<230강 - Kinesis Overview >
> Kinesis 는 시험에서 매우 중요한 부분, 꽤 깊이 알아야 하는 부분
>스트리밍 데이터를 collect / process / analyze 하는데 도움을 줌
> Log, Metric(여러 지표), Clickstream, IoT data 등등..
> 구성하는 4가지가 있음
>> Kinesis Data Streams :: 데이터 스트림을 입력 / 처리 / 저장 (매우 깊이 들어감)
>> Kinesis Data Firehose :: AWS 내부 / 오뷔의 데이터 스토어로 데이터 스트림들을 로딩한다
>> -- Analytics :: SQL / Apache Flink 를 사용해 데이터 스트림을 분석할 수 있다
>> Kinesis Video Streams (시험범윈 아님) :: Video Stream 을 입력 / 처리 / 저장
<231강 - Kinesis Data Stream 개요>

> KDS :: 너의 시스템에 빅 데이터를 Streaming 하는 방법이다.
> KDS 는 여러개의 번호가 매겨진 [Shard] 로 구성된다 (1,2,3,... N)
> 샤드는 사전에 프로비저닝 되어 있어야 하고, 모든 샤드에 걸쳐 데이터가 분할됨 / 샤드가 현재 Stream Capacity 를 정의한다 : 수집/소비율로 알아서 계산하는 듯
> Producer 가 있음. (여러 형태로) : KDS 에 데이터를 보내는 측
>> Application, Client, SDK, KPL(Kinesis Producer Library), Kinesis Agent 등등
>> 이 모든 Producer 들은 공통적인 일을 하는데, SDK를 사용하여 KDS 레코드를 생성한다
> Producer 가 생산하는 Record 는 두가지로 구성되는데, Partition Key 그리고 최대 1MB 값을 가지는 데이터 블롭 이다.
> Partition Key 는 해당 레코드가 어떤 샤드로 가야하는지 알려주고, Blob 은 데이터 그 자체.
>> 샤드당 약 1MB /sec (1000 msg / sec) 정도의 속도를 제공, 6개 샤드가 있으면 6MB / sec 로 데이터를 보낼 수 있다
> Consumer 가 있음. 역시 다양한 형태 : Apps (KCL- Kinesis Consumer Lib, SDK에 의존하는 형태 등), Lambda 함수, KDF(Firehose), KDA(Analytics)
> 레코드를 받는데, 다음과 같이 구성됨. Partition Key, Sequence No (어떤 샤드에 있었는지에 대한 정보), Data Blob
>> 역시 소비 처리량이 있는데, 향상된 소비자 모드 (팬모드) 를 활성화 하면 consumer 마다 2MB/sec 으로 훨씬 빠른 속도 보장
> 설정할 수 있는 속성들을 보자
>> Retention : 하루 ~1년 / 기본적으로 데이터를 재처리 , Replay 할 수 있다
>> Kinesis 에 데이터가 입력되면, 삭제될 수 없다 (immutability)
>> KDS 로 메세지를 보내면, 파티션 키가 추가되는데, 같은 파티션 키를 공유하는 Data 들은 같은 샤드로 가게되고, 이 Key 를 기반으로 Order 된다 (Ordering)
>> 제작자는 AWS SDK, KPL, Kinesis Agent 등을 사용해서 Record 를 형성해 Data 를 전송할 수 있다
>> 소비자는 직접 소비자를 만드는 방식인 - KCL, AWS SDK 사용 앱과 // AWS Manage 가 지원되는 Lambda, KDF, KDA 와 같은 방식이 있다.
<Capacity Modes>
> Provisioned Mode
>> 몇 개의 프로비전된 샤드를 몇 개 선택하고, API 를 사용해 수동으로 스케일링 할 수 있다
>> 각 샤드는 1MB/s 의 속도 (위에서 나왔듯)
>> 각 샤드는 2MB/s 의 속도로 나간다 (enhanced 설정도 있음)
>> 시간당 샤드 프로비저닝 비용이 나감 - 잘 예측해야함
> On-Demand Mode
>> 용량을 미리 프로비저닝 하거나 관리할 필요가 없음
>> 용량이 수요에 맞춰 알아서 조정된다 (기본은 용량은 4MB/s IN)
>> 지난 30일간 피크 처리량을 기반으로 오토 스케일링을 수행한다
>> 요금 모델이 다른데, 시간당 스트리밍 되는 비용 * Data 가 in/out 되는 GB 양에 따라
> 정리 : 용량 예측이 어려우면 OD 모드, 용량에 대한 기획이 어느정도 가능하다면 프로비전
<Security>
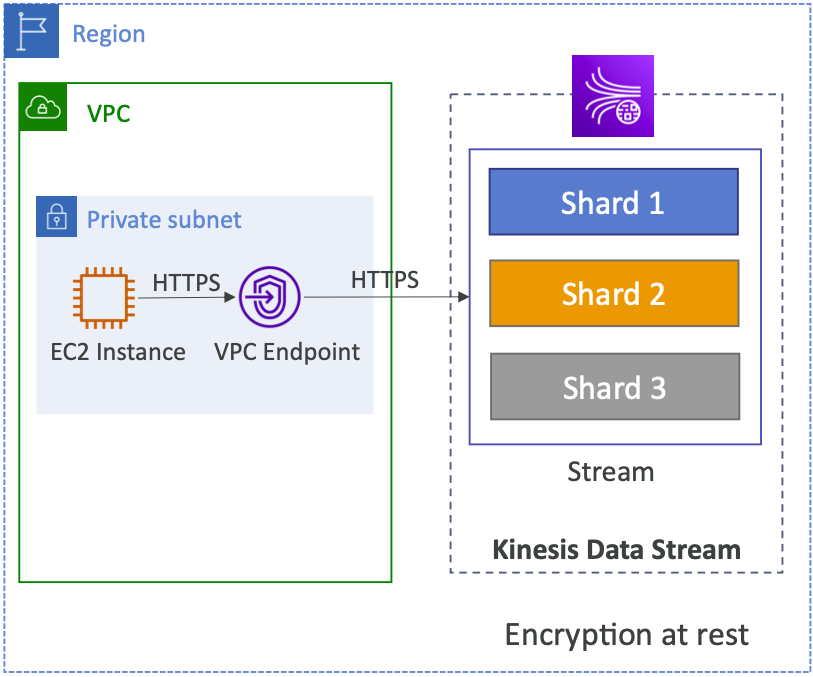
> KDS 는 Region 내에서 배포 대상이 됨
> Control Access / Authorization using IAM Policy
> Encryption
>> In-flight using HTTPS End Point (전송중 암호화)
>> At Rest using KMS (저장시 암호화)
>> Client side encryption (클라이언트가 알아서 암호화 / 복호화를 함)
> (뭔소린지 모르겠으나) VPC Endpoint 도 Kinesis 에게 제공될 수 있다 (????)
>> 인터넷을 거치지 않고 Private 망을 통해 (EC2 Instance -> VPC Endpoint -> KDS)
> API 호출은 CloudTrail 을 통해 모두 Monitoring 될 수 있다 (CloudWatch, Cloud Trail 뭐가 다를가?)
<232 강 Kinesis Producer >
> KDS 에 데이터 레코드를 보내는 역할
>> 레코드 구성 > Seq Numb (샤드 내 파티션 키마다 고유 - 소비자에서 보통 사용) / 파티션 키 (데이터 넣을 때 필수) / Data Blob (데이터
> Producer 종류
>> AWS SDK : 간단한 생성자를 만들기 위해 사용가능
>> KPL : C++, Java 등의 언어를 지원하고, 이것들은 SDK 위에 구축된다 > Bath 처리, Compression 압축, Retries (재시도) 와 같은 고급 API 사용 가능
>> Kinesis Agent : KPL 위에 구축되는 구조를 가지고 있고, Log 파일들을 모니터링하고, KDS 에 이들을 스트리밍 할 때 사용
> 데이터 KDS 에 보내는 API 는 PutRecrd API 라고 부른다
> KPL 이 기본적으로 해주는 부분이지만, PutRecord API 를 Batching 으로 사용하면 비용을 절갑하고 처리량을 증가시킬 수 있따

> 정규 처리량을 기준으로 데이터를 보낸다
> 데이터 Producing 을 할건데, 파티션 키를 Device 의 고유 ID 로 지정
> Hash Function 으로 이동 / 파티션 키의 입력을 받아, 어떤 샤드로 데이터를 보낼지 출력해준다. (같은 파티션 키를 공유하는 모든 데이터는 같은 샤드로 보내진다)
> 이 Device ID 를 PK 로 보내는 레코드들은 모두 샤드 1 로 이동할 것이다
> 다른 Device ID 가 Produce 하면, 똑같은 hashFunction 에 입력으로 들어가는데, 다른 샤드로 보내게 된다. (입력으로 들어가는 Partition Key 가 다른 Device ID 값이기 때문)
Risk 1> 한 Device 가 너무 폭주하면, 샤드가 가득찰 수 있다
Risk 2> 또한, "Hot Partition" 현상을 방지하기 위해 잘 분배되어 구조화된 Partition Key 를 사용해야 한다 >> 한 샤드의 처리량이 다른 샤드에 비해 너무 많아지는 불균형 현상 발발 가능
>> Partition Key 로 사용할 수 있는 잘 분배된 값을 잘 생각해야함 (가령, 웹 브라우저 이름이 파티션 키라면, Chrome 담당 샤드가 ㅈㄴ 혼자 힘들어 할 것) > 다음에 나오는 에러와 관련
<ProvisionedThroughputExceeded>

> 1MB /sec or 1000 records / sec 로 Message 생산 처리가 되고 있으면 ㄱㅊ음
> 이걸 넘어서기 시작하면 이 예외가 발생한다 (프로비저닝된 처리량을 초과했기 때문)
> Solution (시험에 나올 수 있음)
>> 잘 분산된 파티션 키를 활용하는 것 (그렇지 않았다면, 이 현상은 자주 발생할 것이다)
>> Exponential Backoff (기하급수적 백오프?) 를 통해 Retries 를 구현하여 예외를 재시도하도록 처리하는 것
>> Shard Splitting (샤드 스케일링) > 샤드를 분할하여 처리량을 증가 (나중에 다룬다) > 샤드 자체의 숫자를 늘려서 일단 발생하는 처리량 예외를 해결하는 것
-------
<233강 - Kinesis Consumer >
> Stream 으로 부터 레코드를 수신하고 처리한다.
> AWS Lambda, KDA, KDF< SDK 를 사용한 앱, KCL (Client Librarary) - 간편화해주는 라이브러리
<Classic (Shared) Fan-out Consumer vs Enhanced Fan-out Consumer >

> 전자 방식 : 2MB/sec per shard acrsoss all consumer
> 소비자가 GetREcords API 를 활용해서 가져오는데, 이 3,4개의 소비자들이 다 합쳐서 샤드의 2MB/sec 처리량을 공유한다 (3개면 약 666KB 데이터 처리량)
>> 소비자 수에 제한이 가해질 수 있음, 소비자가 많아질수록 소비자당 처리량은 느려짐 (정해진 처리량 서로서로 나눔)
> Pull 모델로, 소비하는 앱이 적을경우 유용, 비용 절감에 효과적
> 또한 한 샤드는 초당 최대 5개의 GetRecords API 를 처리할 수 있다는 제한도 있다
> 소비자들이 GetRecords API 를 활용해 직접 Poll Data 를 하고, 최대 10MB. 최대 10000개의 레코드 수신
----
> 후자 방식 : 샤드 내 컨슈머당 2MB/sec 를 지원받음
> 소비자가 이번엔 SubscribeToShard API 를 활용해서 레코드를 호출하는데, 이는 샤드와 앱당 2MB/sec 처리량을 보장해준다
> 두번 째 소비자, 세번째 소비자가 동일하게 요청해도, 모두 각각 2MB/sec 처리량을 지원받는다 (각자 높은거 보장)
> Push 모델로, 여러 소비자들이 필요할 때 유용한다
> 지연시간은 훨씬 짧음, Kinesis 에서 직접 데이터를 push 해주기 때문이다 (훨씬 비싼 기능임)
> Http/2 라는 스트리밍 방식을 사용하여 데이터가 푸시된다
> 기본적으로 KDS 에는 5개의 소비자 앱만 등록 가능하다는 제약이 있다..? (뭐임...)
<람다와의 연동>

> 서버를 이용하지 않고 Record 데이터를 소비할 수 있는 방법 (서버리스 메커니즘 활용)
> 여기서 소비자의 역할을 가진 람다함수는 Record 를 수신후 처리하여 DynamoDB 에 저장하는 것을 담당
> 람다 함수는 KDS 에 GetBatch API 를 호출한다. Partition Key 별로 나뉘어서 각각 람다 함수에 분배되어 Record 가 들어감 (아마 각자 다른 Shard 에게 요청하라는 Key 를 사용할 것? 그게 파티션키?)
> 위에서 말한 두 소비자 모드 둘다 지원함
<KDS의 Batch 방식>
> 배치 방식으로 레코드를 읽고, 배치 사이즈, 배치 window (영역) 은 구성에서 설정할 수 있음
> 에러가 발생하면, 람다는 성공할 때까지 retry 하다가, data expire 이 발생한다
> 한 샤드에 동시에 10개의 Batch 처리를 요청할 수 있다
> 좀 전체적으로 .... 아직 잘 모르겠다 이런 느낌!!
<234 강 KDS 실습>
> 싼 리소스는 아닌듯? 샤드당 사용량 시간당 있고, PUT Payload 하는 가격청구도 있음
> 모드는 두가지 중 선택할 수 있다
>> OnDemand (용량 생각 안해도 됨, 알아서 스케일링함) ,
>> Provisioned (샤드를 같이 프로비저닝 할 수 있고, 필요 샤드 예측을 할 수 있음) > 이걸로 샤드 1개만 프로비전 함
> 애플리케이션 탭

>> 1 생산자
>>> 추천 옵션 3가지, K-Agent, SDK (간단한 앱 개발, Java AWS SDK 사용 가능), KPL (이건 조금더 고차원으로 사용할 때, API 를 조금 더 세밀하게 사용

>> 2 소비자
>>> KDA, KDF, KCL
> 모니터링 탭
>> 현재 처리되고 있는, put / read 되고 있는 레코드의 갯수를 보여줌
> Configuration 탭
>> 샤드 스케일링 가능, 태그 지정 가능
> Enhanced-fanout 탭
>> 향상된 팬아웃을 사용할 소비자 지정 가능
> Producer 사용을 위해 CLI 를 사용할 거임, aws에서 사용하는 CLI 를 열었다 (Cloud Shell) (간단한 생성자 / 소비자 실습)
$ aws --version 으로 설치되었는지 확인, version 2 확인
$ aws kinesis put-record --stream-name DemoStream --partition-key user1 --data "user signup" --cli-binary-format raw-in-base64-out 명령어로 KDS 에 데이터를 넣어보자 (Put Record API 활용)
(참고로 CloudShell 은 현재 너가 접속한 계정의 IAM 권한을 상속받아 사용하게 된다)

{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49654239004340659526808176394838549442454334785221296130"
}
> 성공적으로 저장되었다는 응답을 확인할 수 있다. 한번 더해보면
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49654239004340659526808176394840967294093568372897742850"
}
> 다른 Seq Numb 로 응답을 수신한다
> 아까 모니터링 탭으로 이동해서 보면, Put Record 가 표시되는 것을 확인할 수 있다.

>이번엔 소비자 측을 CLI 로 해보자
$ aws kinesis describe-stream --stream-name DemoStream - 우선 스트림 이름을 통해 어떤 스트림인지 정보를 확인해볼 수 있다
>> 내가 가지고 있는 하나의 샤드 (위에 Id 있는 그거) 를 볼 수 있고, ARN, 이름, 상태 등등을 알 수 있다
>> 참고로 CLI SDK 를 이렇게 사용하면, 필요시 샤드 ID 를 직접 지정하면서 사용해야 한다 (KCL 를 사용하면 라이브러리에서 처리된다)
$ aws kinesis get-shard-iterator --stream-name DemoStream --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON
>> 샤드 ID 지정되는 것을 알 수 있음 / 반복자 유형 TRIM_HORIZON : 스트림의 처음부터 읽는다는 뜻, 가장 처음 전송된 레코드를 읽음 (CLI 연 이후부터의 레코드 읽는 TYPE 도 있음)

{
"ShardIterator": "AAAAAAAAAAE3ZCEFVuG7D5n6gK4rk/63vrBG9HmdUklknsUebP+Xq0HKn5GsLOjwh4F8HsrBE5rTq+IiKF6kI9nGADnDtNLltA4wLIOT2+1VJ8p2L1DYEGXHaSZ6Vo2xqy1oJ8WiH4QymjRuyTBpDpPruUOTkHeJr4vfNQReOoqFgcM1YU/bWcMYHldkeVUld+D6CCJqyuYtcCCED29UUdeHpvNgVHm09/WnIAH3fiJDkmhiqUT2ow=="
}
>> 응답으로 Shard Iterator 를 알려준다 - 이는 레코드를 소비할 때 지속 사용할 수 있다 (지점부터 다시 소비 가능)
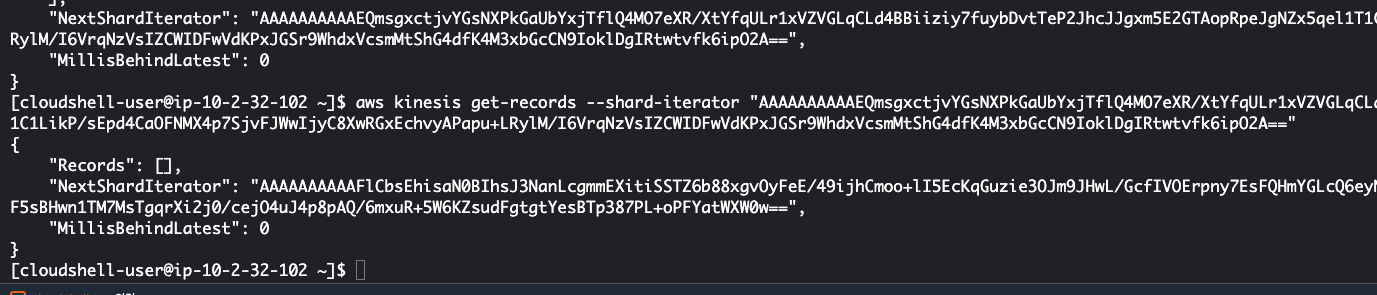
$ aws kinesis get-records --shard-iterator "{SHRAD_ITERATOR_TOKEN}" - 이 명령어로 위 샤드 이터레이터를 지정하여 레코드를 받아올 수 있다

>> 이렇게 Low-Level 로 CLI SDK 를 활용하면서 소비를 한다면 당연히 Classic Shared 모델을 사용한다. (Enhanced 아님), KCL 을 활용하면 훨씬 고수준의 API 로 연동 가능하다고 함
>> NextShardIterator 가 있는데, 다음에 호출할 때는 이 토큰을 사용해야 샤드가 멈춘 곳에서부터 다시 가져올 수 있다 (아니면 처음부터 다시 가져옴) - KCL 같은 API 사용할때도 이건 동일하다
>> 참고로 300초 뒤에 사용해보면 샤드 iterator 가 만료되었다고 안내됨
>> 처음 받은 샤드 iterator 를 그대로 불러오면 똑같은 데이터를 가져와준다 (즉, 샤드 이터레이터는 인덱스 처럼 그 부분 읽어주는 거인듯, 다음 iterator index 를 사용해야 할 듯)
---------------------
<235강 KCL>
> KDS 로부터 레코드를 읽을 때 도와주는 Java Library. (분산 환경에서 유용)
> 각 샤드는 한개의 KCL 인스턴스로 읽을 수 있다. (N 샤드 = maximum N KCL instance) // 시험에는 이정도로 충분함\
(KCL 만 말하는거임? 아니면 다른 컨슈머들도 포함해서 KCL 이라고 하는거임..?)
> KCL 은 KDS 로부터 읽는데, 얼마나 읽었는지는 DynamoDB 에 체크포인트로 저장한다 (KCL 을 실행하는 앱은 Dynamo DB 에 접근 권한이 필요하다) -> KCL 컨슈머를 말하는듯?
> 이 Dynamo DB 로 공유 데이터 덕분에 앱에서는 다른 작업자들의 진행도 추적하고, 샤드에 걸쳐 작업을 공유할 수 있음
> KCL 앱은 EC2, Beanstalk, On-Premise 등 어디에서 되고 ㅣㅆ을 수 있다
> KCL 버전 >> v1 은 Shared Consumer // v2 는 shared & enhanced consumer 모두 지원

> 동일한 KCL 앱이 KDS 로부터 데이터를 읽을 수 있고, Dynamo DB 덕분에 작업을 공유할 수 있다
> 1번 KCL 은 샤드 1, 2 로 부터 읽을 것이고 (위에서 본 것처럼 읽을 때 어떤 샤드로 읽을지 지정 가능) / 2번은 3,4 번으로 부터 읽는다
> 소비자들이 KDS 를 읽은 진행 현황은 Dynamo DB 에 기록됨. (하나의 앱이 다운되면, 다른 앱이 읽은 지점부터 다시 읽는 것을 재개할 수 있다)
-----
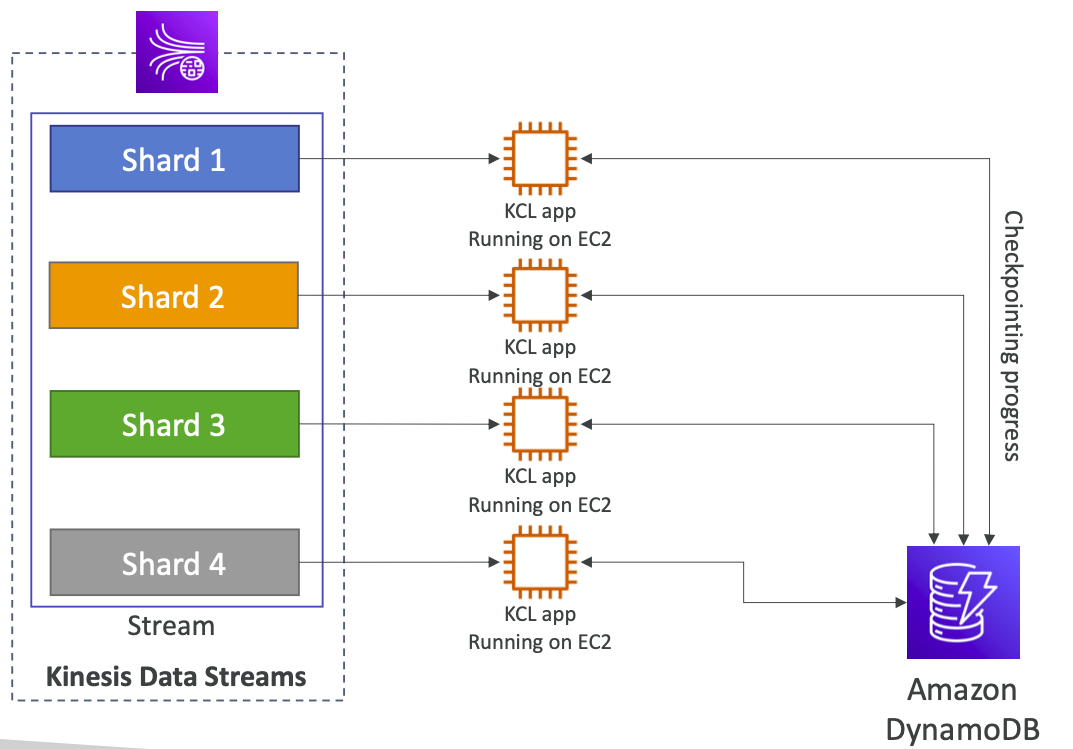
> 4개의 인스턴스로 늘어나도, 각각 샤드가 얼마까지 읽혔는지 DB로 체킹이 가능해서, 배정된 EC2 들이 이전 부분부터 다시 작업할 수 있다
> 참고로 언급되었듯이, 샤드 갯수를 넘어선 KCL 앱이 생길 수는 없다 (아무 것도 안하는 앱이 존재하기 때문, 둘은 1:1 관계로 읽히는게 Max)
> 샤드가 늘어나도, Dynamo DB 와 작업하여, KCL 앱과 샤드간의 작업을 분할한다
---------------------
<236강 Kinesis Operation>
<Shard Splitting>
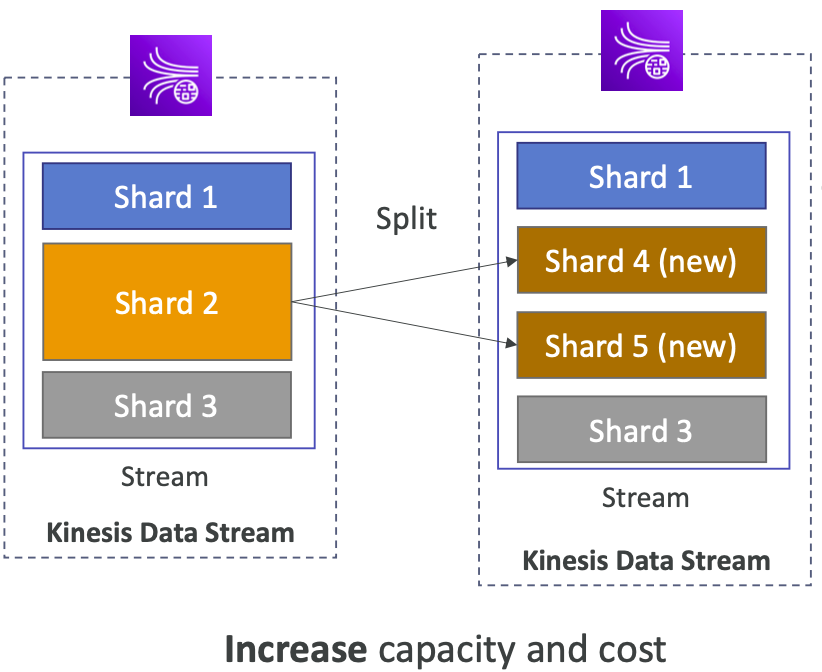
> 더 많은 샤드를 갖고, 스트림의 용량 (Stream 의 용량임!) 을 늘릴 때 사용된다 -> 처리량을 높이는? (1MB/s data per shard 가 증가함)
> Hot Shard 를 divide 하고 싶을 때 사용 가능하다
>> 예시처럼 과부화된 샤드를 분리하면 3MB/s 에서 4MB/s 로 처리량이 증가한다
> 스트림에 몇 개의 샤드가 있는지로 KDS 가격이 책정되기 때문에 가격 또한 증가함 (그냥 샤드 늘리는거아님? 쪼갬으로서 반이 되는 어떤게 하나도 없어보이는데..?)
> Old Shard 는 Write Closed 된다 (그림상 더이상 Shard 2 가 존재하지 않는다) > Old Data 는 Retention Period 에 따라 삭제된다 (그 다음에야 샤드가 삭제된다)
> KDS 를 오토 스케일링 할 수 있는 솔루션 아키텍트는 존재하지만, KDS 에서 지원해주는 Auto Scaling 기능이 있는건 아니다
> 한 동작으로 2개 이상의 샤드로 분리할 수 없다 (샤드 분할을 여러번 해야 함)
<Merging Shard>

> 필요 이상이기 때문에 Stream Capacity 를 감소시키고 싶음 (비용 인하)
> 트래픽이 적은 두 개의 샤드 (Cold Shards) 를 Grouping 할 수 있다
>> 예시 그림처럼, Shard1 + Shard4 -> Shard 6 가 됨 (Split 처럼 ID 는 새로 부여받는다)
> Old Shard 들은 역시 Write Closed 되고, 만료 기간에 따라 데이터가 삭제된다
> 역시 한번에 두 개 이상의 샤드를 병합할 수는 없음
---------------------
<237강 - Kinesis Data Firehose>

> 생상자로부터 데이터를 가져옴 (KDS 에서 봤던 모든 생성자 가능) + KDS 역시 Producer 가능, CloudWatch, AWS IoT (이렇게 더 가능) --> 일반적으로 KDS 에서 데이터 가져오는 구조가 많음
> Firehose 는 람다 함수를 이용해 (필요할 경우) 데이터 가공도 할 수 있다
> 데이터가 선택적으로 가공되면, Destination 쪽으로 Batch Write 된다
> 코드를 작성하지 않고도 도착지에 데이터를 쓴다 (KDF 가 데이터 쓰는 법을 인지하고 있기 때문)
> 도착지에는 3가지 종류가 있다
>> AWS 리소스 도착지들 (외워야함 , 여러번 강조함) -- S3 (데이터를 S3에 쓸 수 있음), Redshift (Wearhousing DB(??), 사용하기 위해 먼저 S3에 데이터를 쓰고 KDF 가 RS 로 복사명령을 내린다), AWS ElasticSearch (Open Search)
>> 3rd Party Partner > Datadog, splunk, New Relic, Mongo DB 등으로 데이터를 쏴줄 수 있다 (점차 증가한다)
>> HTTP 엔드포인트가 있는 자체 API 가 있다면, Custom 정착지로 보낼 수 있음 (백엔드 앱에 쏴주고 그러는거임)
> 데이터를 모든 도착지에 보내면 이후에 두가지를 수행할 수 있다
>> 모든 데이터를 S3 버킷에 보내 백업한다 (Backup S3 Bucket)
>> 도착지에 쓰기 실패한 데이터만 S3 버킷에 저장한다 (Failed S3 Bucket)
<요약>
> KDF 는 Fully Managed Service 이며, admin 기능이 따로 없고, 오토 스케일링되며, 서버리스이다 (위에 말했던 도착지 종류 다 외워두기)
> Firehose 를 통과한 데이터에 대해서만 지불한다 (가격적으로도 합리적인 모델이라고 함)
> Near Real Time!! (Firehose 에서 배치로 도착지에 write 하기 때문 - 완전 전체 배칭이 아닌경우 최소 60 초 가량의 대기 시간 필요)
>> 최소 32MB 의 데이터를 모을 때까지 기다려야 함
> 다양한 데이터 포멧, 변환, 압축을 지원
> Custom Data 변환이 필요하면 AWS 람다를 활용해서 Firehose 에 얹을 수 있다
< 자주 나오는 질문 : KDS vs KDF (어떻게 다르고, 언제 누굴 써야 하는가?)>

-- KDS
> KDS 는 데이터를 대규모로 수집하는 스트리밍 서비스이다
> Custom Code (Produce r/ Consumer) 를 해야 함
> Real Time!! (~200ms)
> 프로비저닝한 용량만큼 돈을 지불한다
> 스케일링을 직접 할 수 있다
> 1~365 일까지 데이터 적재 지원
> replay 기능 지원
--- KDF
> 데이터를 위에서 말한 도착지로 주입해주는 injestion service 이다
> Fully Manaed (no server to manage),
> Near Real Time!! (Buffer time min 60 sec) >> 시험에서 중요한 부분
> 자동 스케일링 해준다 (KDF 를 거친 것에 대해서만 지불한다)
> KDF 에서는 데이터 Storage 해주지 않고, replay 해주지도 않는다!!
<238 강 - KDF 실습>
> Delivery Stream 클릭 (현재 Firehose 스트림 생성), KDF 의 동작 방식 도식화되어 보여줌
> KDS 를 소스로 하고, S3 를 도착지로 설정한다 (여기서 대상이 될 수 있는 AWS 리소스 / 3rd 파티 / custom http 등을 확인할 수 있다)
> KDS 를 선택하고, 전송 스트림 이름은 생성된대로 사용
> 이후 레코드 Transform / Convert 영역이 있다 (필요시 Custom 변환 하는 곳)
> 람다 리소스를 사용해서 transform / filter / un-compress / convert / process 데이터를 진행할 수 있다
>> KDF 가 데이터 쏘기 전에 Data 로 할 수 있는일 아무거나 할 수 있다
>> enable 시 만들어둔 Lambda 함수를 선택해야 한다
> 레코드 형식 자체를 변환해줄 수도 있음 (그냥 이런 기능도 있다만 알고만 있으면 됨)
> 다음은 Destination 설정, S3 버킷 위치 설정 / 동적 파티셔닝 원하는지 설정 / S3 prefix 설정 / 오류 접두사 지정 등에 대해서 (S3에서 할 수 있었던 것들) 지정할 수 있다
< 그아래 보이는 버퍼 힌트 / Compression / Encryption >

> Buffer Hint (설정 공간)
>> 버퍼는 KDF 에서 대상에게 쏘기 전에 레코드를 축적하는 방법
>> 기본적으로 5MB 설정 (효율적으로 하려면 크게 하면 됨, 근데 Real Time 능력이 감소하겠지)
>> 꼭 차지 않더라도, 아래 설정에 Buffer Interval 에 도달하면 Flushing 이 되긴 한다
(두가지가 같이 동작, 둘 중 하나에 먼저 도달하면 Flush)
> Compression & Encryption
>> 레코드 대상으로 압축 가능, 압축 확장자 설정(S3 같은 곳에 저장하기 전에 압축 가능)
>> Encrypt Yes / No 설정
<그 아래 보이는 Advanced Setting>

> Permission : 특정 이름으로 IAM Role 을 만들어 주는데, 이 Role 은 S3 에 쓰기 위해서 (지금 도착지가 S3 이니까 그거에 맞춰 커스텀 설정 해주는 거임) 필요한 모든 권한을 가지고 있음
>> KDF 가 대상 버킷에게 쓰고, 또한, KDS 로부터 읽어올 수 있는 방법
------
> 암튼 그렇게 KDS 를 소스로 하고 S3 를 도착지로 하는 KDF 를 만듬
> KDS 에 데이터를 더 보내기로 한다 (KDF 가 연계된 뒤에는 새로 KDS 에 보내는 것들만 읽나봄) - 위에 한거는 안보내짐
> 아까 배웠던 명령어들로 KDS 에 1 개의 데이터를 더 보냈다. S3 를 확인해보니 바로 안와있는데, FH 는 버퍼가 존재하기 때문
> 이제 들어갔으니 KDF 가 자동으로 인지하고 버퍼에 쌓아둘 것임.


>> 나도 5분뒤 확인해보니 잘 전송 받은 모습 확인된다. KDF 짱짱맨
> 강의에서는 partition by date 가 되어서 전달된 데이터들이 저장되어있음
Q: partition by date 는 FH 에서 기본인가? 아니면 나왔었나? - ANW: 아까 도착지 설정 S3 에서 확인해보면, [S3 버킷 접두사] 에서 보면 기본 접두사가 yyyy/mm/dd//hh 라고 적혀 있음. 이걸 오버라이딩 하고 싶으면 하라는 설정이였음
> 열어보면, 전달한 데이터가 하나로 묶인 txt 파일이 열린다!! (KDF 가 잘 동작함)
>> 흠.. 좀 애매하긴 한데.. 대충 이해는 가는 수준..
-------------------------------- 마지막 Kinesis
<239강 Kinesis Analytics>
> 두 개의 종류가 있는데, SQL 앱에 대한 것, Apache Flink 를 위한 것

> SQL 앱
>> Data Source 로부터 읽을 수 있는데, KDS, KDF 로부터 읽을 수 잇다
>> Real-Time Analytics 를 위해 SQL Statements 를 추가할 수 있다 & S3 버켓으로 부터 참조 데이터를 가지고 오는 것도 가능
>> Sinks 로 보낼 수 있는데, 1차 카테고리는 다시 KDS 와 KDF 이다
>> 즉, KDA 를 활용한 실시간 데이터 분석을 스트리밍할 수 있고, 아니면 직접 데이터를 Batch Inject 해줄 수 있다
>> 각각 배운 용도대로 이어서 활용할 수 있는 것 (Lambda, App, S3, Redshift, ...)
> KDF 와 유사하게,
>> Fully Managed Service, No servers to Provision 이며,
>> Automatic Scaling 을 지원하고, 실제 KDA 를 사용하는 양에 따라 과금된다
>> Use Case :: Time-series 분석 / Real-Time 대시보드 / Real-Time 지표 등

> Apache Flink
>> Apache Flink 를 사용할 때, Java / Scala / SQL 등을 이용해 앱을 만들어 스트리밍되는 데이터를 처리 및 분석할 수 있다
>> 다른점: Flink 라는 점이 다른 점임 (코드로 작성되어야 하는 앱, 단순 SQL 보다 훨씬 강력, 고급 쿼리 처리 가능)
>> Flink 앱은 KDA 전용 클러스터에서 백그라운드로 실행되는 것이 지원된다
>> KDS, MSK 로부터 데이터를 읽을 수 있다
>> 그냥 Flink 자체가 데이터 분석을 위한 앱인듯? 그리고 이 앱 자체를 AWS 클러스터로 운영할 수 있다는 점이 중요한 포인트인듯
>> 이 서비스를 통해 자원 계산에 대한 프로비저닝 가능, 병렬 계산, Automatic Scaling 가능
>> checkpoint, snapsho 등으로 앱을 백업할 수 있다
>> KDF 로 부터는 읽을 수 없다. KDF 에 대한 실시간 데이터 분석이 필요하면 SQL 버전을 사용해야 함
> 내가 아직 "데이터 분석" 이라는 영역이 좀 추상적이라 그런지, 잘 모르겠음
--------------------------------
<240강 Kinesis 와 SQS 의 FIFO 데이터 정렬에 대하여 >

> 100 개의 트럭이 있고, 각자 트럭 ID 가 부여되어 있다고 해보자. 그리고 AWS 에게 GPS 위치를 계속 보낸다
> 데이터를 순서대로 처리하고 싶음. 각 트럭의 이동을 정확하게 파악하기 위함. 어떻게 전달해야 할까?
>> Partition Key 를 사용해야 하고, 여기서 적합한 Partition Key 는 Truck Id 이다
> 동일한 파티션 키를 사용하면, 항상 동일한 샤드로 전달될 것이기 때문.
> KDS 에서 배웠듯이, Truck Id 1(Partition Key) 를 가지고, Hash Function 을 통과시킨다 (계산을 하게 된다). 이 Hash 를 통해 Shard 1 로 보내야 함을 알고, 그리로 보낸다
> 같은 방식으로 2번은 2에게 보내게 된다고 하자.
> 3을 해시한 결과 Partition Key 3은 Shard 1 으로 보낸다고 한다. (샤드 3으로 꼭 가야하는건 당연히 아님. 샤드 수가 제한되어 있는데)
>> 중요한 것은 각 파티션 키는 특정 샤드에 배치를 동일하게 받게 되고, 데이터 소스는 지속적으로 동일한 파티션 키를 전달하므로, 동일하 샤드에 배치받는 다는게 중요.
> Shard 1 은 항상 트럭 1,3 번의 데이터, Shard 2 는 항상 2,5 번의 데이터, Shard 3 는 항상 4번의 데이터만 받게 됨
> Each Truck Data 는 Shard Level 에서 항상 In Order 된 상태로 꺼낼 수 있을 것이다
> 아까 예시대로 100개의 트럭, Shard 5 개라면, 각 샤드는 평균 20개의 트럭을 담당하게 될 것임.
>> 단, 샤드와 트럭(데이터 소스) 사이에 직접적인 연결이 있는 것이 아니라, Kinesis 가 Hash 를 통해 판단한 결과대로 전달됨
> 이번엔 SQS 를 살펴보자
> SQS FIFO 는 FIFO 방식 정렬을 지원한다. 이 때, Group Id 를 사용하지 않으면, 모든 메세지는 (내부적으로 분할 없이) FIFO 방식대로 처리되고, 오직 하나의 Consumer 만 사용할 수 있다. (Group ID 를 사용하지 않아도 1:1 은 확정이였군!)
> 따라서 Consumer 숫자를 스케일링하고, 연관된 메세지를 그룹화하고 싶을 때, Group ID 를 사용하는 것이라고 배웠다. (생각해보면, 이것이 Partition Key 와 매우 유사하다는 것을 알 수 있다)

> Consumer 1 이 Group ID A 의 Data 들을 FIFO 대로 제공받을 수 있고, Consumer 2 가 Group ID B 의 Data 들을 제공받는다
> Group ID 가 많을 수록 소비자도 많아진다는 것을 우린 이미 배웠음
> kinesis 와 모델링 자체가 다르다는 것을 느낄 수 있다.
<Kinesis 와 SQS 모델링 차이>
> 다시 100개의 트럭 모델로 들어오고, 5개의 KDS 샤드, 1개의 SQS FIFO 가 있다고 해보자.
> KDS
>> 해싱 덕분에 한 샤드는 평균적으로 20개의 트럭 데이터를 담당하게 될 것이다.
>> 트럭 데이터는 각 샤드 내에서만 순서대로 정렬된다
>> 샤드마다 소비자가 존재하기 때문에, 최대 5개의 소비자만 제공할 수 있다
>> 이런 경우, 5개 합쳐서 최대 5MB/s of data 의 처리량을 제공받을 수 있다 (꽤 높은 편)
> SQS FIFO
>> 대기열 자체는 하나 밖에 없어요!
>> 100개의 트럭이므로 100개의 그룹 ID 를 만들 수 있다
>> 이럴 경우, 최대 100개의 소비자를 만들 수 있다 (따라서, 초당 300개의 message/sec 처리량을 가질 수 있다)
> 소비 / 생산 /정렬 모델의 차이점이 있음
> Use Case 에 따라 적절한 모델은 당연히 달라지며, SQS FIFO 는 Group ID 숫자에 따른 dynamic 소비자 수를 원할 때 적합. KDS 는 정말 많은 10000000대의 데이터가 전송되고 있으며, 샤드당 데이터 정렬이 필요할 때. (약간, Kinesis 가 훨씬 더 큰 범위처럼 느껴짐. SQS 자체가 샤드인 느낌. 하지만 SQS FIFO 처럼 Group ID 분할은 안됨. 샤드라는 더 큰 채널을 제공하는 느낌)
--------------------------------
<241강 SQS vs SNS vs Kinesis >

> SQS
>> SQS 는 소비자가 "pull data" 하는 모델, 직접 대기열에서 삭제까지 해야함
>> Producer / Worker 에 제한이 없다. 모두 같은 Queue 를 사용하기 때문
>> SQS FIFO 를 사용해야 순서를 보장받는다
>> 각 메세지에 지연 기능 (delay) 있어서, 대기열에 원하는 시간 이후에 등장하도록 설정 가능 (세부적인 기능들은 각각에서 충분히 다룸)
> SNS
>> Pub/ Sub 모델임을 기억!!~!
>> 구독자에게 메세지를 push 하는 구조임. Topic 당 최대 1250만명 구독자 가능. (topic 자체는 10만개)
>> Data 한 번 push 하면 persist 하지 않음! (재전송 안된다)
>> SQS 와 결합한 Fan-out 모델을 굉장히 많이 사용한다
> KDS
>> 표준 모델은 "Pull Data" 모델이며, 샤드당 2MB/s 의 처리량
>> 상향 Fan-out 모델은 "Push Data" 모델이며 (KDS 가 푸시해줌) , 소비자당 2MB/s 처리량 (훨씬 비쌈)
>> Data 는 설정한 만료기간 이후에 삭제되며, 그 때까지 보존되기 때문에 Replay 가 가능하다 (아까 Iterator 등으로!)
>> Real-Time Big Data, Analytics & ETL 에 자주 사용된다
>> KDS 에 (on-demand 아니라면) 원하는 샤드를 프로비저닝 해야하고, Shard-Level 에서 FIFO 정렬을 지원한다
>> On demand 는 KDS 에 저장되는 데이터 양에 따라 알아서 샤드가 프로비저닝 된다 (이걸 구체적으로 막 조회하고 이러는건 안배운게 맞음. 우린 직접 프로비저닝하고, Shard ID 를 직접 넣어서 실습함. 사실 Partition Key 를 통해 분할되는 것도 실습하진 않았음)
<섹션 19 : SQS/SNS/Kinesis 퀴즈퀴즈>
1. 소비자가 특정 시간 이후에 보게 하는 Message Delay 존재 (기본 0분, 최대 15분)
2. 각 소비자가 한번에 10개의 메세지 폴링, 1분 동안 처리. 다른 소비자가 동일한 SQS 두 번 이상 처리. 어떻게 해결??
> 이거 뜻이 다 처리 후 DELETE 요청을 못보냈다는 뜻 > 처리 시간 증가 요청 필요
> 해설: Visibility Timeout에서 메시지는 Queues에서 소비된 후에만 숨겨집니다. 표시 시간 초과를 늘리면 소비자가 메시지를 처리하고 메시지의 중복 읽기를 방지하는 데 더 많은 시간을 할애할 수 있습니다. (기본값: 30초, 최소: 0초, 최대: 12시간)
3. SQS Queue 를 처리하는 ASG EC2 인스턴스 집합 존재. 두번 처리된 메세지 많이 발견, 성공적으로 처리 못함. Fail Queue 로!
> 해설: SQS 배달 못한 편지 Queues은 다른 SQS Queues(소스 Queues)이 성공적으로 처리(소비)되지 않은 메시지를 보낼 수 있는 곳입니다. 문제가 있는 메시지를 격리하여 처리가 성공하지 못한 이유를 디버깅할 수 있으므로 디버깅에 유용
4. 전자상거래 플랫폼에서 이벤트 준비중. 트래픽 100배 예상. SQS Queue 사용중. 큐는 용량이 따로 없지 않나? Auto Scaling?
> 오답 : Auto Scaling 활성화, 용량 늘리기
> 정답: 아무 작업 하지 않아도 SQS 자동 확장
5. 1000명의 구독자 SNS Topic / 일부에게만 보내고 싶음 > 메세지 필터링
6. KDS 소비자 읽기 처리량 샤드 소비자당으로 늘리고 싶음 > Enhanced 로 업그레이드
7(틀림/확인필). 생산자 단에는 ProvisionedThroughputExceededException 이 발생 > 이거 처리량 초과되어서 그럼. 핫 뭐시기?
> 오답 : Partition Key 고도화 ( 이거 하는 상황 아닌가봄?)
> 오답 : 지수 백오프로 재시도 (지수 백오프가 뭔지 정리)
>> 정답 : KDS 의 용량을 늘리기 위해 지원에 문의
8. KDS 는 최대 1년? ㅋㅋ ㅇㅇ 365일동안 기록을 유지할 수 있음
9. 10개의 Message Group 이 있는 SQS Fifo Queue > 동시에 소비? 1:1 관계임 > 10개 메세지 그룹 개당 소비자 한개
10. KDS 에 6개 샤드가 ㅣㅆ는데, 분할해서 10개 하라고 함. KCL 를 기반으로 하는 소비자 앱을 사용 중인데, EC2 인스턴스 세트로 소비중. 6개까지 최대 가능? ㅇㅇ (샤드와 KCL 도 1:1)
11(확인필요). 어떤 속성이 동일한 중복제거 ID 를 가진 메세지가 5분동안 전달되는 것을 방지?
> MessageDeduplicationId (정답)
> MessageGropuId / MessageHash / MessageOrderID > 다 오답인데, 뭔지 알아야하나?, Hash, OrderID 는 처음보는거 ㅏㅌ은데
12.(틀림) 동일한 그룹에 속하는 여러 메시지를 순서대로 처리할 수 있는 SQS FIFO 속성은?
> MessageORder 겠지..? ㄴㄴ ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 이건 SQS 속성 아니라고 함
> MessageGroupID 임. MessageGroup 별로 다르게 FIFO 를 만들어주기 때문 (SQS 안에서)
13. SQS Queue 메세지 보관 최대 일수는? 14일? ㅇㅇ 맞음 (1일 ~ 14일까지 가능. default 는 4일이다)
14(확인필). SQS 는 256KB 제한이지만, 1MB 보내고 싶다. S3 와 연동해야 한다 (로 알고 있는데, 정답은 "SQS 확장 클라이언트 라이브러리 사용" 임) > S3 알아서 연동해주는거였나? 확인 필요
15. SQS 비용이 너무 높음. 소비자가 SQS 너무 자주 poll API 사용한다. 빈 데이터도 많이 가져옴. Polling 주기 늘려야 함 (Long Pulling 활성화)
16 (틀림). 쇼핑몰에서 내일모레 100배 트래픽 증가 예상. SQS 표준 대기열 사용중. 트래픽 급증으로 메세지 가시성 시간 초과로 (Visibility Timeout) 메세지 처리에 여러번 실패할 수 있다. (VT 랑 이거 자체가 무슨 상관인지 이해해야할듯), 어쨌든 이 때 실패한 메시지 처리를 위해 필요한 작업은? (문제 상황 더 이해 필요)
> 오답: VT 증가
> 정답: DLQ 구현
17. 사용자에게 알람으로 이메일을 보낼 땐 SNS
18. (틀림)SNS 로 지원되는 구독자가 아닌 경우는? : 외워야 함!!
> SQS같은데 ㅋㅋㅋ
> Kinesis 라고 함. HTTP, SQS, 람다, 모바일, Email, SMS 가 가능
19. S3 및 Redshift 에 로드하려는 대량의 실시간 데이터를 생성하는 App. 전달되기 전에 자체변환 필요. 최고의 아키텍쳐는? (KDF 는 일단 변환이 필요하니 적용해야할듯)
> 정답 : KDS + KDF : 이것은 거의 실시간 데이터를 S3 및 Redshift에 로드하기 위한 기술의 완벽한 조합이라고 함, KDF 는 람다를 사용해서 Custom 데이터 변환을 지원
20. Data Stream 에 대한 실시간 분석 수행, 어떤 AWS 서비스 적합? >> (Real-Time 이 포인트) >> 그냥 KDA 라고 함 (KDA, KDS, KDF 비교 잘 이해!)
21. 사용자 클릭 순서 / 요청 시간 / 탐색 위치 등 클릭스트림 데이터를 분석하려는 Web 있음. Kinesis 사용하려고 하는데, 클릭 데이터를 이 Stream 으로 보내도록 구성함. 이 때, KDS 로 전송된 데이터를 확인해보니 사용자 데이터가 정렬되어 있지 않음을 확인, 개별 사용자 데이터가 여러 샤드에 분산. 해결? > 이거 Record 에 있는 ID 잘 분할해야함. 사용자 ID 를 파티션 키로
(해설) : Kinesis Data Stream은 각 데이터 레코드와 연결된 파티션 키를 사용하여 주어진 데이터 레코드가 속한 샤드를 결정합니다. 각 사용자의 ID를 파티션 키로 사용하면 각 사용자의 데이터가 정렬되어 동일한 샤드로 전송
22. 6개의 샤드가 프로비전된 KDS 있음. 5MB/s 데이터 수신 & 8MB/s 전송. 트래픽이 최대 2배까지 급증할 때가 있고 ProvisionedThroughputException 이 발생하기도 함. 어떻게 해결? > 일단 처리량이 제공보다 높다는 에러임. 샤드 더 써야 할듯. 3번은 해도 똑같음.
>> 일단 샤드당 수신 1MB/s / 송신 2MB/s 이기 때문에 평소양은 문제가 없다. 급증시 문제인 것
>> 충분한 용량 제공을 위해 KDS 내 샤드 수를 늘려야 함 (KDS 용량 늘린다 == 샤드 수 늘린다) > 16 번과 같은 방향으로 생각
23.(거의 틀) 3개의 앱이 동일한 Message 보냄. 모두 SQS 사용함. 어떤 접근 방식을 쓸 것인가? 아니 목적을 말해줘야지 ㅆㅂ. (일단 정답은 SNS+SQS 팬아웃 패턴)
> 이것은 하나의 메시지만 SNS 주제로 보낸 다음 여러 SQS Queues로 "팬아웃"되는 일반적인 패턴 라고 함. 아~~ 앱에서 동일한 Topic 을 발생시키는 거구나!!
> 이 접근 방식에는 다음과 같은 기능이 있습니다. 완전히 분리되고 데이터 손실이 없으며 시간이 지남에 따라 더 많은 SQS Queues(더 많은 애플리케이션)을 추가할 수 있습니다.
24. SQS FIFO Queue 만이 메세지를 정확한 순서대로 한 번만 처리한다
> FIFO Queue 는 표준 큐에다가 다음 두가지 더 제공
>> 1. Message 순서 완전 보장, 한번 배달, 소비자가 처리/삭제할 때까지 사용 가능
>> 2. 중복된 메세지는 Queue 에 전달 X
25. KDS 에 핫 샤드 있음. KDS 처리량 예외 (PTEE) 발생. 샤드 수 늘릴 수 있는 방법은? > Splitting
====================================================================================
교육 출처
- AWS Certified Developer Associate 시험 대비 강의 - Udemy
'웹 운영 > AWS' 카테고리의 다른 글
| [CDA] 섹션 21 - AWS 서버리스 : Lambda (I) (0) | 2024.08.13 |
|---|---|
| [CDA] 섹션 20 - AWS 모니터링 및 감사 (Audit): CloudWatch, X-Ray (0) | 2024.07.30 |
| [CDA] 섹션 19 - AWS 통합 및 메시징: SQS, SNS (0) | 2024.07.21 |
| [CDA] 섹션 18 - AWS CloudFormation (0) | 2024.07.17 |
| [CDA] 섹션 17 - AWS Elastic Beanstalk (0) | 2024.07.15 |



