<242강, 243 강 섹션 개요 및 모니터링 개요>
> 너가 설계한 시스템을 클라우드에 잘 띄워놨음. 근데 동작하다가 새벽 두시에 PM 으로 부터 동작안한다고 연락을 받음
> 모니터링은 정말 매우매우매우 중요하다고 함
> AWS 내에서 누가 무엇을 만들었고, Metric, 로그, 추적, 감시 등등
> 모니터링 없이 AWS 앱을 배포한 적은 단 한 번도 없다고 함
> 우리 앱은 배포되었지만, 사람들은 사실 별로 관심없다. Beanstalk 을 썼는지, IaC 를 썼는지, 뭔지 아무 상관 없음
> 사용자들이 관심있는건 앱의 동작 여부 뿐이다. 중요한 건 다음 정도로 나열할 수 있다
>> Latency : 시간이 지남에 따라 앱 지연 시간이 늘어나는가?
>> Outages (정지) : 그렇게 가용성 신경써서 배치해놓고 정지되는 경험을 제공하면 안됨
>> 유저들이 항의하게끔 하는게 아니라, 미리 대비하는 것이 우리의 목표
> 우리가 고려하고 있어야 하는 것
>> Issue 가 발생하기 전에 미리 방지할 수 있는가?
>> 성능과 비용을 모니터링 할 수 있는가?
>> 스케일링 방식, 정지되는 방식? 등에 대한 트렌드를 살펴볼 수 있는가?
>> 이 모니터링으로 무엇을 배우고 개선할 수 있는가?
>AWS 에서 지원하는 Moinitoring 및 Auditing 리소스

> CloudWatch
>> 다양한 Metric 수집
>> 다양한 Log 수집 : Collect / Monitor / Analyze / Store
>> Events : 클라우드 시스템에서 어떤 일 발생할 시 Noti 를 발생시킬 수 있다
>> Alarms : 특정 Metric / Log / Event 에 반응해서 Alarm 을 보내기도 한다 (Event 랑 다른거..? Noti 보낸다랑?)
>> Log 랑 Metric 은 별개임을 인지하는게 중요
> X-Ray (신규)
>> 앱 performance & error 에 대해 Troubleshooting 수행 (지연시간 & 오류들을 실시간으로 확인 가능)
>> Distributed tracing of MSA (서비스들이 서로 호출 하거나, AWS 리소스와 상호작용할 때, 앱들이 어떻게 호출하고, 소요되는 시간 등을 추적해준다)
> CloudTrail
>> API 호출에 대한 Internal Monitoring 을 지원
>> AWS 리소스를 변경한 내용에 대한 감사 수행 가능
<244강 - CloudWatch Metric>
> AWS 내 모든 서비스의 지표를 제공한다
>> 주요 Metric :: CPUUtilization / NetworkIn 등등.. > 트러블 슈팅의 근거가 되기도 함
> Metric 은 namespace 에 속함
> Dimension (metric 안에 attribute (속성) 값들) : instance_id, environment 등 Key 를 가지고 있다
> 지표당 최대 10개의 Dimension 을 선택적으로 가질 수 있음
> 지표들은 TimeStamp 를 가질 수 있으며, 해당 지표에 대한 CW 대시보드를 가질 수 있다
< EC2 Detailed Monitoring>
> EC2 인스턴스는 "5분마다" 지표를 가지게 됨
>> 이 때, Deatiled Monitoring 을 활성화 한다면, 추가적인 비용이 드는 대신 1분당 지표를 가지게 된다
>> ASG 등의 원하는 작업에 대해 보다 빠른 대응을 할 수 있다
> 프리 티어는 10개의 세부 모니터링 지표를 가질 수 있다
> (중요) 중요한 지표인 EC2 메모리 사용량은 기본적으로 제공되지 않음 (내부적으로 인스턴스에서 Custom Metric 을 통해 넣어야 함)
<실습>

> CloudWatch 로 이동, 지표로 이동시 모든 지표의 namespace 를 볼 수 있음 (ELB, EBS, EC2, Firehose 등등, 내가 썼던 서비스들에 대해서 생성되는 듯 하다)

> 예시로, EC2 이동 > Per-Instance Metric 이동 > credit 입력

> 이용했던 것들, 삭제된 인스턴스여도 다 남는듯?, cpu usage 따위를 확인하면 5분마다 받는것을 알 수 있음
> 우리가 원하는 지표, 시간 지정 등을 하면서 csv 까지 살펴볼 수 있다
----------
<245강 - CW Custom Metric >
> 지금까지는 AWS 서비스의 기본값 도출 값들임, CW 로 Custom Metric 을 define & send 할 수 있음
>> ex : Memory Usage, Disk Space, 로그인 유저 등등
> PutMetricData 라는 API 를 사용할 수 있다
>> 그냥 Metric 에 Attribute 을 추가할 수 있다는 것인듯? (Dimension 을 활용해서 넣게 되는 듯)
>> 해당 메트릭에 어떤 Dimension 에 어떤 값을 넣을지 지정하는 방식
>>> ex: instance.id, environment.name 등 원하는대로 추가할 수 있음
> 지표 Resolution 를 지정할 수 있다 (이 때, 두가지 값 중 하나를 사용해서 StorageResolution API 를 사용한다)
>> Standard : 1분마다 Metric push
>> High Resolution : 1/5/10/30 초마다 지정해서 푸시 가능 (비쌈)
> (중요) Custom Metric 은 푸시하는 방향이 과거/미래 상관 없음, 그냥 들어오는 API 를 다 수용함
>> 2주 전 Metric Data Point 들이 들어오나 두시간 뒤가 들어오나 다 수용한다 (오류가 나지 않음, EC2 인스턴스 시간을 정확하게 "현재"로 구성해야 함)
<실습>
> AWS CLI Documentation, put-metric-data 로 이동, 푸시하는 방법 확인
>> 내부 [Synopsis] 에서 구성 옵션을 살펴보면 --timestamp 가 있는데, 2주전, 두시간 후 자유롭게 설정 가능
>> 실제 data, 지표 이름, storage-resoultion 설정 가능 (sr 은 위에서 살펴본 두가지 중 하나)
> 특정 파일을 푸시하고 싶으면 (안에 여러 값을 넣은 JS 따위) --metric-data 에 해당 파일 경로 지정
> CloudShell 열어서 실습
$ aws cloudwatch put-metric-data --metric-name DemoMetricName --namespace SomeNamespace --unit Bytes --value 231434333 --dimensions InstanceID=1-23456789,InstanceType=m1.small
> Custom Metric 을 CW 에 푸시하게 된다
> 다음과 같은 지표가 생성된다



> 한 항이 한 지표이며, 각 지표는 대표값(?) 과 같은 Value 가 지정되어야 하고, Dimensions 이라는 이름으로 attribute 을 가져갈 수 있는 것을 볼 수 있다
> 이와 같이 명령어를 구성해서 EC2 에서 주기적으로 보내주는 Script 를 만들면 EC2 내의 값들에 대해 ClW 의 사용자 지정 지표로 푸시 가능
> CW 의 "Unifed Agent" 가 PutMetricData 라는 API 를 호출하여 CW 에 주기적으로 지표 푸시
> 더 확실히 하기 위해 하나의 Data 를 더 넣어봤다
$ aws cloudwatch put-metric-data --metric-name AnotherMetric --namespace SomeNamespace --unit Bytes --value 241212125 --dimensions InstanceID=2-32433,InstanceType=hello.world
# 참고로 디멘션 다른거 넣으면 아예 Namespace 안에 새로운 Dimension Segment 가 생긴다

---------- 위 실습으로 지표 / 지표 Namespace / 지표 Value / 지표 Dimension 에 대해 설명할 수 있어야 한다
<246강 - CW Log >
> CW 로그는 앱 로그를 AWS에 저장하기에 가장 좋은 장소
> Log Group 을 정의해야 하는데, 보통 앱 이름으로 한다 (앱 단위로 로그를 관리)
> Log Stream 이 있는데, 이는 앱 내의 로그 instance / Log File / 혹은 특정 컨테이너를 말하게 된다
> Log Expiration 정책을 설정할 수 있다( 평생 유지, 1일 ~ 10년)
> CW Log 는 Send 할 수 있다 (도착지 : S3 , KDS, KDF, Lambda, Amazon OpenSearch 등)
> 로그는 기본적으로 암호화됨
> 스스로의 키를 활용해서 KMS-기반 암호화 제공 가능
<CW Log 로 들어가는 로그의 종류>
> SDK, CW Log Agent, CW Unified Agent 를 사용해서 로그를 보낼 수 있다
> 리소스들이 자동으로 CW Log 를 활용하는 모습은 다음과 같음

>> E Beanstalk 에서는 CW 를 사용해서 직접 로그를 수집한다
>> ECS 는 컨테이너에서 CW 로 로그를 보낸다
>> 람다는 함수 자체에서 로그를 보낸다
>> VPC Flow Log 는 VPC 에 특화된 로그를 보낸다 (metadata, network, traffic 등)
>> API Gateway 는 Gateway 를 통해 들어온 모든 요청을 CW 로그로 전송한다
>> CloudTrail 은 필터 기반으로 로그를 보낸다
>> Route 53 : DNS 쿼리 관련 로그를 기록한다
<CW Log 인사이트>

> CW 에 저장된 로그들을 쿼리 작성하여 쿼리 할 수 있는 기능
> 쿼리에 적용할 시간 프레임을 명시, 자동으로 시각화된 결과를 얻게 된다 (시각화에 사용된 로그들도 보여줌)
> CW Log 에 저장된 로그 데이터 내에서 Search & Analyze 할 수 있도록 도와준다
> 샘플 쿼리들도 볼 수 있는데, ex: 최근 25개의 이벤트, 예외나 오류가 발생한 이벤트 찾기, 특정 IP 를 찾기 등
> 미리 만들어진 쿼리 Langauage 를 제공한다
> AWS 서비스에서 활용할 수 있는 필드들을 자동으로 찾아줌
> 쿼리를 저장해서 CW 대시보드에 추가할 수도 있음 (계속 볼 수 있도록)
> 다른 계정에 있어도 여러 개의 Log Group 을 동시에 쿼리 할 수도 있다
> (중요) CW Log Insight 는 real-time engine 이 아니라 Query Engine 이다 (기록된 데이터만을 가지고 쿼리한단 뜻)
<CW Log 보내기>
<S3 Export 하기>

> 모든 로그를 S3 로 배치로 보내는 기능, 최대 12시간까지 걸릴 수 있음
> CreateExportTask API 를 활용해서 내보내기를 실행할 수 있다
> CW Log S3 Export 기능은 배칭을 사용하기 때문에 Near-Real Time 도 아니고, Real-Time 도 아니다
<CW Log Subscription : 로그 구독 (중요)>
> 로그 이벤트를 실시간으로 받을 수 있다 (실시간 처리 & 분석 가능)
> 이벤트를 지속적으로 보낼 수 있는데, KDS KDF, 람다 등으로 보낼 수 있다
> 사실상 이슈 대응 혹은 실시간 분석으로 사용될 듯 (뇌피셜)
> Subscription Filter 를 제공 > 설정한 목적지로 어떤 Type of Log events 들을 보낼지 필터링함

> 구독 필터를 통해 KDS 로 보내는데, intetgration with KDF, KDA, EC2, Lambda 등을 하고 싶을 때 좋은 선택지
> KDF 로 직접 보내기 가능 > near-real-time 방식으로 S3, OpenSearch Service 등으로 보낼 수 있다 (KDF 자체가 near-real-time)
> 람다로 보내기 가능 // 관리형 람다 함수 사용하여 OpenSearch 서비스에 실시간으로 데이터 보낼 수 있다
(실시간들과, 실시간이 아닌 것을 잘 구분해보는 것도 포인트인 듯. 이해해의 여부를 잘 확인할 수 있다)
<CW Log Aggregation>

> 다양한 Region 의 Account 로 Subscription Filter 를 사용하여 특정 계정 (최종은 당연히 일반적으로 공용 데이터 분석용 계정이겠지) 의 KDS 로 스트리밍해줄 수 있다
> 당연히 KDS 로 온건 알아서 활용 가능 (ex: KDF 수신, Near- Real- Time 으로 S3 에 저장) > 이런 방식으로 Log 집계가 가능
<Cross-Account 가 가능한 원리>

> Log Destination 과 Log Subscription 을 사용할 때, Cross-Acount 구독이 가능하다
> 위 그림처럼 두가지 계정이 있는데, 발신자에서 CW Log, Filter 를 지정 / 이는 Subscription Destination 으로 전송된다 (Subscription Destination)-> 이게 다른 계정의 KDS 따위
>> 즉 Subscrition Destination 같은건 Virtual Representation 같은 거임 (실제는 KDS 로 전송되는 것)
> Cross-Account 인만큼 당연히!! 권한 관리가 중요함
>> 접근 정책(Access Policy) : 목적지에 대한 Access Policy 에 첫 번째 Sender 계정이 해당 목적지로 데이터 전송을 허용
>> IAM Role : 수신자 계정에서 내부적으로 사용될 IAM Role 을 만듬. (KDS 로 데이터를 보낼 수 있는 권한 필요)
>>> 또한 이 Role 이 Sender 계정에서도 Assumed 될 수 있어야 한다.
>>> 아마 Sener 계정에서 Role 을 사용하라? 고 하는건가? 정확히 해보진 않아서 어떤 느낌인지는 모르겠음. 실습도 하진 않음
참고 : Assume Role 이란?
- IAM 에서 지원하는 기능 중 하나로, IAM 사용자 / AWS 외부 자격 증명으로 다른 AWS 계정 또는 리소스에 액세스 가능
- 하나의 IAM User / AWS 외부 자격 증명을 여러 AWS 계정 혹은 리소스에 공유될 수 있다
---------------------
<247강 로그 실습>
> 로그가 많진 않아서 실습을 못함. 강사도 기존에 가지고 있던거 가지고 한 듯
> 여러가지 Log Group 이 있는데, 현재 리소스별로, 인스턴스 별로 있는 것들을 볼 수 있다
> 그냥 로그들을 좀 살펴봄, SSM runCommand Output, 안에 있는 스트림 중 stdout, stderr 도 볼 수 있고 등등
<이론에서는 안나왔던 Metric Filter : 지표 필터 - 아래 이론 나와요~>

> 로그 그룹 > 지표필터 있음
> Filter Pattern : 로그 이벤트 내에서 여기에 명시하는 term / pattern 이 있으면 해당 이벤트를 대상으로 하게 됨
>> 적절한지 Test Pattern 가능

> 이 필터 패턴에 대한 Metric 지표를 생성할 수 있다는게 포인트 > Metric namespace 적고 Metric Name 적고 할 수 있음
>> Metric Value > 이 값은 Filter Pattern Match 가 발생시 Metric Name 에 대해 들어가야 할 값을 말한다. (그 아래 설명 보면, $, $. 과 같은 identifier 을 사용하여 JSON 내에서 지정 가능)
> 다시 Metric 으로 이동하면 시간 지나고 발생하면 namespace 생기고 log stream 에 표시 됨 (Metric Filter 에도 있음)
> Attribute 은 못넣나? Dimension...
> 이렇게 만든 Metric Filter 에는 Alarm 을 만들 수 있다. (이 지표가 특정 값 이상이 되었으면~) 이런식
<구독 필터>
> Destination 을 다양하게 한 Subscrition Filter 를 만들 수 있다 (람다, OpenSearch, KDS, KDF 등)
> 로그 그룹당 두가지 구독 필터를 만들 수 있음
> 위에서 이론 공부 했음
< 그밖에>
> Log 만료기간 설정 가능 10년, 하루 등으로 설정 할 수 있다
> S3 로 export 할 수 있다
> Log group 을 생성할 수 있다.
<Log Insight>
> 위에 이론 공부했고 샘플사진 있음
> 쿼리 언어를 사용해서 특정 로그 그룹을 쿼리할 수 있다 (로그 들을 분석해볼 수 있다는 장점)
> 우측에 보면 쿼리를 저장해 놓을 수도 있다, 샘플 쿼리들도 제공된다
------------------------------------------- 아 좀 정리가 잘 안되는 느낌이긴 함.. (개념들이 쫌..)
<248강 - CW Live Tail 실습으로 설명>
> 로그 그룹 DemoLogGroup 을 만든다
> 이 그룹 안에서 DemoLogStream 을 만든다

> 그 스트림에서 Tailing 시작을 누른다
>>화면성 Live Tailing UI 임을 알 수 있고, 내가 지정한 대로 필터링이 걸린 상태임을 알 수 있다
> 그러면 이 화면은 지속적으로 로그가 나타나는 Real-Time UI 를 제공해준다

> 테스트하려면 아까 로그 스트림으로 가서 Create Log Event 하면 됨 (Hello World 로 했더니 바로 잘 뜸)

>> 기능 디버깅하거나 그럴 때 유용할 듯..!!!!
> 하루에 한시간 정도는 무료라고 하는 듯
------------------------------------------
<249강 - CW Agent 및 CW Log Agent>

> 로그와 지표를 불러들여서 CW 로 전송하는 법
> 너가 필요한 앱 로그들 (EC2 에 있는 앱) 이 자동으로 CW 로 로깅되진 않는다
> EC2 에 CW Agent 를 실행해서, 너가 워하는 로그 파일들을 밀어넣어 주도록 설정해야 한다
> EC2 인스턴스는 IAM Role 이 있어야함 - CW Log 로 로그를 보낼 수 있는 역할
> 이 CW Log Agent 는 온프레미스에도 실행 가능하다
< CW Log Agent VS Unified Agent >
> 둘다 가상 서버 용 (EC2, 온프레미스 VM 등등)
> CW Log Agent
>> 오래된 버전, CW Log 로만 보낼 수 있음
> UA
>> 시스템 수준의 지표 (RAM, 프로세스 등) 을 수집할 수 잇다
>> CW Log 로 보낼 수 있다
>> 이렇게 지표 수집, Log 작업 모두 가능해서 Unified 라고 부름
>> SSM Param Store 를 사용해서 Agent 구성도 용이 (뭔 소린지 모름)
>>> 내가 사용하려는 모든 UA 들의 설정을 중앙 집중식으로 구성할 수 있다
<UA Metrics>
> UA 는 서버에 설치되어서 다양한 지표를 수집한다 (수집하는 지표 종류정도는 알면 좋음)
> 매우 세분화된 수준에서의 CPU 수준 수집 (Active, Guest, Idle, System, User, Steal 등) -> 이런 종류까진 알필요 없고, 이 정도로 세분화 되어 있음을
> Disk Metrics (free / used /total 등) , Disk IO (wirtes, reads, iops 등)
> RAM (Free, Inactive, Used, Total, Cached 등)
> Netstat (TCP / UDP 연결 갯수, net packets, bytes 등)
> Processes (총 수, dead, bloqued, idle, running, sleep 등)
> Swap Space (디스크 메모리 유츨, free, used 등)
>> UA 가 EC2 인스턴스의 기본 모니터링보다 훨~~씬 세분화된 정보들을 수집할 수 있음을 알면 됨
> 세부적으로 들어간 지표 == UA!!
-------
<250 강 - CW Log Metric Filter > - 이제야 나오네용
> Metric Filter 는 CW Log 기능으로, 로그 이벤트 내에서 특정 term 이나 expression 등을 필터링해주는 기능이다
>> 특정 IP 를 찾거나, "ERROR" 라는 로깅 단어의 occurences 등
>>> 중요한건 이걸로 "Metric" 을 만들 수 있기 때문에 Metric Filter 라고 부른다 (Alarm 트리거도 가능)
> 필터를 만들 때는 지금까지 것을 하진 않음 (does not retroactively filter data) > 생성 이후 발생하는 로그 이벤트에 대해서만 Metric Data 로 푸시한다
> Metric Filter Dimension (어트리븃?) 을 3개 까지 설정할 수 있다?? (선택사항이라는데 뭔소린지 모르겠음)

> EC2 에 Log Agent 깔려 있고, CW Log 로 로그를 계속 보내주고 있음
> 이 때 Log 는 Metric Filter 를 통과하는데, 우리가 지정한 필터 표현식을 바탕으로 실제 CW Metric 을 생성한다
> 이를 Alarm 과 연동할 수 있다 (이 메트릭 특정 지표가 1분안에 5번 발생하면 Alarm 을 발생시키고, 이를 SNS 를 통해 Alert 시킨다 따위의 패터닝 가능)
<251강 - CW Metric Filter 실습>
> 아까 했지만.. 다시 왔음 (실습은 내가 로그가 없음)
> Log group > nginx 로그로 이동 (이거는 EC2 UA 나 Log Agent 가 파일을 보내주는 방식인 듯)
> 로그 스트림으로 이동해서, 400을 쳐보면 매우 많은 일들이 존재
> Metric Filter 생성
>> Filter Pattern : 패터닝 구문 원래 복잡함. 하지만 지금은 '400' 만 간단하게 하자
>> Test Pattern 을 통해 잘 가져오는지 확인해볼 수 있다 (내 기존 로그 활용)
>> 생성시, Filter 이름, Metric Namespace, Metric Name 을 지정해야함
>> Metric Namesapce 는 MetricFilters 라고 함
>> Metric Name 은 MyDemoFilter 라고 함
>> Metric Value 는 (발생시 value 1 을 띄우라고 함)
> Metric 으로 이동해보면, 소급 적용되지 않으므로, 이제부터 발생하는 것에 대해서만 뜬다
> EBeanstalk 으로 가서 자기 nginx 다시 뜨움
> nginx 가 연동되면서 MetricFilters 라는 네임스페이스의 메트릭이 생성된다, 400 발생시 기록하기 시작한다
> Alarm 생성 > 순차적으로 설정 가능 " 5분안에 static 한 value 가 greater than 50 (threshold) 로 지정" 할 경우, 알람이 발생한다 - 400 이 5분안에 50번 발생
> Alarm 을 SNS Topic 으로 보낸다로 설정 가능
> 이렇게 메트릭 필터에 대해 Alarm 생성 가능
> Metric Filter 항목에 [Alarms] 에 연동되어 있다고 뜨기도 함
----------------------------------------
<252강 - CloudWatch Alarm>
> 우선 Alarm 과 Notification 은 다른 것임. Alarm 은 어떤 객체 느낌임. Notification 은 연동할 수 있는 행위 느낌임
> 모든 Metric 에 대해서 알림을 트리거할 때 사용
>> 샘플링, %, 최소/최댓값 등 다양한 옵션을 사용해 경보를 동작시킬 수 있다
> 상태 3가지 -> OK / INSUFFICIENT_DATA / ALARM (셋다 말그대로)
> Period : Alarm 이 Metric 을 평가하는 시간
>> High Resolution 으로 직접 설정 가능
> Alarm Target 은 보통 3가지가 있다
>> EC2 인스턴스 (중지 / 종료 / 재부팅 / 복구 등의 동작)
>> ASG 트리거 (스케일 인/아웃)
>> SNS (이메일/폰 알람 가능, 혹은 람다 함수를 사용해 임계값 초과시 원하는 동작 실행하게끔 가능)
<Composite Alarm>
> 여러 지표를 토대로 Alarm 을 형성하고 싶다면, 복합 경보를 사용해야 한다
> Composite Alarm 은 다른 여러 Alarm 들의 state 를 모니터링 하고 있는다 (다른 경보를 통합하는 작업)
> AND | OR 조건을 사용해 연동할 조건들을 자유롭게 설정할 수 있다
> "Alarm Noise" 를 줄이고 싶을때 사용하면 좋음 -> (불필요한 알람들을 말하는 듯 하다)
>> ex: CPU 사용률과 네트워크 사용률이 모두 높을 땐 경고 필요 없다 / only 둘다 낮을 때만 경고해라 이런식으로

> 기본 경보 A 를 생성해 EC2 인스턴스의 CPU 사용률을 모니터링 한다
> 기본 경보 B 는 EC2 인스턴스의 IOPS 를 모니터링 한다
> 복합 경보 자체는 경보 A 와 경보 B를 사용하고, > 경보A가 Alarm 상태이고 경보 B 가 Alarm 상태일 때 복합 경보 자체가 Alarm 이 되어 SNS 알림 등을 트리거하게 할 수 있다!
(이 부분은 원하는대로 설정 가능한 영역)
> 제법 좋아보이는 기능!
<EC2 Instance Recovery 방식 Use Case>

> EC2 에 대해선 Instance Status Check 와 System Status Check 를 할 수 있다 (각각 VM 과 내부 HW 들을 점검해줌)
>> 두 경우 모두 CW Alarm 연동이 가능하다 >> 이 때 알람이 발생했다면 Recovery 작업을 수행할 수 있음
> Recovery : 기존과 완전히 동일한 구성 (Same Private, Public, EIP, metadata, placement group) 의 EC2 를 띄울 수 있다
> 와중에 SNS Topic 에 Alert 를 하여 EC2 인스턴스가 복구 중이라고 전송할 수 있다
<그밖에>

> CW Alarm 은 CW Log 가 사용하는 Metric Filter 와 연동될 수 있다 (여러번 봤음)
> 또한, Alarm / Notificaiton 을 테스트하고 싶으면 CLI 를 사용해 set-alarm-state 라는 요청을 실행해볼 수 있다
(임계값이 넘거나 그런 상황은 아니지만 테스트를 위해 제공되는 요청 함수)
<253강 - 경보 실습>
> EC2 에 대한 CPU Util Alarm 은 만들어보자.
> micro 로 간단하게 EC2 하나 만들고, CPU 100% 가 되면 EC2 종료 Alarm 을 만들 것임

> EC2 만들고 CW 이동, Alarm 이동, 생성후 지표 선택 할 때 ec2 instance id 를 사용해 특정 Metric 을 검색할 수 있다 (이 때 생성후 지표로 뜨는데 3~5분 정도 소요됨)
> EC2 Metric 네임스페이스의 Per-Instance Metric 이란 디멘션의 > CPUUtilization 이라는 Metric 을 찾을 것임 (CPU 사용량이 ~~ 이상이라면)
> Average, 5minute 로 설정 (5분마다 확인, 차피 CW 도 EC2 Metric 을 5분 주기로 확인함)
> static 값이 95% 보다 Greater than 이라면?
>> 또한, 알림 몇개 중 몇개가? 라면 까지 설정 가능함 -> 3개중 3개 다 라고 하면 CW 는 15분 동안 3개의 Metric 을 확인할 것임. 세 개 모두 95% 보다 Greater 이라면 알람을 발생시키게 된다
<Configure Action>
> 알람 조건 이후에는 Action 을 구성할 수 있다
> Notification / 람다 작업 / 스케일링 작업 / EC2 작업
> 현재는 경보 상태일시 인스턴스 종료로 해보겠다.
>> (에러 났을시 람다 함수로 DB 에 상태 저장 쿼리를 날려서 서버 점검중이라고 앱이 띄워놓도록 할 수 있겠음)
> 경보를 일단 생성을 함. 마지막에 점검도 했음
<set-alarm-state 로 test 하기>
> 실제 trigger 시키기는 test 로 어려울 수 있다
> aws cloudwatch set-alarm-state API 이다 (검색에서 찾아볼 수도 있음)
$ aws cloudwatch set-alarm-state --alarm-name LectureDemoTerminateEc2 --state-value ALARM --state-reason "Testing"
> 이걸 하고 Refresh 를 했더니, 생성된 경보 > !경보 상태로 바뀌어져 있음 (일단 상태를 바꾸는 것, 그리고 그 이후 액션은 ALARM 임을 인지하고 동작하는 것)
>> 기록을 보면 정상 -> 경보상태로 변경되었고, 작업을 진행했음. (Action Successfuly activated 적혀 있고, Ec2 가보면 삭제되고 있는걸 확인할 수 있다)
<254강 - CloudWatch Synthetics Canary>
> ㅈㄴ 뭔지 잘 모르겠음. 실습도 안해서. 그냥 이런걸로 flow-test 를 할 수 있고, 어떤 Blueprint 가 있는지만 알아두자..
> User 가 수행할 일에 대한 Script 를 짤 수 있는?? 그러면서 Monitor your APIs, URLs..?
> Customer 가 하는 일을 프로그래밍 적으로 재현 (스크립트로) 하여 고객들에게 발생하기 전에 문제를 찾는 것을 지원
> 스크립트가 실패하면 문제가 발생했단것!
> Flow 가 잘 동작하는지를 확인할 뿐만 아니라, endpoint 의 지연, 가용성, UI 등도 저장 가능

> 특정 Region 에 배포된 앱을 CW Synthetic Canary 를 사용해 모니터링 할 것임
> 스크립트 실패시, CW 경보가 트리거 되고, 람다 함수가 호출됨 > 이는 람다함수를 호출하여, Route 53 의 DNS 레코드를 다른 동일한 앱이 가용중인 인스턴스로 업데이트 한다. (잘 동작하는 버전으로 리디렉트)
> Canary 스크립트는 Node.js / Python 으로 작성되며, headless chrome browser 로 프로그래밍 접근이 가능해, 크롬의 작업까지 할 수 있음
> 스크립트는 일회성으로 동작할 수도 있고, Scheduling 되도록 작성할 수도 있다
<Blueprint: 기본 제공 기능들??>
> Heartbeat Monitor : URL loading, 스크린 샷 보관, HTTP 아카이브 파일 저장 -> 다 잘 동작하는지 점검
> API Canary : REST API 함수들의 기본적인 읽기 쓰기 함수 테스트
> Broken Link Checker : 테스트 중인 경로 내에서 활용하는 Link 들을 검사해 잘못된 링크로 연결되지 않게 함
> Visual Monitoring : 이전에 찍은 스크린샷 vs 카나리 중 찍은 스크린 샷을 비교해 시각적 모니터링 제공
> Canary Recorder : CW Synthetics Recorder 를 활용한다 (너가 특정 웹사이트에서 하는 행동들을 녹화하여 자동으로 스크립트를 만드는 기능)
> GUI Workflow Builder : 특정 웹페이지에서 수행될 수 있는 action 들이 제대로 동작하는지 확인 (ex: 웹 상단의 로그인 폼 요청을 테스트해준다)
--------------
<255강 AWS EventBridge (이전 CW Event)>
> 아니 근데 왜 다 전체적으로 똑같은거 같냐.. SQS, Alarm, 이런거 다 Source 로 부터 Destination 으로 보내는거잖아. 뭘 어떻게 선택하고 뭘 하도록 해야 하는거임..?
> EventBridge 란 Event 라는 객체를 수신하는 공간이다. Source / Target 과 협동하여 이벤트에 대한 액션을 진행한다
> 매시간마다 람다 함수를 Trigger 하도록 세팅 가능
> Event Pattern : 어떤 서비스가 반응하도록 하는 Event Rule (Rule 에는 Pattern 이 지정되어야 함)
>> ex) IAM Root User 가 로그인 하는 행위에 대해 EventBridge 등록 가능 -> SNS Topic 으로 알림 발생 -> 이메일 알림 받도록
>> ex) 람다 함수 trigger / SNS,SQS 에 Message 보내기 등등
<EventBridge Rules>

> EventBridge 로 이벤트를 보낼 수 있는 소스들은 많다
> ex: EC2 인스턴스의 시작/정지/종료 등 // Code Build Fail / S3 업로드 이벤트 / Trusted Advisor (계정에 새로운 보안) / CloudTrail 와 궁합이 좋음 (AWS 계정 내에 발생하는 모든 API 호출)/ 위에서 말했듯이 스케줄링된 이벤트
> EventBridge 에 Event 가 전송은 되지만, 이 때 Filter 를 걸 수 있다 (ex: s3 업로드에 대한 SOURCE 가 있는데, 난 Hello_Ex 버켓에만 이걸 걸고 싶어) : 이게 EventRule 말하는건가?
> 그러면 EB 는 JSON 문서를 생성하고, 이벤트 세부사항을 명시한다 (시간, IP, 리소스 등등 많은 것이 적혀 있음)
> Destination 으로 연결한다 (상단 이미지 참조) > 다 외우라는게 아니라 위와 같은 일들을 할 수 있다는 것
> 가능성은 거의 무한하다고 보면 되고, Use Case 를 잘 설립하는 것이 중요
<EventBridge Types: Default Event Bus & Partner Event bus & Custom Event Bus>

> Eventbridge 는 AWS 서비스에서 발생하는 이벤트를 기본 이벤트 버스로 보내는 느낌
> Partner Event bus 는 파트너들과 연동하는 것임 (SaaS 파트너들이 대부분)
> 이 SaaS 에서 직접적으로 Partner Event Bus 로 이벤트를 보내게 된다 (Zendesk, Datadog)
> AWS 외부에서 발생하는 사항들도 Event 화해서 AWS 로 송신하여 Event 로서 반응시킬 수 있다
> Custom Event Bus 도 사용 가능
>> 우리 애플리케이션이 각자 이벤트를 사용해 이벤트 버스로 보낼 수 있다
>>> EventBridge 규칙에 따라 여러 곳으로 보낼 수 있다
> 또한 다른 계정으로도 수행되는 Event Bus 에도 [Resource-based Policies] 를 활용하여 접근 가능
> 필터링을 통해 일부/모든 Event 를 보관할 수도 있다 (보관된 이벤트를 replay 할 수 있음 -> 디버깅에 매우 용이 (고친 후에 다시보내기))
<Schema Registry - 아래 실습에 좀 더 설명 적혀 있음>
> 그냥 제공되는 Event Pattern 의 JSON 전체적인 모습
> 이 스키마 부분 뭔소린지 진짜 하나도 모르겠음. 갑자기 나왔으면서 ㅅㅂ. 실습해봐야 알듯
> 이벤트가 어떻게 생겼는지를 잘 이해해야 한다 (방금 봤던 JSON 형태이다)
> EventBridge 는 버스에 전달된 Event 를 분석하고 "Schema" 를 추론한다
> 이거 뭔소린지 모르겠음 : Schema Registry allows you to generate code for your application, that will know in advance how data is structured in the event bus (Event 구성을 알 수 있도록 하는 느낌)
>> 스키마 보관소에 있는 스키마는 애플리케이션 코드를 생성하는데 사용됨. (that 이 ㅅㅂ code 를 말하는거임 schema 를 말하는거임)
> 예시 ㅅㅂ 뭔소린지 모르겠네 코드 파이프라인이 있는데, 스키마 detail 이 있음. 이 스키마를 다운 받을 수 있다는 것 같음. 이걸로 (?) 스키마를 추론하고 이벤트 버스에서 데이터를 구조화하는 방법을 알 수 있다고 함
<Resource Based Policy >
> 이벤트 버스의 권한을 관리하는 방법
> ex: 특정 이벤트 버스는 다른 리전이나 계정의 다른 이벤트를 허용/거부 할 수 있다

> Use Case : AWS Organization (조직내 아마존 조직, set of accounts) 내 중앙 이벤트 버스가 있다. 여기서 모든 이벤트가 집계된다
> 중앙에 중앙 이벤트 버스가 있고, 리소스 기반 정책을 추가한다. (다른 계정에서 이벤트를 보낼 수 있다)
> 다른 Account 에서 사용중인 람다 함수는 이 이벤트 브릿지에 PutEvents API 를 활용해 이벤트를 보낼 수 있다
> 사실 이런 중앙 이벤트 버스 같은 구조 말고는 사용될 이유가 잘 없긴 하다
<256강 Event Bridge 실습>
<Event Bus 들에 대하여>
> 참고로 Cloud Watch Event 가 그냥 Event Bridge 임!!
> Event Bus > 기본 이벤트 버스 확인 가능. 여기서 규칙 적용 가능
> 새로 Event Bus 생성 가능 > 생성 화면에서 보면 archieve 여부 선택 가능 > Schema Discovery 도 선택 가능 (몬지 모름 이거..)
> 교차 계정 액세스 필요시 Resource-based-policy 적용 가능. (외부 Account 에서 이벤트 송신이 가능하도록)
>> RBP 없으면 이벤터 버스 소유 계정만이 이벤트 버스에 이벤트 보낼 수 있음 ! (아카이브, 스키마 두개 활성화한 채로 생성) > 생성하면 Custom Event Bus 임
> Partner Event Bus 확인 가능 > ex: Auth0 로 부터 오는 것들 > 설정을 누르면 Partner Event Bus SU 방법이 나와있음
> 어쨌든 이런식으로 default / custom / partner event bus 들에 대해서 설정할 수 있으니, 이제 Rule 을 볼 필요가 있음
<Events Rule>
> Creat Rule > DemoRule생성 > defulat Event bus 로 적용 > 스케줄링할지 / 패턴에 따라 할지 선택 가능

> EventSource 설정 > 강사가 언급하진 않았지만, 자신이 선택한 Event Bus 에 맞게 골라야 할듯. default 나 파트너 (목적에 맞게!!) 면 AWS/Partner // Custom 이면 기타 // central eventbridge (cross-account) 면 모든 이벤트? 뭐 이런식으로 하라는듯
>> All Event 하면 알아서 필터링 조건 하겠다 뭐 이런 쪽에 가까울 듯..?

> Sample Event 는 Sandbox 라고 하는 신기능이다
>> 메인 콘솔에서도 가능한데, 규칙을 만들지 않고 샘플 이벤트로 이벤트 패턴을 테스트 할 수 있음
>> 예시로 EC2 Instance State-change Notification 지정, JSON 이 샘플 이벤트로 형성된다 (이 JSON 이 EC2 State Change Noti 가 있을 때 EventBridge 로 전송될 Event JSON 이다)
>>> state change 를 샘플 이벤트 변경하면서 바뀌는걸 확인 가능, ex: running / pending / shutting-down 등등 (stopping 으로 설정함)

> Event Pattern 을 생성한다 (개인적으로 이게 Sandbox 보다 위에 있으면 더 이해가 쉬울 것 같다)
>> Event Provider 는 EC2 이며, Event Type 은 동일하게 State-change Notification 이다 (이게 원래 먼저 정해지는거! sandbox 에 나온건 그냥 발생되는 이벤트 지정한거임)
>> 여기서 Event 로 잡는 State 을 지정하라고 하는데, 모든 상태로 하거나, 특정 상태들만 지정 가능 (stopped / terminated 만 체크 했음)
>> 또한 특정 instance 를 지정하거나, 모든 ec2 인스턴스에 대해 하겠다고 지정 가능
>>> 즉, 말하고자 하는건, 이 Event Rule 이 적용된 Event Bus 는, EC2 가 State Change 를 바꾸는 이벤트를 수신하는데, stopped / terminated 상태로 바뀔 때만 수신하게 된다!
>>> 따라서 위에서 Sandbox 가 만든 Event 는 정상적이지 않다고 하는 이유는, Stopping 이기 때문
좀 헷갈릴 수 있는데 개념을 좀 정리해보겠음
> EventBridge (Event Bus) 는 이벤트 수신처
> Event Rule 은 Event Bus 가 어떤 방식으로 Event 를 수신할지 정하는 공간
> Event Pattern 은 Event Rule 이 특정 패턴으로 이벤트를 받겠다고 선택했을시, 어떤 패턴으로 받을지 SU 하는 곳
> Sandbox - 그냥 다른거랑 다 떠나서 EventRule 테스트 하는거. 특정 패턴의 이벤트를 발생시켰을 때 이 Rule 로 인해 EventBridge 가 Event 를 잘 수신하는지 테스트
> 마지막으로 target 을 선택할 수 있음.
> 이 이벤트 버스가 이벤트를 성공적으로 수신했을 때 할 일을 지정
>> 각 이벤트 버스들이 이벤트를 거른 후 중앙 이벤트로 또 보내주고 싶은 경우, Target 이 Event Bus 일 수 있다
>> AWS 서비스 중 고를 수도 있다
> 예시에서는 SNS Topic 으로 고름
> 이제 생성 완료
> 그럼 이제 Event bus, Rule 모두 생성이 되었고, 현 계정 안에서는 동작할 것이다
>> EC2 를 만들어서 stop / terminate 를 해보면, 이는 Event 로 감지되어 SNS Topic 으로 전달될 것이고, Topic 에 이메일을 심어놨다면 이메일에서 해당 이벤트 발생에 대해 수신할 수 있다
> 이거 집에서 Test 해보자!! (여유되면)
> 암튼 더 보면 Archive 탭도 확인 가능하고, Replays 탭에서 이벤트 들어온것을 재생해서 Event Bus 가 Target 쪽으로 잘 전달하는지 재시도 가능
> Schema Registry... 이 ㅈ같은거
> 보니까 조금 더 이해가 가는데, Event 가 JSON 이라고 했잖아? 그 JSON 의 전체적인 포맷을 그냥 확인할 수 있는 공간인 듯 (정해진 Event 에 한해서)
>> 그리고 이런 Event 를 객체화한 코드를 다운로드 가능한 것인듯 (앱에서 Customize 해야할 시 더 적용하기 쉬우라고 하는 거인듯)
> 어쨌든 제일 중요한건 Event Bus 그냥 세팅하는거 (위 네모박스 안에 개념만 잘 이해) !! 그리고 Resource Policy 로 계정간 설정하는거!
<Event Bridge 여러 계정의 이벤트 통합하기>

> Account A~D 가 있음. Central Account Event Bus 가 있음
> 각 Account 별로 필요한 이벤트들을 만들고, Event Rule 의 Target 을 Central Account Event Bus 로 설정한다
>> 단, 계속 말했던 Resource Policy 는 Central Account 에 잘 되어 있어야 한다. ( 다른 계정으로 부터 event 수신을 허용)
> 이렇게 되면 다른 계정에서 발생하는 이벤트들 (각자 Rule 을 통해 필요한 이벤트들만 발생시키게 한 뒤)을 중앙에 모을 수 있다. > 그 이후로 람다, SNS 등 하고 싶은 일을 TG 으로 지정 후 수행
> 내가 보기엔 이건 Root 계정 얘기가 아니라, 아예 다른 계정 얘기임 ㅇㅇ
-------------------------------
<258강 X-Ray 개요>
<X-Ray>
> 매우 혁신적인 서비스라고 생각한다고 함
> 운영환경에서 디버깅, 앱 디버깅 할 때, 가장 많이 급하게 쓰는 방법은, Local Test 를 확인한 후, 운영단에서 SU 될 Log 들을 여기저기 뿌려둠. 그리고 실 운영환경에 재배포해서 트러블 슈팅한다 (찔리네유 ㅋㅋ)
> 물론 이게 베스트다는 절대 아니지만, 이렇게 운영 환경 트러블 슈팅은 제법 까다롭다
> 앱 여러개면 앱마다 로그 규칙도 다르고, CloudWatch 에서도 집중시켜서 확인하기도 어렵고, 그런데 Analytics 까지 하라 그러고 ...
>> 강사가 집중하는 것은 앱이 단일이면 난이도가 낮을 수 있지만, MSA 로 집중될 수록 (distributed apps) 디버깅은 악몽과 같다는 점
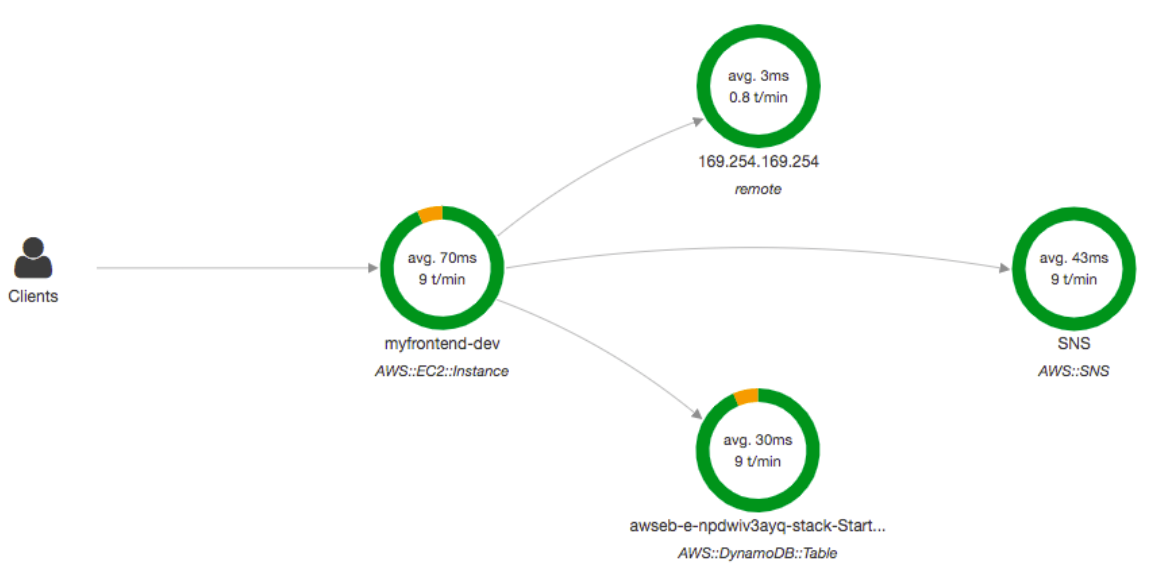
> 이 때 쓰면 좋은게 X-ray > multi - 앱에 대한 시각적인 분석을 제공한다 (우리가 EC2 인스턴스와 얘기할 때 무슨 일들이 일어나는지 시각적으로 본다)
> 위 그림처럼 앱 요청을 수행하는 클라이언트 입장에서 요청이 얼마나 실패하고 성공하는지 볼 수 있고, 하는 작업들도 본다 (다른 IP 호출, DB, SNS 호출 등등)
> 지금 위 그림만 봐도, EC2 에서 발생하고 있는 에러는 DynamoDB 와의 소통에서 발생되는 에러임을 알 수 있다 (트레이싱의 힘)
<장점>
> 병목 현상 식별 / 앱 성능 트러블 슈팅 (디버깅에 용이)
> 시각적으로 의존관계, 소통관계 확인 가능
> 문제를 일으킨 서비스 쉽게 식별 가능, 각 요청이 어떻게 동작하는지 파악 가능, 오류/예외 발견 가능
> 시간 요구사항을 충족하는지, 어느 사용자들이 오류에 영향받는지도 알 수 있음
<호환성>
> 람다, EBstalk, ECS, ELB, Gateway, EC2 Instance 나 아무 서버의 앱 모두 호환가능하다
<동작 방식>
> 트레이싱을 활용함 : 트레이싱은 end-to-end 방식으로 "request" 를 추적하는 것
> ex: 앱서버에 요청을 보내면, 해당 요청과 상호작용을 하는 구성원 (DB, ELB, API Gateway, EC2 등등) 들은 모두 "Trace"를 요청에 추가한다
> 트레이스는 Segment (+ Sub Segment) 로 구성될 수 있다 > 이 세그먼트들과 트레이스 들로 아까 그 시각적인 지도를 그리는 것
> 또한, 트레이스에는 "Annotation" 이란 것을 추가해 각 위치에서 발생한 일에 대한 부가 정보 description 도 추가할 수 있다
> 이런 기능들이 종합적으로 사용되어, 모든 요청 (or 관리자가 설정한 요청의 %를 샘플링) 에 대하여 Trace 를 할 수 있다
> 보안으로는 권한은 당연히 IAM으로 동작하며, KMS encryption 을 사용할 수 있다
<X-Ray 적용법 : 시험에 나올 확률 농후하다>
1) 앱 코드가 X-RAY SDK 를 import 해야 한다
>> 코드는 많이 바꿀 필요는 없지만 일부는 수정해야 한다
>> X-RAY SDK 는 1) AWS 서비스에게 통신 2) HTTP / HTTPS 요청 3) DB 소통 들을 감지한다

2) X-Ray AWS Integration 을 위해 X-RAY 데몬 프로그램을 설치한다
> EC2, 온프레미스 등의 VM 형태로 앱을 운영할 때는 데몬을 설치해야함.
> X-Ray 데몬 프로그램 : 백그라운드에서 돌아가는 (low-level) UDP 패킷 인터셉터 같은 프로그램
> 람다나 다른 Aws 서비스는 알아서 X-Ray 디몬 동작중임
> 각 앱은 X-Ray 에 데이터를 쓸 IAM 권한이 있어야 한다
>> 단골 시험 질문: "컴퓨터에서 로컬로 테스트할 땐 X-Ray 앱이 잘 작동하는데, EC2에선 안된다. 왜 그럴까요?
>> ANW :: 님들 로컬에선 X-Ray 데몬이 실행중이지만, Ec2에선 X-Ray 데몬이 없어서 X-Ray 가 너의 시스템 상호작용을 감지하지 못하는 것
> 그림을 보면, sdk 가 데몬에 Trace 들을 전송하고, 데몬이 최종 처리를 하는 것을 알 수 있다
<X-Ray 가 동작하지 않아요 ㅠㅠ>
> 정확한 IAM Role 이 부여되어 권한이 있는지 확인하자
> EC2 가 X-Ray 데몬을 실행중인지 확인하자
> 앱 혹은 람다 등에서 사용하는 코드가 X-Ray 를 import 하고 modify 되었는지 확인
> 참고로 람다를 활용중일 경우, 데몬은 신경쓸 필요 없고, "AWSX-RayWriteOnlyAccess" 라는 Policy 를 포함한 IAM Execution Role 을 가지고 있는지 확인해야 한다 (그냥 권한만 신경쓰라는 뜻..)
>> 또한 람다에서는 람다 설정 중 "X-Ray Active Tracing (추적 활성화)" 를 켜야 동작한다~
-------------------
<259강 X-Ray 실습>
> X-Ray 역시 CloudWatch 리소스에 있는데, Log, Metric, Alarm 등과 한번에 보면 좋기 때문이라고 함
> 강사님이 custom 한 앱으로 test 를 해볼 예정. CloudFormation 을 통해 생성해보자.
> CF 이동> Stack 생성> 소스 파일에서 x-ray 폴더 안에 있는 "eb-java-~~" 이거 사용한다 > Upload Template
> name : scorekeep-xray 로 하고 다 기본 설정, 맨 아래 세가지만 설정한다
>> Subnet 1 은 첫 서브넷 선택 / Subnet2 는 두번째 서브넷 선택 / VPC ID 는 기본 VPC 는 첫 VPC 를 활용한다 >> 이거 Template 에게 어디에 배포할지 위치를 전달해주는것
> 다 다음 페이지로 넘기고, Submit 함 > CF 를 만들어준다
> 이제 CF 템플렛을 살펴보면, ECS 클러스터를 배포한다 > 그리고 두개의 Front End, Back End API 이미지를 활용한다
> 그냥 그림그려주는거 지켜보게 될텐데 뭘 굳이 따라하나.. 싶어서 강의로만 한다. 일단 yml 나도 한번 올려봐서 캔버스로 그려본 사진 첨부해놓는다.

> 이렇게 CloudFormation 으로 생성을 마침
> 게임을 할 수 있는데, 이 게임을 하면서 X-Ray 가 그려진다
>> X-Ray Traces 에서 Service Map 으로 이동, 그림들을 확인할 수 있다
> 요청별 분석, 에러 확인 등등 할 수 있음
> 실제로 해보면서 더 이해해보는게 좋음 이건
> 사진을 못찍어서 ㅏ쉬운데, 특정API 요청이 DyanmoDB 에 몇 개의 쿼리를 날렸는지, 쿼리별로 시간이 얼마나 걸렸는지 또한 확인할 수 있다
-------------------
<260강 : X-Ray Instrumentation >
> 제품의 성능 측정 (Measure of product's performance), 오류를 진단 (diagnose errors)하여 trace 정보를 기록하는 것
> X-Ray 는 좋은 instrumentation 방법인데, 이를 위해선 앱 단에서 SDK를 심어야 한다
> 코드를 수정하여 X-Ray 로 전달하는 데이터에 정보를 추가, annotation (아래 나옴) 을 추가하는 등의 커스터마이징을 할 수 있는데, 이 때 interceptor / filter / handler / middleware 등을 사용한다 (동작을 커스터마이징 할 수 있다는 포인트)
<그밖의 X-Ray Advanced Concept>
> Segment 는 trace 가 구성되는 것으로 데이터를 담는 공간 (앱과 다른 서비스들이 보낸다)
>> Sub Segment 는 Segment 에서 더 구체화를 시켜야 할 때 사용된다
> Trace : 모든 Segment 들이 Collect 된 것, API 호출과 같은 end-to-end 통신간의 뷰를 형성해준다
> Sampling : X-Ray 로 보내지는 요청의 데이터를 줄이는 것 (모든 요청 분석이 필요한건 아닐 수 있기 때문, 가격 절감)
> Annotation (중요) : Key-Value 페어로, Trace 를 index 하고 필터와 함께 사용될 수 있도록 하는 값
>> 추적을 검색할 때 매우 중요해짐
> Metadata : Key-Value 페어로, 인덱싱되진 않는다. (Search 로 사용될 수 없다)
> X-ray Daemon / Agent 에는 Cross-Account 로 Trace 를 보낼 수 있는 기능도 제공해준다.
>> IAM 권한이 잘 매핑되어 있어야 함
>> 중앙 집중적인 계정에서 종합적인 로깅을 가능하게 해준다
<Sampling>
> X-Ray 로 보내서 레코드 하는 데이터의 양을 조절하여 비용을 절감하는 정책 (코드 변경 없이 적용 가능)
> 기본적으로 X-Ray SDK 는 초를 기준으로 모든 첫번째 요청을 기록하고, 이후 추가 요청의 5% 를 기록한다 (매초 기준으로 하는 얘기)
>> 그 첫번째 요청을 "reservoir" 라고 한다.(서비스가 요청을 지속으로 수행하는 도중에도 매초마다 최소 하나의 트레이스 기록을 보장하는 것)
>> 5% 는 "rate" 라고 한다. reservoir 를 초과하는 추가 샘플링 정도를 말한다.
<Sampling Rule 만들기>

> reservior / rate 를 명시하면서 Sampling 규칙을 만들 수 있다
> 좌측 : 10 / 10% 이면, 초당 10개의 요청이 X-Ray 로 보내지고, 이후 다른 10% 가 보내진다
>> 예시처럼 POST 만을 위한 규칙을 따로 만들 수도 있는 것
> 우측은 디버깅 요청, 모든 요청에 대한 것 -> 1 / 1 이면 모든 요청을 하라는 뜻
>> 실제 상황에서 이렇게하면 매우매우 비싸진다
> 변경한다고 해서, 앱이 재기동될 필요가 없음, SDK 수정 필요 없음 (데몬이 이 규칙을 정정해주기 때문)
----------------
< 261강: X-Ray Sampling 규칙 >
> CloudWatch > 설정 > Traces[기록] > 샘플링 규칙 이동
> 현재 default 설정, r/r = 1, 5 인 것 확인 가능 (요것만 바꿀 수 있음 default 에선)
> New Sampling Rule 을 생성할 수는 있다
>> Priority 1~ 9999 : 낮을 수록 우선 순위이다.
>> R/R 설정 가능 (Reservoir / Rate)
>> Matching Criteria (제한 설정) : 특정 서비스 대상, Method, URL 등을 설정하여, 약간 필터링 처럼 샘플링을 할 수 있는 것
> 이걸 굳이 반영하여 앱을 잭디동할 필요가 없다는 것도 큰 장점
----------------
< 262강: X-RAY API (X-Ray Daemon 용)>
> 이걸로 뭐가 가능한지를 좀 이해하고 있어야 함 ( 시험에서 ~~ 런걸 API 로 수행할 수 있는가? 이런식으로도 물어보기 때문)
<Write API>

> PutTraceSegments : 세그먼트 문서를 X-Ray 에 업로드한다 (X-Ray 에 Write 하는 기본)
> PutTelemetryRecord : 데몬이 Telemetry 를 업로드한다 (수신 허용/거절된 Segment 들 정보, 백엔드 연결 오류 정보 등) : Metrics 에 도움이 된다
> GetSamplingRules : "Get" 이 Write 에 있다는 점을 주목
>> X-Ray 데몬이 자동으로 샘플링 규칙 변경 정보를 반영해 줬던 것을 떠올려보자
>> 뭔가 바뀌었을 떄 AWS 측에서 데몬으로 요청을 보내나? 아님 스케줄링 되어 있는지는 모르겠지만, SamplingRule 을 불러올 수 있어야 하므로 이에 대한 권한/허가가 필요
>> 이와 연장선인 API 가 GetSamplingTarget & GetSamplingStatisticsSummaries 임
> 이런 API 들을 사용하기 위해선 X-Ray Daemon 도 API 를 사용하기 위해 IAM 정책을 가지고 있어야 함
<Read API>

> 모든 API 이름이 "Get" 이다 (Read 답게)
> GetServiceGraph : 콘솔에서 봤던 메인 그래프 가져오기
> BatchGetTraces : 전달하는 ID 들에 대한 Trace List 들을 반환받기 위함. (알다시피 트레이스는 한 요청에서 발생하는 세그먼트 문서의 집합)
> GetTraceSummary : 특정 시간에 대한 트레이스의 ID들과 Annotation 들을 반환받는다. 트레이스 정보를 알고 싶으면 이 ID 들을 BatchGetTrace API 를 연계하여 활용한다
> GetTraceGraph : 하나 혹은 이상의 Trace ID 를 전달하여 이와 관련된 그래프를 반환한다
----------------
< 262강: X-Ray 와 Beanstalk 연계 >

> Beanstalk 환경에는 항상 X-Ray 데몬이 자동으로 들어가 있다 (따로 추가 필요X)
> 간단히 콘솔에서 옵션 하나 적용하여 설정 가능 / 혹은 .ebextensions 파일로 xray-config 라는 파일을 생성해도 된다 (.ebextensions/xray-daemon.config)
option_settings:
aws:elasticbeanstalk:xray:
XRayEnabled: true
> 이렇게 간단하게 파일에 명세하면 활성화된다
> EC2 인스턴스가 적합한 EC2 Instance Profile 을 가지고 있는지 확인. X-Ray 데몬이 잘 동작할 수 있는 IAM 권한을 EC2 가 가지고 있어야 한다.
> 애플리케이션이 X-Ray SDK 로 잘 Instrumented 되어 있어야 한다
> (만약) Multiconatiner Docker 를 사용중이라면, ECS 로 직접 데몬을 관리해야한다.
> 실습도 진행함
>> beanstalk 을 빠르게 생성하고, 마지막 생성 버튼 옆에 [configure more] 로 이동
>> 지금은 단게별로 설정하는 UI 로 바뀐듯! (건너뛰지 말고 하나씩 보면 됨)
>> 여기서 x-ray daemon 활성화 체크버튼 하면 됨 ㅇㅇ
>> 또한 Ec2 인스턴스가 적합한 IAM 권한을 가지고 있는지 확인해야 한다

>> 같은 화면에서 [Security(보안)] > 편집 으로 이동
> 이거 역시 2단계에서 확인 가능하고, IAM 으로 이동하지 않고도 현재 설정된 프로파일에 어떤 권한이 있는지 [권한 세부 정보 보기] 로 호가인 가능하다
> VM Permission 에서 IAM instance Profile 을 설정주면 된다.
>> 현재 기본으로 정의된게 [aws-elasticbeanstalk-ec2-role] 인데, 여기에 해당 권한이 있는지 들어가서 확인해준다.
>> 저 버튼 눌러서 들어가보면 (AWSElasticBsWebTier/MulticontainerDocker/WorkerTier) 3개의 권한 정책이 있음.
>> WebTier 을 들어가보면, "X-Ray" 가 있고, 여기 들어가면 Read Permission 과 Write Permission 들이 있는걸 확인할 수 있다 (위에서 배운게 다 있진 않음!!)
> Beanstalk 으로 구성했어도 꼭 권한을 확인하여 제대로 X-Ray 가 동작할 권한을 주어야 한다!
----------------
< 263강: X-Ray 와 ECS의 연계 >

> ECS 와 X-Ray 연계에 대해서는 시험에 꽤 출제되었다. 동작방식과 그들의 차이를 이해하고 특히 Fargate 방식을 잘 이해해보자.
> ECS 에서 X-Ray 를 활용하는 데에는 3가지 옵션이 있다 (아래 그림이랑 같이 확인)
>> 1 - X-Ray 데몬 자체 하나를 컨테이너로 사용
>>> ECS 클러스터에 두 개의 Ec2 인스턴스 있음. 각 EC2 인스턴스에는 X-Ray Daemon Container 을 기동한다. EC2 인스턴스 하나당 X-Ray 데몬 컨테이너를 가지게 되고, 우리 앱 컨테이너는 알아서 띄우면 됨
>> 2 - Sidecar 턴 사용
>>> EC2 를 여전히 직접 가지고 있지만, EC2 당 하나의 데몬 컨테이너를 띄우는게 아니라, 앱컨테이너 하나당 데몬 컨테이너 하나를 띄우는 Sidecar Container 를 띄우는 것. (데몬 컨테이너가 앱과 'side-to-side' 로 띄워지기 때문. 원래 다양하게 사용되는 패턴임)
>> 3- Fargate 용
>>> 파겟은 EC2 인스턴스를 직접 가져가는게 아니였다. 따라서 X-Ray 데몬 컨테이너를 사용할 수 없고, Fargate Task 를 쓰고 싶으면 앱 컨테이너에 X-Ray SideCar 컨테이너를 묶어서 같이 하나의 Task 로 배포해야 한다.

< 3번 Fargate Task Definition 예시 >

> X-Ray 데몬이 가장 먼저 기술되며 이 Task 에서 띄워진다는 걸 알 수 있다
>> 이 X-Ray 컨테이너가 활용하는 포트는 2000번이며, UDP 통신을 사용한다 (데몬은 UDP)
> 그 이후로 앱 컨테이너가 기동된다
>> 중요한 점은 환경변수가 주입되는데, "AWS_XRAY_DAEMON_ADDRESS" 가 주입된다는 점이다.
>>> 필수적으로 Set 해줘야 하고, SDK 가 데몬을 찾기 위해서이다. (value 는 "xray-daemon:2000" 이다) > 위 포트와 일치해야함
>> 마지막으로 앱 컨테이너가 "links" 를 통해 두 컨테이너간의 네트워킹을 연결해준다 (docker network 이런거 아니겠누)
>>> 이걸 해줬으므로 xray-daemon 이란 이름의 컨테이너를 알아서 환경변수에 적힌 값으로 통신을 보낼 수 있는 것
----------------
< 264강: AWS Distro for Open Telemetry >
> OpenTelemetry 란?
> 그냥 이 설명들은 읽어보고, 그림이랑 그림 아래 두줄이 그냥 핵심 요약!
>> Single Set of API, Libraries, Agents, and Collector Services 들을 사용하여 애플리케이션에서 분산된 트레이스 및 지표를 수집하는 방법
>> 또한 AWS 리소스나 서비스로부터 메타데이터를 수집하는데 도움이 될 수도 있다.
>> X-Ray 와 매우 유사하지만 Open Source 이며, Auto-Instrumented Agent 들이 코드의 변경 없이 자동으로 Trace 를 수집한다.
>> 또한 수집한 것을 바탕으로 Trace / Metrics 들을 다양한 AWS 리소스 및 파트너 솔루션들에 보낼 수 있다.
(ex: 수집한 trace 를 다시 X-Ray Service / CloudWatch / Prometheus 등으로 보낼 수 있다)
>> 즉, 너의 런닝 중인 앱 (EC2 / ECS / EKS / 온프레미스 등등) 을 Instrument 하여 "OpenTelemetry 표준" 을 사용하여 수집한 trace & 지표를 다른 서비스/리소스들로 보낼 수 있는 것
> Open Source API 를 활용함으로써 앱이 사용하는 트레이싱을 표준화하고 싶으면 AWS Distro for Telemtry 로 migrate 하는 것을 추천한다.

> OpenTelemetry 용 배포판이 있음 (AWS Distro), 이걸로 앱간 전달되는 요청으로 부터 data 를 수집한 Trace & Metric 을 수집하고, AWS 지원 덕분에 AWS 리소스들에 대한 Contextual Data 를 수집할 수 있다.
> 그리고 이 모든 수집된 객체 데이터들을 다양한 곳으로 보낼 수 있다.
> 개략적인 문제로 하나 정도 나올 수 있다. 이게 뭔지?에 대하여
====================================================================================
교육 출처
- AWS Certified Developer Associate 시험 대비 강의 - Udemy
'웹 운영 > AWS' 카테고리의 다른 글
| [CDA] 섹션 21 - AWS 서버리스 : Lambda (I) (0) | 2024.08.13 |
|---|---|
| [CDA] 섹션 20 - AWS 모니터링 및 감사 (Audit): CloudTrail (0) | 2024.08.10 |
| [CDA] 섹션 19 - AWS 통합 및 메시징: Kinesis (0) | 2024.07.25 |
| [CDA] 섹션 19 - AWS 통합 및 메시징: SQS, SNS (0) | 2024.07.21 |
| [CDA] 섹션 18 - AWS CloudFormation (0) | 2024.07.17 |



