mutex라면, 다른 Reader 들도 읽을 수 있도록 해볼 것이다. 모든 Reader만이 접근 가능한 Reader Count 변수를 설정할 것이다. 그리고 접근시 Reader Count++ 를 진행하면서 들어오되, Reader Count 가 1일 경우 현재 유일한 Reader 이기 때문에 Writer 를 막아줄 수 있도록 P(db)를 사용하여 Lock을 건다. 후속으로 들어오는 Reader 들은 Reader Count 값이 1일 경우 바로 그냥 DB를 읽기만 해주면 된다. (P(db), V(db)는 Writer 들만 제어하는 Lock이라고 하자)
이쯤되면 "Reader Count 역시 Reader 간의 공유변수이지 않나?"란 생각이 들 수 있을 것이다. 그 변수를 제어하기 위해서 또다른 Mutex Semaphore 인 P(mutex_rc), V(mutex_rc)를 활용하는 것이다. 위와 같이 Read Count 변수에 접근할때마다 P,V 함수를 진행해준다면, ReadCount 공유변수도 잘 통제된다고 볼 수 있을 것이다.
Semaphore의 활용되는 모습, 그리고 P(자원을 얻는 것) 와 V(자원을 반납하는 것) 함수들의 사용성에 대해서도 어느정도 감이 잡히면 된 것이다. 단, 이와 같은 경우 Reader만 계속 읽어서 starvation 문제가 발생할 수도 있다는 예외적인 상황도 있긴 하다.
Dining Philosopher Problem (Deadlock 관련)
'CS 이론 > 운영체제' 카테고리의 다른 글
| [운영체제 -6] Memory Management (1) | 2023.03.28 |
|---|---|
| [운영체제 사전 학습] 컴퓨터 시스템 구조, Interrupt 소개와 프로그램 실행 (0) | 2023.03.28 |
| [운영체제 -3] OS CPU Scheduling (0) | 2023.03.28 |
| [운영체제 -2] Process Management (0) | 2023.03.28 |
| [운영체제 -1] Process 와 Thread (0) | 2023.03.28 |