지금까지 운영체제에 대해서 배운 것들은 Interrupt, Process의 작동 방식, Process 관리 및 IPC, CPU 스케줄링, 공유자원 동기화 등에 대해서 배웠다. 첫 포스트에서 잠깐 등장한 Memory 에 대해서 더 자세히 알아보자. 우선 기억을 해야할 것은 프로그램을 execute 하는 순간 Memory 에는 해당 프로세스에 대한 주소 공간 (Address Space)이 할당되고, 이 공간에 프로세스가 필요한 정보 및 지시 사항들을 저장하며 사용한다고 했다. Memory란 무엇이고, 그 안에서 어떤 일이 일어나는 걸까?
Memory
일반적으로 운영체제 상 Memory 라고 말하면 주기억장치 (RAM)을 말하고, 이 포스트에서 다룰 내용도 RAM의 동작에 대해서 다룰 것이다. 첫 포스트에서 CPU 그리고 Disk 사이 계층에서 일을 수행하는 장치를 기억하면 될 것이다. 하지만 '기록 장치'라는 측면으로 Computer Memory에 대해서 알아보자면, CPU, Disk 모두 Computer Memory의 일부이다. 다음과 같은 Computer Memory Hierarchy를 살펴보자.
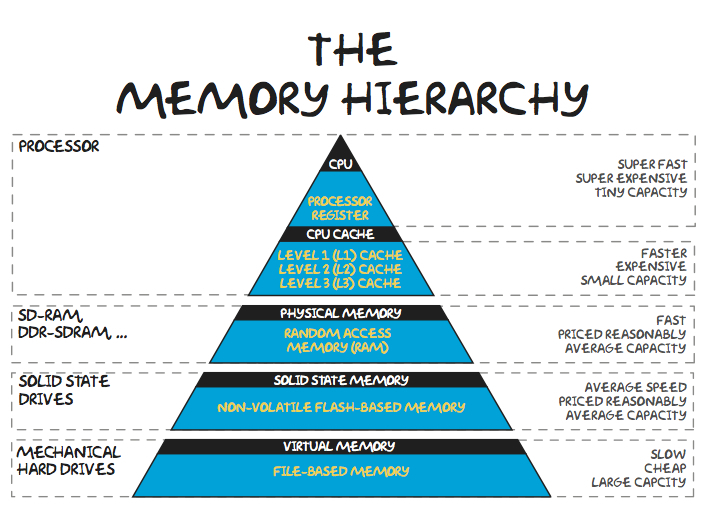
Memory 는 두가지 기준을 가지고 구분을 할 수 있는데, 바로 처리 속도와 저장 공간 규모이다. 일반적으로 저장 공간이 클수록 처리 속도는 느려지는 반비례 관계를 가지고 있고, 위 그림은 '처리 속도' 를 기준으로 위에서 부터 계층 구조를 나타낸 모습이라고 보면 된다.
지금까지 배워서 알겠지만 CPU 는 레지스터에 입력된 다음 수행을 처리하는 장치로, 비교도 안될 일 처리 속도를 가지고 있다. 저장이 목적이 아니라 현재 Process의 수행을 위한 정보들만 잠시 지나가므로 매우 적은 용량을 가지고 있고, 매우 고가이다. Cache 메모리는 CPU와 RAM 사이의 성능을 가지고 있고, RAM의 일부를 임시로 저장하고 있어서 자주 사용하거나 최근 사용중인 작업들의 처리 속도를 빠르게 로딩할 수 있도록 돕는다. (참고로 정보 요청을 Cache 메모리로 하진 않는다. RAM에서 모든 요청을 수신하고, 더 빠르게 처리될 수 있도록 저장되어 있는 곳으로 보내는 것이며, Cache에 저장해둘 수 있는 판단을 위해 많은 알고리즘을 수행한다)
일반적으로 Main Memory (주기억장치)라고 부르는 RAM(DRAM)은 CPU에 비해 현저히 느린 일 처리 속도를 가지고 있다. Execute 된 프로그램들의 상태에 대해 저장하고 있으며, 전원이 꺼지면 모든 stored 정보는 삭제된다 (휘발성, 전원을 끄면 모든 execute이 종료되는 이유).
마지막 계측으로는 Disk 라 불리는 저장소들로, SSD(Flash), HDD가 있다. 전원이 꺼지더라도 비휘발성으로 프로그램들을 모두 저장하는 Memory 들로, CPU 와 같은 Processor 들에 비해 저렴하고, '저장'을 주된 기능으로 수행한다. SSD가 HDD 보다 다소 용량이 적고 빠른 처리 속도와 낮은 전력 소모를 보여주는데, SSD는 반도체를 이용한 하드디스크라고 보면 된다.
Memory는 이와 같은 계층구조를 가지고 있다. 이 Memory 들 사이에서 컴퓨터 내 파일들을 OS가 어떻게 관여하며 관리하는지, 어떤 판단들을 해야하는지 살펴보자.
Address Binding (주소 바인딩)
(1) 개요

메모리에 있는 데이터를 조회하는 것은 항상 해당 데이터에 대한 주소를 통해 진행된다. 이 주소는 크게 두가지로 구분할 수 있는데, 바로 물리적인 주소와 논리적인 주소(Physical Address & Logical Address)이다.
예전에 첫 포스트에서 Process Execution에 대해서 잠깐 언급한 적이 있는데, 프로그램이 실행되어 프로세스가 되면 메모리에 로딩이 되어 자신만의 주소 공간을 형성하여 저장이 된다고 했었다. 해당 과정을 좀 자세히 살펴보면, Program이 실행이 되면 먼저 Program 실행에 대한 모든 정보를 토대로 주소 공간을 형성하고, 내부에 instruction 들에 대한 논리 주소(Logical Address)가 형성이 된다.
실제 Main Memory를 살펴보면 맨 아래 실제 주소에 Kernel OS가 점유하고 있고, 그 위에 실제 프로그램들이 로딩되어 올라가는 구조인데, 이 때 프로그램이 해당 Memory에 실제 어디에 있는지를 나타내는 주소가 물리적 주소(Physical Address)이다. 이렇게 로딩이 되려면 아까 실행되면서 생성한 논리 주소 공간이 물리적인 주소로 변환이 되어 어디에 저장될지 결정되어야 하는데, 이 과정을 주소 바인딩(Address Binding)이라 한다.

주소 바인딩이 되는 방식은 위 그림과 같이 3가지 방식으로 정리될 수 있다.
Compile Time Binding
컴파일이 되어 Logical Address 가 형성되는 시점에 동시에 Physical Address 까지 결정되는 방식을 말한다. 즉, 둘이 같아서 실제 주소에 Logical Address와 같은 주소로 저장이 된다. 둘이 나뉘어 지는 의미가 없으므로, 비효율적인 방식으로 알려져 있다.
Load Time Binding
컴파일이 되는 시점에 Logical Address가 형성이 되고, 그 다음 메모리 쪽으로 가서 어디 저장될지 확인하는 방식을 말한다. 예를 들어 메모리 공간을 살펴봤더니 500번지 부터 비어 있으면, Address Space 내의 0번지를 500번지부터 적재시키는 것이다. 메모리 쪽에서 빈 주소를 확인해야 하는 작업이 필요하지만, Compile Time 보다 융통성 있는 방식이다.
Execution (Run) Time Binding
Load Time Binding 시스템을 기반으로 하지만, 프로그램 실행 중에 주소 변경을 지원하는 방식이다. 프로그램이 실행되다 보면 중기 Scheduler에 의해 Swap out 되기도 하고, 다시 로딩될 때도 있는데, 이 때 이런 (프로세스 종료보다는) 간단한 Swap out이 진행될 때 원래 로딩되었던 주소 그대로 가야 하면 메모리 운영이 불편해진다. 따라서, 이런 상황에서 주소가 처음처럼 다시 세팅되어 로딩될 수 있도록 지원하는 시스템을 말한다. 융통성 있는 시스템이고 메모리 운영상 효율적이나, 주소가 언제든 바뀔 수 있으므로 CPU가 메모리를 요청할 때마다 Address 체크를 해야하는데, 이를 지원하는 H/W 장비가 바로 MMU (Memory Management Unit)이다. 그 때 그 때 주소 변환을 지원해주고, 현대 대부분의 OS가 채택하고 있는 시스템이다.
모든 데이터, instruction 들을 조회하는데는 메모리 주소가 필요하다고 했다. 이는 CPU의 수행을 위해서도 마찬가지인데, 그렇다면 CPU가 사용하는 주소는 Logical Address 일까 Physical Address 일까?
CPU는 Logical Address를 사용해서 프로그램을 운영한다
만약 프로그램이 내부 논리주소상 0번지에서 시작하고, 20번지와 30번지에 있는 데이터 a,b 를 더하라는 지시가 1번지의 지시라고 해보자. 그리고 메모리 주소로 할당 받은 주소는 500번지라고 하면, CPU는 500번지에 있는 프로그램을 실행시키면서 메모리 로딩 되어 있는 프로그램 내 0번지 부터 수행하게 된다. 이처럼 0번지에는 20번지와 30번지에 있는 데이터 a, b를 실행해야 하는데, CPU는 20번지, 30번지로 인식을 할 때 MMU에서 이를 주소 변환을 통해 520번지, 530번지에 있는 데이터를 조회하여 준다. 이처럼 주소 변환 로직을 통해서 상대적으로 해당 데이터 및 instruction 들을 CPU가 Logical Address를 통해서 가져올 수 있는 것이다. (Logical Address 주소에 대한 요청이 MMU 장치를 통과하며 주소 변환이 이루어지고, Physical Address 로 변환하여 데이터를 읽는다)
================= 정리 중
(2) Memory Management Unit (MMU)
MMU란 위에서 설명하였듯이, 주소 변환을 지원해주는 HW Unit 장치이고, 내부적으로 레지스터 들을 통해 동작한다. 간단한 Scheme을 통해 MMU의 동작 원리를 살펴보자.
17분 그림
CPU > 346번지의 내용을 달라 (Logical) > 주소변환 필요 > MMU 가 필요 > 레지스터 두개 (relocation(base) register, limit register 두개를 사용해서 주소 변환을 하게 됨)
(MMU 가 해주는 간단한 주소 변환 Scheme)
P1의 주소공간에서 0번지 -> 346번지 만큼 떨어져 있는 그 내용을 말함.
물리적인 메모리 공간 14000번지에 올라가 있음. -> 똑같이 346만큼 떨어져 있음. 14346번지 주소일 것임.
이와 같이 단순히 더하는 거임 ㅋㅋ (Relocation Register : 해당 Process 의 메모리가 시작되는 주소를 저장해놓음:14000번지), 논리적인 주소 (346번지를 Reloca. 에 더하면, 찾고있는 주소가 나옴).
Limit Register > 프로그램의 크기가 있음. P1은 0~3000번지까지 가지고 있음. 이 Process의 크기를 가지고 있음.
> 악의적인 프로그램이라 3000번지임에도 불구하고, 메모리 4000번지에 있는 내용을 달라 한다면, 다른 메모리 공간에 있는 내용을 달라하는 것. 주면 안됨 (남의 프로그램 메모리를 볼려고 하는 악의적인 시도).
(22분 그림)
Limit Register 를 먼저 확인. No 면 Trap 이 발생 OS에게 CPU 를 넘어가게 됨 (Interrupt 발생. 이유 확인) > Process에 대한 조치 실행
Yes 면 Relocational Register 확인 ㅇㅇ.
---- 사용자 프로그램과 CPU는 Logical Address만 다룬다. Physical Address 볼 필요도, 알 필요도 없음.
-------------------------
필요한 용어들
Dynamic Loading : 메모리에 동적으로 올린다? 그 때 그 때 필요할 때마다, 해당 루틴이 불려질 때마다 메모리에 올리는 것. 프로그램 전체를 올려놓는게 아니라 루틴? 을 그 때 그 때 올린다.
> 프로그램 내에서도 자주 불리는 것, 자주 안불리는 것이 구분된다. (ex: Error Handling Routine). 비효율성을 개선.
> Paging 이란 memory 관리 기법인데, 이거랑은 다른거임. 이건 OS가 하는거임. dynamic Loading 은 사용자가 직접 구현하는 것. (쉽게 할 수 있도록 OS Library 가 지원되긴 함)
OVerlay: 메모리에 실제 필요한 정보만을 올려놓는 것. (뭐가 다름?) > 역사적으로 다르대. Overlay 는 워낙 메모리가 작기 때문에, 하나 자체를 올려놓는게 불가능했음. 따라서 이쪽 부분을 올려놓고, 다음에 다른 부분을 올려놓도록 수작업 했음. (Manual Overlay). 운영체제의 지원이 없음 (지원 측면에 따라 Dynamic Loading 과는 다름)
Swapping : 메모리에서 디스크로 쫓아 냄. (어디로? BackingStore, Swap Area 로) swap out / in 이라고 부름. 중기 Scheduler 가 Swapper 라고 불렀었던거 기억. CPU 우선 순위가 낮은 것들을 쫓아내곤 함 (낮은 Priority) .
> Compile Time, Load Time Binding 일 경우, 원래 swap out 시에는 저장되었던 곳으로 저장이 되어야 함. (왜 그래야 하는지?? ㅠㅠ)
> 더 효율적으로 사용되려면 RunTime Bindng 이 좋긴 함 (빈 영역 아무 곳에나 올릴 수 있음)
> Paging 에서 쓰는 Swap out 이랑은 범위 측면에서 조금 다르고, 원래 프로그램이 다 쫓겨나는게 원래 Swap out 의 의미.
(kill 과 swap 은 다른 것인가??????)
Dynamic Linking
static Linking: 여러 군데에 존재하던 컴파일된 파일들을 묶어서 하나의 파일을 만드는 과정. (라이브러리가 프로그램의 실행 파일 코드에 포함됨) print 가 import 되어 실행 파일에 같이 묶여 있음.
Dynamic Linking : 라이브러리가 별도의 File로 존재하고, 호출하는 곳에 도달하면 라이브러리 루틴의 위치를 찾기 위한 stub이라는 작은 코드를 실행. 그 Lib이 어디에 있는지 찾으려고 함. 그 Lib가 어디에 있는지 도달하면 찾음. 메모리 효율성 올라감.
Dynamic Linking 하는 Library 들 :Shared Library, (window에서 Dll)
printf 가 실행파일 안에 포함이 되어 있으려면, 내 프로그램 주소 공간 안에서 실행이 됨. 100개 넘는 프로그램이 다 각각 printf 가 있으면, 메모리 효율성이 매우 낮아짐. printf 가 어디에 있는지 지정이 되어 있으면 프로그램이 실행될 때 그걸로 실행.
-----------------------------
Physical Memory 관리
낮은 주소 부분에 OS가 항상 상주. 높은 주소 부분에는 사용자 프로그램의 영역
1. Contiguous Allocation
> 프로그램이 올라갈 때 통째로 올라감. 주소 변환도 비교적 간단함.
2. Non-Contiguous Allocation (현대 시스템)
> 프로그램을 구성하는 주소 공간을 잘게 쪼개서, 일부는 저쪽, 일부는 이쪽에 올라가 있음.
> Page 단위로 메모리 여기저기로 쪼개는 것을 Paging 기법이라고 부른다.
--------
Contiguous Allocation (45분 ~)
* 고정분할 방식
> 프로그램이 들어갈 사용자 메모리 영역을 미리 Partition 으로 나누어 놓는다.
> ex : 47분 그림. 미리 나뉘어져 있음. 프로그램 A> 분할 1. 프로그램B >분할3 (분할2에는 못들어감) >>> 그러면 분할2느 남는 조각으로 형성. (외부 조각: 올리려는 프로그램보다 분할의 크기가 너무 작음 // 내부 조각: 프로그램의 크기가 분할의 크기보다 작아서 남는 공간 (프로그램에게 할당된 공간이지만 남았음))
> 융통성이 없음
* 가변 분할 방식
> 미리 나눠놓지 않는 것
> 프로그램이 실행될 때마다 차곡차곡 올려 놓음.
> 프로그램 B가 끝나면, 그 공간이 빈 공간이 됨. (가변 분할을 쓰더라도 외부조각이 발생, 내부는 안생김)
> 빈공간 =hole. 이 hole 들이 여기저기 산발적으로 생김. 운영체제는 어느 부분이 사용되고 있고 hole 인지를 지속 판단하고 있어야함. (누가 왔을 때 hole 에 넣기 위함)
---------
**** 자꾸 안으로 들어가서 좀 머리 아픈데...
가변 분할 방식에서 size n 인 요청을 만족하는 가장 적절한 Hole 을 찾는 문제 ! : OS가 찾아야 함!
적어도 n 보단 hole 이 커야함.
1) First Fit -> n 보다 큰 제일 처음 발견되는 hole 넣기
2) Best Fit -> 다 살펴본 다음에 프로그램 크기와 가장 가까운(크지만) 홀에 넣기 (Hole 탐색 부담 존재)
3) Worst Fit -> 가장 큰 Hole 에 할당. 역시 모든 Hole 탐색. (왜 방법이라 하는지 모르겠음)
hole 들을 묶는 것, 사용중인 메모리를 한쪽으로 밀어놓는 것
compaction >> 큰 Hole 만들기 >> external fragmentation 해결 방법 중 한가지 >> Memory 영역을 건드리기 때문에, 비용이 매우 큼. 전체 프로그램 binidng 과 연계된 문제. 차피 우리는 non-contiguous 씀.
------------------------
Non Contiguous (불연속 할당)
Paging 기법 / Segmentation 기법
Paging 기법 : 프로그램의 주소 공간을 같은 크기의 Page로 자르는 것.
(실제 Memory 도 짤라놓음. Page가 들어갈 수 있도록! Page Frame 이라고 부름)
Paging 기법 > Hole 들의 불균형 이런 문제가 발생하지 않음. > Page Frame 이 비어있기 때문에 size 안맞는 문제는 없음
>> 단점 : 주소 변환이 복잡해짐 (단순 덧셈으로 진행될 수 없음)
Segmentation 기법 : 프로그램의 주소 공간을 다 같지 않은, 의미 있는 크기로 잘라놓는 것.
> Code / Data / Stack 각각 Segement 로 잘라가지고, 각 Segement 별로 각각 다른 memory 위치에 할당될 수 있게 하는 것
> 의미있는 Segement 이기 때문에 3개 내부적으로도 더 자를 수 있음. (불균일한 크기 문제가있긴 함)
----------------------- 이제 더 구체적으로 배울 예정.
===========================================
Paging 기법 (단순한 MMU 알고로 주소 바인딩 불가)
프로그램을 구성하는 논리적인 메모리를 동일한 크기로 잘라 놓음 > 실제 메모리도 특정 크기 (page frame 이라 부름) 로 잘라 놓음
페이지 테이블이라는 것을 통해서 주소 바인딩 필요
페이지 테이블 > 각각의 논리적인 페이지들이 실제 메모리에 어디에 올라가있는가를 매핑해주는 테이블.
페이지 갯수만큼 패이지 테이블 엔트리 (index) 가 존재
6분대의 그림
CPU가 논리 주소르 줌. ->> 페이지 테이블로 가서 page 번호 (p), offset (그 페이지 내에서 얼만큼 떨어져 있는지) -> p 번호를 조회하면 f의 frame 번호를 가질 수 있음 --> 물리적인 frame 주소로 변환이 됨 (page 번호 -> frame 번호)
페이지 테이블 >> 각 프로그램마다 별도로 존재해야함 (용량이 꽤 있음) > 캐시 메모리에 들어가기에도 용량이 꽤 있음. > 그래서 이걸 Memory 에 넣게 됨.
> 메모리 접근하기 ㅜ이해서 주소변환 필요 > 주소변환 하려면 페이지 테이블 필요 > 페이지 테이블 위해서 메모리 접근 필요 >>>>>>>>> 메모리를 총 2번 접근해야 함을 알자.
> 두 개의 레지스터의 사용 기법
PTBR 레지스터 (Base-REgister) - 메모리 상에 페이지 테이블이 어디에 있는지 가지고 있음.
PTLR (Length-Register ) - 페이지 테이블의 길이를 가지고 있음. (테이블 크기) (limit Register)
> 두 번의 메모리 접근은 overhead가 큼. 속도 향상을 위해 associative register (TLB: Translation Look-aside Buffer) 라는 H/W 사용 (일종의 캐시).
> 14분 그림. Page Table 은 메모리 안에 있음.
> 메인 메모리 위에는 캐시 메모리가 있음. (CPU 는 모름) > 운영 데이터 상 많이 접근하는 데이터를 캐시 메모리에 보관해서 접근 속도가 빠르게 됨. 이런것처럼 주소 변환을 위한 별도의 캐시를 두고 있는데 TLB가 있음(주소 변환 보조가 목적).
> TLB를 통해 주소변환이 이루어짐 _> 물리 메모리 접근 (메모리 1번 접근) TLB에 없으면 메모리 두번 접근 필요. (빈번히 접근되는 메모리만 TLB)
> TLB는 내부 전체를 서치 해서 Page 를 검색해야 함.(전체 서칭에 시간 overhead 존재)
>>> 따라서 벼렬적 서칭이 가능한 parrellel search 지원 (Associative Register 의 역할) . 쫙 서치를 해서 p 를 조회할 수 있고. 없으면 TLB Miss 임.
(TLB에서 서칭하는 방식이랑 Page Table 에서 서칭하는 방식이랑 목적, 방식이 다른데, 그 차이점을 잘 알아둬야 한다!)
>>>> Page Table 은 프로세스 마다 존재. TLB도 프로세스 마다 다른 정보임. 따라서 HW인 TLB에 있는 정보는 Context Switch 가 발생할때 Flush 시켜서 비워내야함.
-----------------------------------------------
실제 TLB 접근 시간
TLB 접근 시간 = a
메모리 접근 시간 1
1>a
TLB로 부터 주소변환 정보가 찾아지는 비율 (B)
B 비율 만큼은 (1+a) >> TLB 접근시간 + 메모리 접근 시간
B 실패 비율 만큼은 (2+a) >> TLB 접근해봤는데 없었음 = a + 메모리 접근을 해야하므로 = 1 + 데이터 접근을 위한 메모리접근 = 1
결과 >> Effective Access Time (EAT) = 비율별 종합 = 2+a - B >> Page Table 만 있을 때 2 보다는 훨씬 작은 값!! (a는 매우 작을 것이기 때문)
TLB 데이터 빠르게 한다!
============================
2단계 페이지 테이블
1e단의 페이지 테이블이였다가 -> 두개의 페이지 테이블이 된다.
outer - page table 도 존재.
왜? (보통 컴퓨터의 목적은 속도 향상, 용량 줄이기임)
> 일단 속도가 줄지는 않을 것임. 시간은 더 걸림
> Page Table 을 위한 공간이 줄어들기 떄문
현대 페이지 테이블은 주소 공간이 매우 큰 편.
32 bit address 사용 . 요즘은 64 bit address 사용.
논리 주소가 32 bit 로 구성된다면, 한 프로그램의 크기가 얼만큼까지 가능한가?? > 2^32 까지 위치구분이 가능함.
2^10 = K 라고 함. 2 ^20 = M 라고 함. 2^30 = G 라고 함.
32 bit 주소 체계는 약 4G (각 프로그램이 가질 수 있는 최대 메모리 크기) > 32 bit 주소 체계를 쓰기 때문.
4G 를 4KB page 로 나누면 1M 개의 page 갯수가 얻어짐. page Table의 엔트리가 1M개가 필요. > 이 테이블은 메모리에 들어가게 되는 것이고, 각 프로그램마다 테이블ㅇ 따로 있는데, 그러면 메모리에 차지하는 공간이 너무 커짐.
방금거에서 더 ex) 각 엔트리당 4 byte 일 경우 1M개일 경우 4MB의 page table 필요. 그러나, 대부분의 프로그램은 4GB의 주소 공간 중 극히 일부만 많이 사용함. Page Table 4MB 의 많은 공간을 낭비하는 것.
그래서 등장하는 것이 2단계 페이지 테이블
offset 은 똑같이 있고, page number 가 두개로 나뉘어짐. (주소 체계를 하나 더 둔다)
(35분)
P1, P2, D >> 바깥쪽 Page 에서 index를 찾는게 P1 (안쪽 Table을 Point 함) >> 안쪽 테이블의 페이지 번호 P2로 index로 찾음. 그러면 그 page frame 을 또 찾게 됨. 그럼 d(offset) 만큼 떨어진 곳에서 또 데이터를 찾음.
(상당히 비슷한 방식)
안쪽 테이블 크기 = page frame 의 크기와 똑같음. 안쪽 페이지 테이블은 테이블 자체가 페이지화 되어서 메모리 어딘가에 들어가 있게 되는 것. frame 하나의 크기가 4KB라고 했기 때문에 안쪽 테이블 하나의 크기가 4KB
보통, page table 엔트리 하나의 크기가 4B 임. 엔트리 갯수는 보통 몇 개가 나올까? 4KB에서 4B짜리 엔트리 몇 개가 나올까? = 1K 개 가능.
32비트의 주소 체계에서 offset 은 몇 비트, 각 page number는 몇 비트여야 할까??
page 하나의 크기는 4KB라고 했음. 4KB = 2 ^12 Byte.
ex) 10진수 구분일 경우, 100 개의 가구를 구분하려면 몇 자리가 필요할까? -> 0번지 ~ 99번지 = 두자리 수
10000개는? -> 0번지~ 9999번지 = 네자리가 필요
2^12 Byte 를 구분하기 위해서 (2지수로) > 12Bit,12 자리가 필요.
(따라서 Page 안에서 Byte 단위로 얼마나 떨어져있는지 구분하는 ofsset 을 위해서는 12 bit 로 떨어져 나가는 것)
그럼 남은건 20 bit
안쪽 페이지 테이블은 페이지 화 되어서 들어간다. 각 엔트리는 4B, 1K개의 엔트리가 있음.
안쪽 테이블 넘버인 p2 는 (42분대의 그림과 같이, 그냥 위에서부터 몇번째에 있는지 나타내는 거임) 근데 총이 1K개 있음.
그러니까 1K개의 위치를 구분하기 위해서 (1K = 2^10) >> 따라서 구분하기 위해서 10 비트가 필요
(서로 공평하게 10비트씩 나눠갖는게 아님!!)
자연스래 나머지 p1을위한 공간은 10비트임.
============================================
64 비트일 경우, 똑같이 생각해서, 정리를 해보기! (서로 다른 N 개의 정보를 위해서는 몇개의 방이 필요한지에 대해 생각하는 것) ( 이 기회의 bit, byte 등의 자료 형도 완벽하게 이해하자)
=============================================
2단계 페이징 사용하는 이유 : 공간 절약을 위함 (시간 loss)
> 공간을 절약하는거 맞음???? 이라느 질문 가능
> 1단계 : 주소 공간 중에서 사용되지 않는게 많음 > page table 에서 안사용된다고 엔트리를 안만들 수도 없음. (멕시멈 로지컬 메모리의 크기만큼 만들어줘야 하기 때문)
> 2단계에서는 해소됨 : outer table 은 전체 논리적인 메모리 크기만큼 만들어 지지만, 안쪽 테이블은 잘 안되는 데ㅐ이터에 대해서는 안만들어져서 outer table 이 null 을 가르키고 있음. (그냥 상당히 안사용되는 공간들에 대해서 안쪽 테이블 안마들어짐 > 매우 절약됨 > 안사용되는 영역이 생각보다 엄청 많다는 얘기기도 함.
=============================================
좀 더 많은 다단계 페이지 테이블 사용 가능 ( Multi-level Paging)
> 용량은 줄일 수 있긴 함
> but 모든 페이지 테이블이 다 메모리단에 존재하므로 메모리 접근이 table이 늘어나는 만큼 증가하게 됨.
> TLB를 사용하면 접근 시간을 많이 줄일 수 있긴 함.
> 다단계 페이지 테이블을 사용하더라도 TLB를 통한다면 그렇게 엄청 오래걸리는건 아니다.
(시간 계산 예제)
--------------------------------------
Valid / Invalid (V/I) Bit in Page Table
Logical Memory 에 있는 페이지 갯수만큼 페이지 테이블 엔트리가 존재. 그 엔트리에는 물리적 메모리 어디에 올라가 있는지 정보가 있음. 사실 주소정보만 저장되어 있는게 아니고 부가적인 비트가 엔트리마다 같이 저장.
V,I Bit
Logical Memory 에 있는 페이지 갯수만큼 페이지 테이블 엔트리가 존재해야하기 때문에, 프로그램에서 많이 사용되지 않는 정보들도 똑같이 페이지 테이블이 분할되어 엔트리를 만들어놨음. (인덱스 접근으로 진행되기 때문)
사용되지 않을 때 Invalid Bit 으로 저장되어 있음.
Valid > 해당 페이지 엔트리에 가면, 실제 0번 페이지가 2번 frame에 올라와 있음 등을 뜻함. 해당 frame #에 맞게 이동하면 실제 그 데이터가 있다는 뜻.
invalid > 이 페이지가 사용되지 않음. 프로세스가 아예 그 주소를 사용하지 않거나, 그 페이지가 물리적인 메모리에 올라와있지 않고 disk backing store에 있음.
Protection Bit in Page Table
> 권한 같은건 아님
> 어떤 연산에 대한 접근 권한을 가지고 있는지를 나타냄.
---------------------------------------------------
Inverted PAge Table
> 문제 : 용량이 너무 큼. 메모리 공간을 너무 많이 차지함. (강제적인 엔트리 갯수)
13분 그림.
원래는 페이지 테이블이 프로세스 마다 존재.
INV에선 > Page Table 은 딱 1개 존재 . 전체 시스템에서 1개 존재.
> Page Table의 엔트리가 프로세스의 Page 갯수만ㅋ틈 존재하는게 아니고 물리적인 메모리의 frame 만큼 존재함.
> 주소 변환 : 위에서 부터 index 만큼 이동하는 과정을 했음 (Inv 에서는 이게 불가능함)
>> Logical memory pid(존재하는 프로세스들중 어떤 프로세스인지 {page table이 1개기 때문}) / p(pid 프로세스의 몇 번 페이지인지) / d 의 주소를 가짐. Page Table의 인덱스에 대한 정보가 없으므로, Table의 Value 값에서 p값을 가지는 index를 찾아야 함 (배열의 역할을 제대로 수행하지 못함) >> 그러면 떨어진 만큼이 f 면, 실제 메모리에서도 f 만큼 떨어져 있는 것. >> 물리적인 주소를 f/d 로 형성 후 조회한다.
>> 쓰는 이유 : 페이지 테이블을 위한 공간을 많이 줄일 수 있음.
>> 단점 : 시간적인 overhead가 매우큼. 공간 줄이겠다고 일일이 다 검색하는것임.
조치 : associative register H/W 를 통해서 병렬적인 검색을 진행하면 시간 overhead 를 줄일 수 있음.
-------------------------------------------------------------------------------------
Shared Page (Re-entrant, Pure Code)
프로그램을 구성하는 페이지들 중에는 다른 프로세스들하고 공유할 수 있는 페이지들이 있음.
21분 그림.
P1 P2 P3 프로세스와 페이지테이블들이 있음.
이 프로세스들이 같은 코드를 가지고 돌아간다. EX) 한글 프로그램으로 세개를 돌리고 있으면, 코드 부분은 세개의 프로세스가 똑같은걸 써도 됨. data 부분만 바뀌는거이기 때문.
> 각각을 물리적 메모리에 올리는게 아니라 1 copy 만 물리적인 메모리에 올림.
> 각 프로세스의 page table 같은 부분을 가르킴. (그림상 ed1.ed2.ed3 가 같으니, 3,4,6 번을 동일하게 가르킴)
>> 여러 프로세스가 공유할 수 있는 코드 부분을 동일한 물리적 메모리 주소로 매핑해줄 수 있는 기능.
>> read-only 로 세팅. 별도로 가져야 하는 것들은 독자적으로 메모리에 올림.
>> 2가지 조건 만족 필요 1) read-only 여야 하는 페이지ㅕ야 함 2) Logical address 상에서도 동일해야함. 즉 떨어진 index 만큼이 같아야 함
**** IPC와는 다름. 프로세스 간의 통신을 위해 공유 공간에 매핑을 해놓고 이러는건 같은데., 한친구가 그걸 읽고 다른 친구는 쓰고 하는 communication 목적임 **** 이런 shared 기법과는 다른게 아예 모두 read-only 목적이기 때문.
========================================================================
========================================================================
Segmentation 기법
> 주소 공간을 의미 단위로 쪼갠 것 (code, data, stack, heap 등)
주소 변환은 페이징과 비슷한 점이 있음.
Logical Address --> <segment Number, offset(세그먼트 안에서 얼마나 떨어져 있는지>
각 세그먼트 별로 주소 변환을 해야해서 세그먼트 테이블을 두고 있음.
각 테이블은 두개의 레지스터
STBR > 세그먼트 테이블의 시작위치를 나타냄.
STLR> 프로그램이 사용하는 세그먼트의 갯수
31번 Segement 기법 주소 변환
CPUI > 논리 주소를 주게 되면, Segement 번호와 offset으로 나눈다. > base register가 가지고 있는 segment table 시작위치로 이동 > segment 번호를 탐색해서 해당 segment로 이동. > 해당 테이블에 실제 메모리에 그 세그먼트가 얼만큼 떨어져 있는지 가지고 있음 > 해당 segement 에서 offset 정보를 활용해 Logical Address 상 가르키고 있는 실제 data를 확인해서 가져온다.
> 페이징 기법에서는 페이지 크기가 다 동일했음. 글치만 세그멘테이션 기법은 의미 단위로 자르는것이기 때문에 세그먼트 단위가 다 다름. 따라서 세그먼트의 길이가 얼만지 세그먼트 테이블에 가지고 있음.
>> 논리주소 상 세그먼트 번호 < STLR 인지 우선 확인
>> 또한 세그먼트의 크기가 1000바이트인데., offset 이 해당 세그먼트의 범위를 넘어간다? trap 확인. (세그먼트 길이보다 offset이 크지는 않은가?)
(33분 그림상 trap error flow가 두가지로 수신되는 이유)
>> 페이징과의 차이
>페이징은 offset의 크기가 페이지 테이블 크기로 정의됨. (넘을 일이 없다고 함)
>segemntation 에서는 offset이 정확히 어디에 있는지 byte 만큼 떨어진 위치를 가야함.
페이징에서는 #로 표현.
> 페이징에서는 segmenttable 크기가 바로바로 정해져 있음. Segment 기법에서는 그냥 프로세스가 사용하는 세그먼트 갯수 만큼 엔트리가 나뉘어지게 됨.
>> 세그먼트도 사용되지 않는 hole 들이 생김.
>> 크기가 균일하지 못하기 때문에 first fit, best fit 등의 기법을 써야함. (allocation 상의 문제 발생)
>> 의미단위로 일을 하는데에는 segmentation 이 훨씬 효과적. ex) 보안상 read / write /execution 등에 대한 의미 부여
>>>> 어쨌든 페이징은 공간을 매우 많이 차지한다는 점에서 많이 불리한듯?
---------------------------------------------------------
FM 4강
10분 시간대 보면서 Segementation 예제 확인하면 될듯. (segmentable 의 형성된 예시)
12분
세그먼트를 서로다른 두개의 프로세스가 공유하는 모습.
각각 프로세스가 2개의 세그먼트가 있는데 그 중 0번 세그먼트는 코드를 담고 있는 세그먼트 == 즉 두 프로세스상 같은 역할을 함. 같은 논리상의 주소에 있고, read-only 이므로 Shared Page 로 분류할 수 있음. (조건이 PAging 에서와 차이는 없음)
================ 출저
1. Memory Hierarchy
https://computerscience.chemeketa.edu/cs160Reader/ComputerArchitecture/MemoryHeirarchy.html
'CS 이론 > 운영체제' 카테고리의 다른 글
| [운영체제 사전 학습] 컴퓨터 시스템 구조, Interrupt 소개와 프로그램 실행 (0) | 2023.03.28 |
|---|---|
| [운영체제 -4] Process Synchronization(병행 제어)과 Semaphore (0) | 2023.03.28 |
| [운영체제 -3] OS CPU Scheduling (0) | 2023.03.28 |
| [운영체제 -2] Process Management (0) | 2023.03.28 |
| [운영체제 -1] Process 와 Thread (0) | 2023.03.28 |



