<272,273강 서버리스 & Lambda>
> 시험에서 서버리스 지식에 대해 꽤 깊게, 그리고 많이 물어봄 (개발자 시험이라 그런것! 개발자랑 가장 가까운 배포 영역이다)
> 다른 시험은 람다에 대해서 그렇게 많이 안물어보는 듯 (개발자 영역에서 매우 중요한가봄)
> 람다는 서비스 업계의 파라다임을 바꿔놓을 정도로 많이 사용되는 서비스
> 서버리스란?
>> 개발자들이 직접 서버를 직접 provision & 관리할 필요가 업다는 것. (사실 없다는게 아니라, 직접 관리할 필요성이 사라진걸 말함)
>> function / code 만 배포하기 때문에, FaaS 단위의 서비스이다 (Function as a Service)
> 태초에 서버리스는 람다로 인해 개척된 영역이였으나, 현재는 "DB, Messaging, Storage 등등" 관리의 영역에서 지원된다면 다 서버리스라고 부른다
<AWS에서 서버리스란?>

> AWS에서 제공하는 서버리스는 다음정도가 있다
>> Lambda, DynamoDB, Cognito, API Gateway, S3, SNS&SQS, KDF, Aurora, Step, Functions, ECS Fargate 등등
---------------------
<273강 : AWS 람다>
> EC2 (Virtual Servers)
> Provision 필요, RAM/CPU 제한 있음, 직접 가동/중지 상태 등을 제어한다
> Scaling 은 ASG에서 지원하며, 서버를 add/remove 하기 위해 어떤 과정을 거쳐야 한다
> Lambda (Virtual Functions)
> Time 으로 제한을 갖게 된다
> On-Demand 로 사용되어, 사용하지 않을때는 운영되지 않는다
> Scaling 은 자동화되어 있다 (호출이 많아지면, 자동으로 람다 함수를 더 증가시켜준다)
<AWS 장점>
> 비용 계산이 매우 쉽다 (가동 시간 & 요청 수로 계산됨)
>> Free Tier : 1,000,000 AWS 람다 요청, 400,000 GB 기동 시간
> 정말 다양한 AWS 서비스들과 연계가 가능하며, 다양한 언어를 지원한다, CW 로 모니터링도 매우 쉽다
> 함수당 더 많은 리소스를 할당하고 싶으면, 함수당 RAM 할당량을 증가시킬 수 있다 (최대 10GB)
>> 참고로 RAM 성능 높이면, CPU 와 Network 성능도 같이 올라가긴 한다고 함
<언어 지원>
> Js (Node JS), Pytho, Java, C#(.Net Core), Golang, C# (Powerhsell), Ruby, Custom Runtime API (ex: Rust)
>> Custom Runtime API (오픈 소스) 덕분에 사실 모든 언어가 다 된다고 봐도 됨
> Lambda Container Image 도 지원한다
>> "Lambda Runtime API" 를 활용하는 이미지를 지원하게 된다
>> 단순 Docker Image 를 위한건 ECS/Fargate 를 활용하면 된다
>> 시험 문제에서 Lambda Runtime API 를 활용하지 않는 이미지를 배포하려 한다. 어떻게 해야 하는가? 이런걸 물어 봄 > ECS/Fargate 이 정답
<타 리소스들과의 연계 >

> API Gateway 가 있어 REST API 를 만들어서 람다 함수를 트리거 한다
> Kinesis 는 중간에 필요시 Data 변형을 위해 람다 함수를 사용한다
> DynamoDB 는 DB에 무슨 액션이 나타났을 때 람다 함수를 트리거 한다
> S3 는 람다를 매우 많이 활용하는데, File 이 생성되거나 할 경우 람다를 트리거 할 수 있다
> CF 는 따로 배울 것임
> CW EventBridge 인프라에 어떤 일이 생겨 대응하려고 할 때 연계 가능 (ex: Pipeline 에 변화가 생겨 바로 적용하고 싶을 때)
> CW Log : 로깅을 그 어디에든지 Stream 할 수 있다
> SNS : Topic 트리거의 결과로 람다 트리거가 가능
> SQS: Message Processing 을 하는 녀석을 람다 함수로 사용할 수 있다
> Cognito : 누군가 DB 에 로그인하거나 그런 액션에 대해 람다 함수로 반응할 수 있다
<대표적인 Use Case1 : 서버리스 썸네일 이미지 생성>

> S3 에 새로운 이미지가 생성되었다고 하자
> 이 Object 생성은 람다 함수를 Trigger 하여 썸네일 이미지를 만든다
>> 또다른 S3 경로로 저장시킬 수도 있다
>> 혹은 DynamoDB 에 Data 에 대한 제어를 할 수도 있다 (특정 File 내에서 thumnailUrl 따위를 제공)
<대표적 Use Case2 : 서버리스 Cron Job>

> Cron Job 란 Cron 이란 프로그램을 사용하여 EC2 인스턴스 따위에서 주기적으로 실시되는 스케줄링 작업을 말한다
> Cron Job 을 위해 EC2 를 프로비저닝 하는건, Cron Job 없을 때는 다 돈 낭비이다.
> 그래서 EventBridge 에서 Event Rule 을 만들어서 1시간마다 람다 함수를 Trigger 하도록 한다
>> 아무튼 서버리스 크론을 하더라도 Job 을 트리거할 지표는 필요하긴 하지.
<람다 Pricing>
> 요청 갯수로 우선 처리되는데, 첫 1,000,000 요청은 무료이다 (매일은 아니겠징? 계정당이겠징?)
>> 그 이후로 백만 요청마다 0.2 달러이다 (ㅈㄴ 싼데..?)
> 처리 시간에 대해서도 지불되는데, 매달 400,000 GB-sec 의 처리 시간은 무료이다
>> 이게 먼 뜻이냐면 1GB RAM 으로 400,000 초동안 처리 한다는 것 (이거 처음 알았넹 ㅋㅋㅋ)
>> 즉, 저렴한 128MB RAM 으로 처리한다면 3,200,000 초 걸리는 것. (오래 걸려도 되는거면 싸게라도 할 수 있음)
>> 암튼 그 이후에는 600,000 GB-sec 당 1달러이다
> 맞다. 람다는 매우 싼 리소스이다. 그래서 더더욱 유명하고 더욱 많이 사용되는 것
---------------------
<274강 : 람다 개요 실습>

> 소개 화면에 두번째 작동방식을 보면, 감잡기 좋음. 특정 이벤트를 직접 코딩해보고, 다음을 눌러보면 어떤 스트리밍으로 인해 내 함수가 지속 트리거 된다
> 스트리밍을 계속 누르면 그만큼 많이 람다 함수가 Invoke 되어서, 자동으로 람다 함수가 Scaling 되는 모습과, 그만큼 비용이 증가하는 모습도 확인할 수 있다
>> 500만건의 요청을 수행했음에도 5달러..
> 그래서 이제 직접 함수를 생성해보자
> Use Case 에 대해서 분석한 Blue Print 를 사용해서 생성해보자
>> Python 용으로 Hello World
>> 실행 역할은 기본 람다 권한을 가진 새 역할
>> 코드 확인 가능 (input 되는 event 배열을 출력해준다)

>> Test 해서 Test 이벤트를 생성하고 JSON 도 만들 수 있음 (저장하니 테스트 이벤트 저장 로그 뜸)
>> 아까 Test 짠대로, 배열 출력하고 value1 을 반환한다
>> 로그도 확인 가능한데, Duration, Billed Duration, Provisioned Memory & Used Memory 등에 대해 확인 가능하다
> Configure 도 가능하다
>> Memory 설정 가능 (이거 지정한대로 사용하는거구나. Used Memory 를 지속 모니터링 하면서 줄이거나 늘릴 수 있겠다)
>> Timeout 설정 가능 (보면서 일반적인 사용 시간을 넘어가면 비이상으로 판단, 중지가능)
> Monitoring 을 구경해보자
>> Invocation, Duration, Error 발생 등을 확인 가능
>> 이 함수와 연계된 CW Log 를 확인 가능. 방금 실행한 건에 대한 LogStrream 을 확인 가능하다
>>> 방금 트리거 하면서 봤던 모든 Log 가 다 LogStream 으로 저장된 모습을 확인할 수 있다
> 당연히 코드 수정도 콘솔에서 가능, 변경 후 Deploy 누르면 된다
> raise Exception 을 두고 Test 를 누르면 예외 발생이 결과가 된다 (아까 Error 발생 Monitor 가 증가할 것)
> Configuration (구성) 탭에서 Permission 으로 이동하면
>> Execution Role 에 {내가 생성한 람다 함수 이름-role-128yudsf} 뭐 이런 역할로 지정되어 있는 것을 볼 수 있다
>> 이 역할의 Policy 를 보면, CW Log 에 접근할 수 있는 Policy (Create Log Stream & Put Log Events)
<실습 후 느낀 점>
> 진짜 그냥 Trigger / Result 전달 에 대한 함수를 배포하는거구나 말그대로
> 약간 코딩테스트할 때 코드 업로드하는 느낌이 난다. 내가보기엔 충분히 그 기능을 람다로 구현한다고 봐도 무방할 듯
> 업로드 한 코드를 띄워서 특정 Set 을 돌리고 결과를 View 해주는? (물론 서버로 해도 아무 이상한 점 없지만 ㅋ)
-----------
<275강 Lambda 의 동기식 호출 - Synchronous Invocation>

> CLI, SDK, API Gateway, ALB 등을 사용할 때 동기호출을 진행한다
> 동기호출이란 람다 요청을 보내고 응답을 받을 때까지 기다리는 것을 의미하며, Error 발생하는 것은 직접 제어해야 한다
>> ex: retry, exponential backoff 등
> User Invoked 형태이면 보통 동기식 호출이다
>> ALB, API Gateway, CloudFront (Lambda@Edge : 배울거임)
>> S3 Batch (S3 Object 관련은 Async 이다)
> Service Invoked 중에서는 다음과 같이 있다
>> Cognito, Step Functions
> 그외
>> Lex, Alexa, KDF 등
-----------------------
<276강 동기 호출 실습>
> 아까 Test 했던 것을 다시 보면, 우리가 Test 버튼을 누르면 동글뱅이 돌면서 응답을 기다린다 (동기식 호출)
> CLI 로도 Test 가능해서 들어가보자 (AWS v2 인걸 우선 확인)
$ aws lambda list-functions
>> 내 Region 에 존재하는 함수들을 list 해준다
>> --region eu-west-1 이런식으로도 설정해줄 수 있다 (Cloudshell 을 안쓸 수도 있기 땜)
>> 아까 생성한 함수의 ARN, 이름, Handler 등 metadata 를 알 수 있다

$ aws lambda invoke --function-name hello-world --cli-binary-format raw-in-base64-out --payload '{"key1": "value1", "key2":"value2", "key3":"value3"}' --region ap-northeast-2 response.json
> 이 명령어를 사용하면 hello-world 란 이름 (나는 lecture-lambda 로 함)의 함수를 trigger 해주는데, 요청 payload 를 넣어줄 수 있고, response.json 으로 응답을 받아와준다.
> 명령을 실해아하면 응답 코드가 200 으로 오는 것을 확인할 수 있고, response.json 이 경로에 저장되어서 cat 으로 조회할 수 있다
> response.json 은 함수가 전달해준 JSON Event 가 그대로 전달된다 (Python 에서 return 해준 모습이 그대로 날라옴)
----------------------
<277강 Lambda with ALB>

> 람다함수는 HTTP(S) 엔드 포인트를 가지고 노출을 해야할 수도 있다 (함수 Trigger 를 HTTP로)
> ALB / API Gateway 사용하면 된다
> ALB 의 Target Group 에 람다 함수가 등록이 되어 있어야 한다
> 어떻게 HTTP 요청을 람다 Invocation 으로 바꾸는걸까?
< ALB 와 Lambda 의 변환 = Http, JSON 간의 변환>

> HTTP 는 JSON 문서로 변환된다
> 위 그림은 변환된 JSON 의 모습으로 보면 Payload 안에는 ELB 정보 및 Http 요청 정보 (Method, Path, Query Params, headers, body 등등) 가 있음

> Response 측면에서는 JSON 이 다시 Http(s) 로 변환된다
> Status Code & Description / Headers / Body 정보들 (html 파일) 따위가 모두 JSON Response 로 ALB 에서 변환된다
<ALB Multi-Header Values>
> ALB 가 Client 측에 열려 있다면, ALB 설정 중 "Multi-Header Value" 설정을 활성화할 수 있다
> 오 이건 당연한건줄 알았는데 Spring 에서도 지원을 해주는거였구나
> Query Parma 이나 header 에 Key 값이 같은 Pair 가 여러개 들어오면, List 로 묶어서 전달해준다
> 즉, 변환된 JSON 에는 해당 Key 에 대한 Value 는 Array String 으로 들어가 있다
----------------------
<278강 Lambda with ALB 실습 / 좀 신기함! >
> 우선 Lambda 를 만든다 (python3 으로) (lecture-lambda-alb)
> 로밸도 만든다 (ALB) - 지역 내 모든 서브넷에 걸쳐 생성 (lecture-lambda-alb)
>> Security Group 도 만든다 (lecture-lambda-alb-sg)
>>> 인바운드 http 어디서나
>>이 SG 를 ALB 에 적용함
>> 이제 TG 까지 만들어서, 위 람다가 포함되도록 만들고 이쪽으로 ALB 를 지정해준다
>> 생성 완료!
> 아까 생성했던 람다함수에 들어오는 event (아마 BODY 요청일것?) 를 print 하도록 변경하고, return 은 그냥 그대로 200 을 반환하도록 한다

> 이제 UI 에 ALB 가 연동된 것도 볼 수 있고, ALB 프로비전 완료되어서 DNS 이동을 해볼 수 있다.
> 이동해보면 dma 파일 하나를 다운 시도하는 것을 볼 수 있다 (html 을 보여주지 않는 이유는 규격에 맞춰지지 않고, content-type 이 전달되지 않았기 때문)
>> 이걸 열어보면, Hello From Lambda 라고 아까 전달한 return 중 'body' 내용이 담겨있다.
> https://docs.aws.amazon.com/lambda/latest/dg/services-alb.html
>> 해당 문서를 살펴보면, lambda 에서 내려줘야 하는 reponse 의 format 을 볼 수 있다
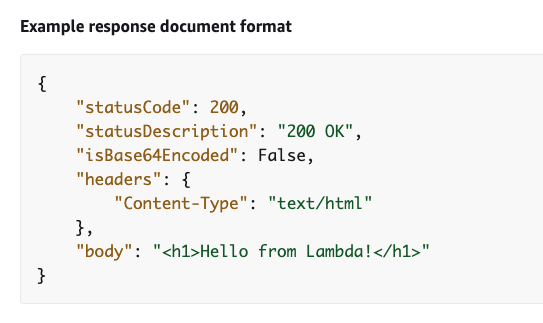
>> 이거를 복사해서 Python lambda 함수에 넣어줘보겠다 (저 문서 안에 있는걸 그대로 return 객체에 넣음)
> 뭐 어쨌든 객체로 Json 형태를 규격에 맞춰 전달해주면 되는거다 (HTTP 변환을 지원할 수 있도록, Content-Type 과 body 등 필드를 포함하여)

> 그럼 이제 웹 뷰로 Hello From Lambda 가 html 띄워진 것을 확인할 수 있다~~!~! (ㅈㄴ 신기!!)
> 이렇게 들어가야 ALB 가 HTML 로 변환이 가능한것
> 암튼 이제 Monitoring 으로 이동해서 Log 를 살펴보자
> 참고로, 새로 Code 를 Deploy (람다 함수를) 하면 LogStream 이 바뀐다

> Log 에서 가장 최근 LogStream 을 살펴보고 안에 들어가서 JSON 을 확인해보면, 우리가 ALB 로 접속함으로써 발생한 GET 요청 즉, JSON 포맷으로 변환되어 Lambda 로 전달되는 객체를 살펴볼 수 있다. (그 이유는 코드에서 print(event) 를 해줬기 때문)
> 참고로 위에서 언급했듯이, ALB > TG > Attribute 탭 이동해서 Multi-value-header 을 키게 되면 동일한 key 값에 대한 header 나 query param 은 List 로 묶이게 된다
> Lambda 구성 중 Configuration > Permission 을 살펴보자

>> PolicyStatement 를 살펴보면, ALB 가 이 람다 함수를 Trigger 할 수 있는 Statement 가 지정되어 있음을 알 수 있다 (지정한 ALB 가 ArnLike Condition 으로 들어가 있음)
>>> 사실 가장 헷갈리는 것. 항상 뭔가 바뀌는 것 같음. A 가 B 를 사용할 권한이 있다고 할 때, A에게 B읽기 권한을 주어야 하는건지, B에게 A가 접근할 수 있다는 권한을 주어야 하는건지
>>> Policy, Statement, Role 이런것도 좀 헷갈림!!
----------------------
<279강 - 비동기식 호출 - Asynchronous Invocation >

> S3, SNS, CW Event 등은 비동기식 호출을 사용한다
> 비동기식 호출은 요청에 대한 처리 결과를 기다리지 않는 호출이다. (기존과 약간 다른게, 아예 결과를 안받는건 아님)
> S3 버킷에 새로운 파일이 생기면, 람다 서비스를 트리거 한다고 하자
> 비동기식 호출일 경우, 람다 함수는 들어온 Event 를 Event Queue 에 우선 넣는다
> 이 때 Event Queue 에서 가져와서 람다 함수가 처리하는 도중 error 가 발생하면, 자동으로 재시도를 실시한다
>> 3번의 시도를 하는데 : 1번시도는 즉각 retry 시도, 1번시도 Fail 시 1분뒤 2번시도, 2번시도 Fail 시 2분뒤 3번 시도를 진행
>>> 위와 같이, 람다 함수는 같은 요청을 여러번 처리 시도할 가능성이 있다
>>> 따라서 Processing 이 idempotent 해야한다 (동일한 결과를 retreive 하는 것이 보장 되어야 한다)
>> 함수가 재시도 되면, CW Log 에 Duplicated Log Entry 를 보게 된다
> Retry 끝에도 성공하지 못했다면, DLQ 를 구성할 수 있다 (SQS or SNS). 이렇게 보낼때는 항상 IAM 권한 확인 필수
> 비동기가 사용되는 경우는 다음과 같다
>> 1 사용하는 서비스가 비동기 Invocation 을 사용할 때
>> 2 결과를 기다릴 필요가 없을때 -> 전달 후 다른일 하면 되므로, Speed 가 올라간다
<Async Invocation 하는 AWS Service 종류>
> S3 ( Event Notification 이 람다 함수를 invoke 할 때)
> SNS (Topic 알람을 수신해서 람다 함수를 invoke 할 때)
> CW Event / EventBridge (람다 함수가 반응하도록 연계할 수 있다)
> Code Commit (Commit 이 트리거되어 new branch, new tag, new push 등이 발생할 때)
> Code Pipeline (Pipeline 중에 람다 함수를 호출할 때, lambda must callback)
> 그밖에 CW Log (로그 프로세스), Simple Email Sevice, CF, Config, IoT, IoT Events
----------------------------
<280강 - 비동기식 호출 실습>
> Async 를 실습할텐데, 비동기 호출은 CLI 에서 해야 한다
> result 가 우리한테 전달되지 않는 것이 목표?
$ aws lambda invoke --function-name lecture-lambda-alb --cli-binary-format raw-in-base64-out --payload '{"key1": "val1", "key2":"va2", "key3":"val3"}' --invocation-type Event --region ap-northeast-2 response.json
> 아까와 다르게 invocation-type 을 Event 로 지정해주었다
> 202 결과를 반환하고, 그 외는 반환하지 않는다
> 202의 뜻 : 요청은 받아들여졌으나, 아직 동작을 수행하지 않은 상태.
> CW Log 를 살펴보봐도 Lambda 함수가 trigger 되어 요청 수신은 확인되나, 작업 자체가 성공/실패인진 모른다. (비동기기 때문)
> 코드를 실패하도록 바꿔봐도, 응답은 202 가 되어 온다 (물론 예외시 로그 확인하면 보임)
> Lambda 함수 이동 > Configuration 이동 > Aysnchronous invocation 이동
>> 몇 번의 실패 이후에 DLQ 를 어디로 보낼지 설정 가능! (기본은 3개!)
>> 참고로 이 때 DLQ 연동이 실패한다면, 람다의 Provided Execution Role 이 SQS 에 SendMessage 할 권한이 없기 때문
>> 여기서 봐바. 이 SQS 에 명시를 해줘야 하는건지, 아니면 람다 함수에 명시를 해줘야 하는건지? 여기선 또 람다에 하네 ㅆㅂ ㅋㅋ
>> Lambda 함수의 Config>Permission> Execution Role 이동, 해당 Role 에 Policy 를 추가하는데, SQSFullAccess Policy 를 준다
>> 이제 다시 시도하면 연동에 성공함을 알 수 있다
>> Execption 던지는 요청을 또보냄, 이번엔 Retry 를 2번 하고, DLQ 로 보내게 되는 모습을 확인한다
>>> SQS 로 가서 Poll Message 를 해보면, Body 에 위에 적힌 payload 값이 적혀 있음을 알 수 있다 (보냈던 요청(event)) 가 이쪽으로 오게 됨
----------------------------
<281강 - 람다와 Event / EventBridge 와의 연계>

> 1번은 Serverless Cron / Rate 의 형태로 EventBridge Rule 을 만들어서 Lambda 를 트리거 하는 것이다.
>> EventBridgeRule 을 만들어서, 1시간마다 람다 함수가 Task 를 수행하도록 한다
> 2번은 Codepipeline EventBridge Rule 을 만드는 것이다
>> Pipeline State 가 변경됨에 대한 EventBridge Rule 을 만들어서, state변경시 람다 함수가 TAsk 를 수행하도록 한다
----------------------------
<282강 - 람다와 Event / EventBridge 와의 연계 실습>
> 새로운 함수를 만든다 (lecture-lambda-eb)
> eventbridge 이동, EventBridge Rule 생성

>> Schedule 을 통해 생성되도록 한다 (EventBridge Scheduler 로 가게 되면 EventBridge Rule 이 아닌 Scheduler 로 만들게 되므로, Rule 로 이동) (물론 둘이 하는 일은 똑같긴 함)
> Cron 일정을 1분에 한 번씩으로 변경
> TG 을 람다 함수, 위에서 만든 함수로 설정
> 참고로 이 때 위에 메세지를 보면 : "EventBridge 콘솔을 사용할 때, EventBridge는 선택된 대상에 대한 적절한 권한을 자동으로 구성합니다" 라고 적혀 있음! 권한을 알아서 만들어주는 듯!

> 아까 ALB 에서 처럼, 람다 함수 콘솔에 UI 적으로 EventBridge 가 Trigger 요소 임으로 표시되어 있음

> Config>Permission 으로 가보면, 람다 측에 ArnLike 로 똑같이 조건이 추가되었다 (InvokeLambdaRule 이란 EventBridge rule 이 InvokeFunction 하도록 하는 Permission 이 기재됨) : 아까 위에서 말한 자동 권한 구성된 모습
>> 참고로, 이 [Resource-based policy statements] 를 보면 "오직 EventBridge Rule 만이 이 함수를 Trigger 할 수 있다" 라는 뜻이기도 하다
> 이제 Monitor 탭 > CW Log 로 가보면, Start / End / Report 주기를 벌써 세 번 수행했음을 알 수 있다
> 코드에 print(event) 를 하게 하면 event 로 들어온 JSON 요청을 보여준다 (참고로 Code 를 재배포 했으니 LogStream 이 바뀐다)
>> print 를 보면 detail-type 이 "Scheduled Event' 라고 되어 있다
----------------------------
<283강 - 람다와 S3 Event Notification 과의 연계>
<S3 Event Notification 복습>
> 다음과 같은 발생에 대한 Notificaiton 을 받는 것 : S3:ObjectCreated, S3:ObjectRemoved, S3:ObjectRestore, S3:Replication ...
> Object name filtering 가능 (*.jpg 따위)
> Use Case : S3 에 업로드 된 객체들에 대한 Thumbnail image 를 만드는 것 ( 이 때 대충 람다랑 연동되어용~ 하고 넘어갔던 것 같음)

> 위 그림과 같이 연계 다이어그램들을 그릴 수 있다
> S3 에서 직접 보내는 것은 위에서 배웠든 비동기 호출 (Async) 로 고정되어 있고, 필요시 DLQ 로 연계가 필요하다
> S3 Event Notification 에서는 Events 를 매우 빠르게 전달하나, 가끔 오래 걸리기도 함
> Event Notification 누락이 없으려면, 버저닝을 활성화 해야 한다 - 안하면 동시성 이슈 가능 (single non-versioned object 에 동시에 writes 가 발생하면, 한 건에 Event Notification 만 발생될 확률이 높다)
<S3 Event Pattern 으로 metadata 를 sync 할 수 있다 (예시) >
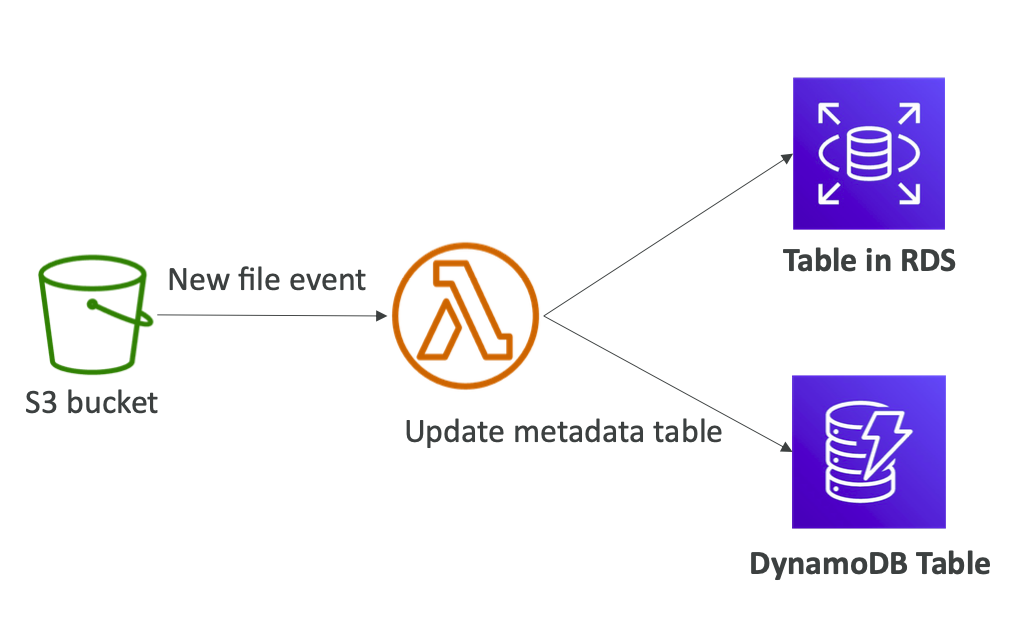
> S3 Notificaiton Event 로 객체 생성 Event 로 람다를 트리거 한다
> 람다는 Processing 하여 RDS, DynamoDB 따위에 Table 을 작업한다 (metadata 넣기)
----------------------------
<284강 - 람다와 S3 Event 실습>
> 함수를 또 만든다
> S3 도 만들고, S3 설정중 Event Notification 설정으로 이동해서 Create 을 한다
>> 이벤트 이름 InvokeLambda, 모든 객체에 대해서 생성 이벤트를 건다
>> 대상을 Lambda / SNS / SQS 중 Lambda 로 설정 후 , 람다 함수 지정후 완료한다
> 다시 람다 UI 로 가보면 역시 Trigger 단이 바뀐다 (코드에 print(event) 추가 후 재업로드 한다)

> 람다의 resource based policy 로 가보면, 자동으로 내가 정한 S3 가 이 lambda 를 trigger 할 수 있는 InvokeFunction 권한을 가지고 있는것을 확인할 수 있다
> S3 로 가서 아무 파일 하나를 업로드 한다 (.jpg 파일)
> Monitor 이동 > Log 이동시, LogStream 이 존재하고, S3 의 Invocation 로그를 확인할 수 있다.
>> 전달받은 event JSON 을 출력시켜서 이를 확인할 수 있음
>> eventSource 가 S3 인걸 알 수 있다 (보내는 리소스마다 event 의 양식은 조금씩 다르기도 한듯??)
>> 이 정보들 (event) 을 토대로, 람다 함수는 GetObject API 따위를 다시 수행하여 원본 객체를 로딩할 수도 있다 > 그리고 그거에 대한 부가 작업 (썸네일 생성 등) 을 수행하고, 추후 Action 으로 연계지을 수 있다
>>> 썸네일 그건 이런식으로 동작하는 거라고만 알고 있으셈. 어쨌든 객체 로딩을 재요청하여 필요한 상황들도 처리할 수 있다!
----------------------------
<285강 Lambda - Event Source Mapping >
> ESM 에 대해서는 시험이 상세하게 묻는다. 하기 내용들을 꼭 이해 & 암기 해야 한다
> 람다가 이벤트를 처리하는 방법 중 마지막 유형
> KDS, SQS (Standard & FIFO) Queue,DynamoDB Stream 에 사용된다
> 이들의 공통점은, Source 로 부터 Record (Data 부) 들이 Poll 되어야 한다는 점이다
>> Lambda 가 서비스에 직접 레코드를 요청해야 그 레코드가 반환된다 (람다가 직접 Polling)
>> 이 경우에는 당연히 람다 함수는 동기 호출을 사용한다

> 람다가 Kinesis 에서 읽기를 하도록 구성하면, Event Source Mapping (Mapper) 이 내부적으로 생성됨
> 이 Mapper 가 Kinesis 로부터 폴링을 시도하는 요청을 보내고 응답을 반환받는 책임을 가진다 (Batch Response)
> 이 Event Batch 를 가지고 Mapping 은 람다 함수를 synchronous invoke 하게 된다.
> 이 EventSource Mapper 는 두가지 형태라고 볼 수 있는데, Stream 용과 Queue(대기열) 용이다.
<Stream 용 Mapper>
1. 성질 및 특성
> Streams - Kinesis & DynamoDB 등에서 활용
>> Event Source Mapping 은 각 샤드 (Kinesis,DynamoDB 에 등장하는) 에 대한 Iterator 를 만들어서, Shard Level 에서 Item 들을 순차적으로 처리한다
>> 읽기 시작하는 위치를 지정할 수 있다
>> 특정 시점 새로운 Item 들에 대해서만 읽을 수도 있고, 특정 타임스탬프로부터 그냥 읽도록 구성, 혹은 처음 위치 부터 가능
>> Event Source Mapping 이 Iterator 로 item 들을 처리한다 해도, Source stream 으로 부터 items 들이 삭제되는 것은 아니다 (다른 소비자도 읽을 수 있음)
>>> 이건 원래 얘네들의 동작방식임! (KDS 기억나지?)
> Use Case : Low Traffic & High Traffic
>> 트래픽 스트림이 낮다면, 람다를 batch window 를 활용하도록 설정해 레코드를 축적하고, 한번에 호출로 processing 을 하여 효율적으로 사용할 수 있게 한다 (람다가 여러 event 들을 한번에 받아서 처리하는 느낌, 그 방식대로 코드를 짜야하는걸까?)
>> 트래픽 스트림이 매우 높다면, 람다를 동시성 (병렬) 처리 설정을 하여 한 샤드에서 여러 배치를 처리하도록 할 수 있다 (아래 그림 참조)

> 샤드가 있고, Record Processor 가 있어서, 한 샤드당 여러 람다 함수가 병렬적으로 Batch Record 들을 처리할 수 있도록 구성할 수 있다
> 샤드당 최대 10개의 Batch Processor 활용이 가능하고, Partition Key Level 로 정렬된 상태로 Batch 처리가 되는 것을 보장한다
>> Partition Key 를 지정하면, 샤드 전체를 순서대로 읽진 못해도 Partition Key 단위로는 순서대로 읽히는걸 보장
2. 에러 핸들링
> 람다 함수가 Error 을 반환하면, Entire Batch 가 Reprocess 된다 (성공까지 or Batch 내 Item 만료시까지)
>> 중요!! 배치 중간에 에러가 발생하면 중단이 발생함!!
> In-Order Process 보장을 위해, 해당 Batch 가 종속된 Shard 의 Processing 은 중단된다 (현 Batch Reprocessing 을 통해 Error 가 해결될때까지)
> 이를 관리하기 위한 수단
>> 1. 오래된 이벤트 폐기 (?) 뭔소리지 >> Discard 를 해도 Destination 설정이 필요하다
>> 2. 재시도 횟수 제한이나
>> 3. 오류시 배치 분할 (배치가 너무 긴것으로 간주되어 람다가 처리하는 시간이 부족한 것으로 판단될 때)
<대기열 용 Mapper>
1. 성질 및 특성

> 아까 봤듯이 ESM 이 Poll 하고 Return Batch 를 받고, 이를 통해 람다 함수가 동기적으로 호출된다
> SQS 경우 ESM 이 Long Pollling!! 을 이용한다 (효율적, batch size 1~10 지정 가능)
>> Queue 설정에 대한 권장사항이 있는데, Queue 의 VT (Visibility Timeout) 을 Lambda 함수 timeout 시간의 6 배로 설정하는걸 권장한다고 한다
> (중요!) DLQ 를 사용하는 경우, SQS Queue 에서 DLQ 를 SU 해야 한다 (람다에서 하는게 아님! 람다에서 DLQ 는 오직 비동기 호출에서 실패처리를 보내기 위해서만 사용된다)
>> Lambda Destination for Failure 로는 설정 가능하다고 하는데 (씨발 뭐 똑같은거 아니냐 위에선 안된다 여기선 된다 ㅅㅂ)
2. 순차처리에 대하여
> 람다는 FIFO Queue 에 대하여 In-order Processing 을 보장한다
>> 뭔소린지 모르겠으나, Scaling 될 람다 함수의 수 = Active Message Group 숫자와 동일: Group ID 설정 (FIFO Queue 에서 했던거인듯? 기억 안남)
>> Group ID 내에서 순차처리를 지원하기 위해서 람다 함수 하나씩 배정해주는 듯 (뇌피셜)
> 당연히 표준 Queue 에서는 In-order 를 보장하지 않는다
>> 표준 Queue 에서 스케일링은 그냥 최대한 빨리 모든 Queue 를 처리하기 위해 Demand 에 따라 Scaling 된다
3. 에러 핸들링
> Batch 는 Queue 에 개별 아이탬으로서 돌아가게 된다(? 걍 다 돌아간단 뜻인가) - Batch 와 상관 없이 실패한것만 돌아간다는거? 아니면 Batch 전체가 돌아간다는거?
> 다시 한번 Queue 에서 처리되길 기다리기 때문에 첫 Batch 묶음과 다른 Batch 에서 처리될 수도 있다.
> 에러가 발생하지 않았음에도 ESM 은 아주 가끔 Queue 로부터 동일한 item 을 수신할 수도 있기 때문에, idempotent? 그 동일입력=동일결과 보장인 함수여야 함
> 어쨌든 Item 이 처리되었을 경우 람다 함수는 Queue 에게 Delete 을 요청하게 된다
> Source Queue 에서 DLQ 구성 가능 (걍 큐입장에서는 기존이랑 동일한건데 .. 처리하는 쪽이 lambda 일 뿐임)
<람다의 ESM 의 Scaling 에 대한 정리>
> Stream 용
>> Stream Shard 당 하나의 람다 함수가 배정된다
>> 병렬 처리 설정을 하면, 한 샤드당 10개의 배치 Processing 이 가능하며, 이 때는 1:1로 람다가 배치된다 (위에 Stream 병렬 처리 그림 참조)
> 표준 SQS
>> Scale Up 이 필요하면 1분당 최대 60개의 람다 함수 인스턴스로 스케일링 할 수 있다 (매우 빠름)
>> 최대 1,000 개의 Batch 가 동시에 처리될 수 있.. 다고 함
> SQS FIFO
>> 같은 Group ID 에 배정된 Message 들은 In-Order 가 보장되어야 한다
>> 따라서 Active 한 Message Group 수 만큼 Scaling 이 가능하다 (넘어가면 Group ID 별로 순서 보장이 어렵다)
(람다가 Group ID 갯수만큼 되어야 in-order 하게 처리하기 때문)
----------------------------
<286 강 - ESM 실습 >
> 새로운 SQS 큐 Source 용으로 생성 (lecture-lambda-esm-sqs), 새로운 함수 생성 (lecture-lambda-sqs)
> 람다로 연동해서 Trigger 설정을 한다 (Batch 설정 및 Enable Trigger 활성화)
>> 이 Batch 속성은 익숙해지는게 좋음!! (Size & Window)
>> Batch Size: 하나의 배치 공간에서 몇 개의 메세지를 가지고 람다를 트리거 할 것인가 (1~최대배치)
>> Batch Window : 하나의 배치 공간이 람다에게 전달하기 전 몇 초동안 메세지를 수집할 것인가 (0 으로 하면 사실 Batch 없는거랑 똑같은 듯. 바로바로 한다는거)
>> 이 둘로 Batch 의 전달을 보장한다
> 이 때, Permission 에러가 떠야 정상
>> 람다의 Execution Role 에 SQS 를 Polling 할 권한이 없기 때문 (ReceiveMessage API 권한이 없음)
>> 항상가던 Permission 으로 이동>Execution Role > Role 로 이동 (IAM) > Role 에 Policy 추가 (AWSLambdaSQSQueueExecuitionRole 있음)

> UI 가 SQS 로 트리거가 바뀌었음!
> Code 에서 event 출력하고, "Sucess!" String 만 반환하도록 변경
> 이제 SQS Queue 에 Message 를 넣어보자!
> hello world 메세지 넣었음 (Attribute 으로 foo/bar 도 넣음)
> 람다는 지속적으로 Polling 을 알아서 하고 있기 때문에, 자동으로 처리할 것임
> LogStream 으로 이동해보면, event 가 출력된 모습을 볼 수 있다
> 이후 SQS Queue 로 가보면 Message Available 이 0인데, 이는 Lambda 가 처리하고 삭제요청까지 했기 때문임
> 참고로 Polling 을 하는 것도 비용이 추가될 수 있으니, ESM 을 해제해라 (걍 연결을 해제하면 됨)
> 걍 KDS, DynamoDB, 대기열 과 연동을 시키면 'ESM' 이 동작을 해주는거임 (이거에 대한 설정이 따로 있진 않은듯)
> 이번엔 Stream 을 해보자. KD 를 Trigger 로 연동해보자 (만들진 않고, Trigger 생성시 구성만 봄)
> Consumer 항목에서는 Enhanced-fan out consumer 가 있는 경우에 대한 것이래 (뭔소린지 모르겠음)
> Batch Size - 100 이 기본 (한번에 읽을 레코드 수)
> Batch Window - 기다리는 것
> Starting Position
>> Latest : 가장 최신의 데이터
>> Trim horizon : 가장 오래된 데이터
>> At timestamp : 특정 시간을 지정해서, 그 때의 데이터
> Additional Setting 에서 아까 배웠던 복잡한 설정들을 제어할 수 있음
>> On-fail (읽지 못하게 된 데이터를 제거 - Queue 나 다른 리소스 ARN 지정)
>> Retry 횟수 / 레코드 수명 (이거에 따라 Error 핸들링을 종료할지를 결정한다고 위에서 얘기함)
>> Split Batch on error 도 가능 (시간 부족하다고 판단시)
>> Concurrent Batches per shard : 트래픽이 많아서 샤드당 여러 배치처리를 하고 싶을 때 (최대 10개였던 그것, 병렬 처리, partition key 그거당 정렬 제공)
> 사실 이런거 다 세부적으로 외울 필요는 없음 (그냥 이런게 있다 정도만)
>> 중요한건 Kinesis 역시 람다 함수의 ESM 이라는 점은 꼭 알고 있으면 된다
----------------------------
<287강 - 람다 함수 내에서 Event and Context Object 에 대해 이해하기>

> 람다 함수가 EventBridge Rule 에 의해 Invoke 되는 상황을 살펴보자
> EventBridge 는 이벤트를 생성하고, 이 이벤트가 람다로 전달된다
> 람다가 수신한 Event 를 Event Object 라고 한다 (관련 서비스, 관련 data 등등)
> 람다 함수에는 Context Object 란 것도 있는데, 함수 자체에 대한 메타데이터임
>> 함수의 AWS 요청 ID, 함수 이름, 로그 그룹, 사용 가능한 메모리양 등
> 두 객체는 서로 다른 정보를 포함하지만, 서로 상호보완적이다
> 두 객체 모두 람다 함수내에서 사용 목적을 가지고 있다
> Event Object
>> 람다 함수가 처리할 데이터를 가지고 있는 JSON 포맷 문서
>> 계속 봤다시피 Invoke 하는 서비스의 정보를 가지고 있다
>> 사용하는 런타임 환경에 따라서 람다가 Data 객체를 변환해서 전달해준다 (Python 경우 dict)
> Context Object
>> Invocation 그 자체, 람다 함수, Runtime 환경 에 대한 정보를 제공한다
>> Runtime 에 람다에게 전달된다

> 우리가 계속 사용했던 Python handler 함수를 보면, param 으로 envet 객체와 context 객체가 전달되는 걸 알 수 있다
> 시험에서 ~~~ 같은 정보는 어디에 있습니까? 하면 골라낼 줄 알아야 한다 (위에 그림에 나온 데이터들이 대표적인 것들!)
>> Event : trigger 장소, 실행된 지역 등
>> Context : 고유 ID, 호출한 함수, 현 람다의 ARN, 메모리 제한 정보, 연결된 log 정보 등
-----------------------
<288강 - Lambda Destination>
> EventMapper 나 Async 호출을 하게 된다면, 요청이 성공했는지 실패했는지 정확하게 알 수 없다는 한계 존재
> 이 결과를 다른 곳으로 전송하는 것이 목적
(중요)
> Async invoke 의 경우 Success & Fail Event 에 대해 각각 Destination 을 설정할 수 있다 (Process 결과에 대한거)
>> SQS, SNS, Lambda, EventBridge Bus (CW Event) 로 보낼 수 있다
>> DLQ 를 세팅하는 것과 비슷하고, 실제로 SQS 에서 DLQ 설정 대신 람다에서 Destination 을 사용하는 것을 권장한다 (더 최신 기능, 더 많은 Target 을 가질 수 있기 때문: DLQ 는 Only SQS, SNS 만 구현체로 지원)
> ESM 의 경우 처리할 수 없는 Event Batch 를 폐기하는 경우 사용된다
>> SQS, SNS 에 전달할 수 있다
>> Kinesis 의 경우 이걸 사용해야 하지만, Queue 같은 대기열 ESM 의 경우, Source Queue 에서 직접 DLQ 를 구성해도 됨 (선택이 있는 것)
-----------------------
<289강 - Lambda Destination 실습>
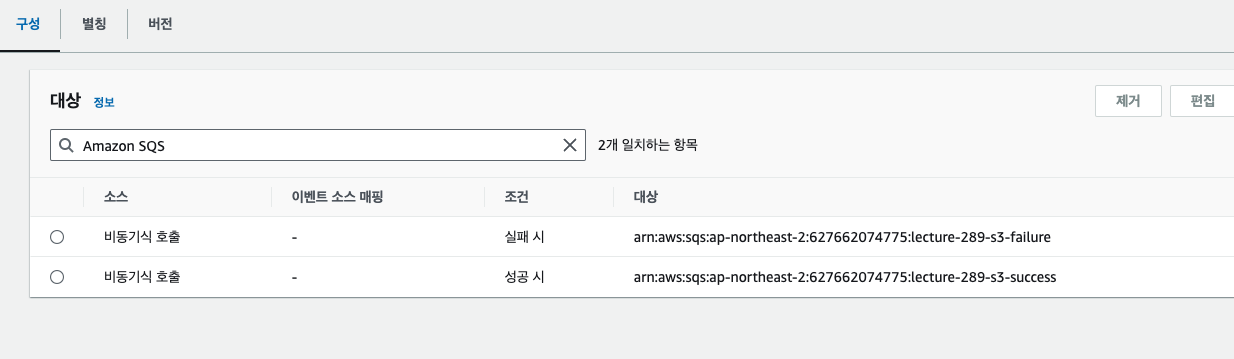
> 예전에 만들었던 S3 함수로 이동해서 +Add Destination 을 해보자 (성공/실패 다 만들거)
> 우선 SQS 두 개 생성 (성공 / 실패)
> Destination Source 는 Async 로 보통 하지만, Stream 형태 (KDS, DDB) 로 설정해도 된다 (큰 상관 없는 듯?)
> On failure 시 실패 SQS 로, On Success 시 성공 SQS 로 이동시켜보자 (권한은 자동으로 추가된다 (람다 함수에))
>> 아까 처럼 자신의 Execution Role 에 Policy 를 추가할거임 (이번엔 자동으로 해준대) (내가 다른 녀석에게 접근해야 하기 때문)
>> 들어가서 확인해보면 "AWSLambdaSQSQueueDestinationExecutionRole" Policy 를 추가해줬음
>>> 근데 해당 항목 안에 "lecture-289-failure" 의 이름을 가지는 S3일 경우만이긴 하다
>>> 근데 성공 Destination 도 추가되면 이름에 "lecture-289-sucess" 도 추가된다
> S3 로 이동해서 객체를 올려보자 (beach.jpg 를 올렸고 성공했음)
> 람다는 trigger 되었을 것이고, 200 Success 가 전달되었을 것이다.
> SQS 로 가보면 S3 Success Queue 에 Message 가 하나 들어가 있다
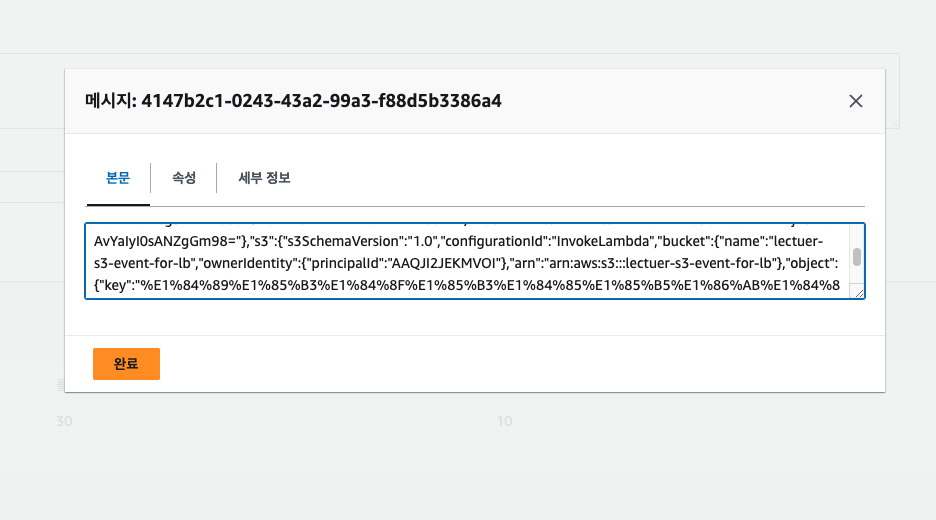
>> 들어가서 Poll 을 해보면, BODY Json 에는 요청 자체에 대한 정보, 람다를 트리거한 event 자체에 대한 정보 (S3 Event Source 였고, Put 이였음 이런거), 람다에서 보내준 Response 등을 확인할 수 있다
>> 목적지에 정말 많은 정보들이 전달되는 것을 알 수 있음
> 실패 경우에는 return 이 아니라 raise Execption 으로 코드를 재배포하고, S3 에서 객체 업로드를 다시 한다
> 그럼 람다가 트리거되나 (비동기라 상관없음) 수행시에는 실패한다
> 그럼 Fail-SQS 에 Message 가 들어가 있는 것라고 추로된다
> 하지만 보면 들어가 있지 않다. 이거 바로 눈치챘으면 좀 ㅅㅌㅊ인데, 람다는 Fail 한 거에 대해서 Retry 를 한다
> Retry 가 두번, 세번 설정되어있으면 그 설정대로 Retry 를 하고, 그 이후에 또 실패할 경우 Fail 로 간주, Destination 으로 보내게 된다
> 어쨌든 시간이 지나면 수신이 된다. Body 를 보면 requestContext.condition=RetriesExhausted (재시도 횟수 소진) 을 볼 수 있다
> 역시 현재 들어온 상태, 처음에 요청 data 정보, response 응답 정보 에 대해서 알 수 있다
>> 참고로 Response 응답에는 Stack Trace 까지 전달해줘서, Debugging 에 참고할 수도 있다 ㅠ
-----------------------
<290강 Lambda 권한 - IAM 역할 및 Resource Policy>
1. Lambda Execution Role
> 모든 람사 함수는 IAM Role 을 가져야 한다
> Lambda 의 IAM Role 을 Execution Role 이라고 한다
> Lambda 의 Execution Role 은 Lambda 리소스가 타 AWS 서비스 / 리소스에 접근할 수 있는 권한을 준다 (람다가 다른 곳에 갈 때는 ER!!)
> AWS 에서 제공하는 Managed Policy 들이 있다
>> AWSLambdaBasicExecutionRole - 람다가(?) CW 에 로그를 업로드하게 해준다 (계속 생성될때 추가되었던 policy)
>> AWSLambdaKinesisExecutionRole - Kinesis 로부터 읽기를 가능하게 해준다
>> "dynamoDBExecutionRole - DynamoDB Stream 으로부터 읽기를 가능하게 해준다
>> "SQSQueueExecutionRole - SQS 로부터 읽기가 가능하게 해준다
>> "VPCAccessExeuctionRole - VPC 내부에 람다 함수를 배포하게 해준다
>> "XRayDaemonWriteAccess - X-ray 에 trace data upload 를 할 수 있다
> 보통 잘 안할 것 같긴 한데, 자체 Policy 를 만들어도 되긴 한다
(헷갈리던걸 좀 정리해 주는 듯?)
> ESM 으로 함수를 호출할 때마다, 람다가 데이터를 읽어와야 하므로, Execution Role (IAM Role) 을 사용해야 한다
> 람다 함수가 다른 서비스를 통해 호출되는 경우라면, Specific Permission (Policy) 을 가진 IAM Role 은 필요 없었다
>> (근데 내 기억으로는 Resource-based policy 에 추가되어야 하지 않았음? 계속 자동으로 생성되던거 ㅇㅇ)
>> 오오 바로 나온다 ㅋㅋ
2. Lambda Resource Based Policy
> 타 계정, 타 AWS 리소스들에게 현재 주체 람다 리소스를 invoke 할 수 있는 permission 을 준다 (Policy 의 역할)
>> S3 Bucket Policy 와 매우 유사 (항상 이런식으로 구분이 되어서 내가 헷갈린듯. 호출자, 호출당함의 관계)
> IAM Principal 가 람다에 접근, Invoke 할 수 있는 경우는 다음이다
>> 1- Principal 에 Attach 된 IAM Policy 가 허용할 경우
>>> IAM User 가 있는데, 관리자라서 그가 모든 Policy 를 가지고 있어서 모든 람다함수에 접근 가능 (우리가 그냥 쉽게 했던 이유, cloudshell 등)
>> 2- Resource Based Policy 를 사용해 해당 람다 함수에 usage 를 authorize 해주는 경우
>>> Service 간 액세스일 때 훨씬 더 많이 사용하게 된다 (타 리소스가 람다를 호출하려 할 경우, RBP 가 허용해줘야함)
>> 콘솔에서 놀 때는 보통 뒷단에서 콘솔이 알아서 해주지만, 직접 설계할 때는 권한, Role, Policy 등등을 직접 잘 설계해야 한다
----------------------
<291강 Lambda 권한 실습>
> Invoke 와 Invoked By 관계에 의한 Execution Role / RBP 의 차이를 이해할 수 있다
> 동기, 비동기, EMS 를 통한 람다와의 상호작용과 각 Policy / Role 의 상태를 이해해야 함
> IAM Role 로 이동하면 Role 에서 내가 만든 모든 lamabda 함수에 Role 들이 생성되고 있었단 것을 알 수 있음
> Execution Role 들을 말하는거임!!

>> Lambda 를 만들면 자동으로 이 Role 을 만들어 주고, 이 떄 AWSLambdaBasicExecutionRole 을 같이 넣어준다 (CW LOGGING 을 위함)
> 필요하면 여기서 제어하면 됨! (Managed Policy 추가하거나, 직접 설계하거나)
> Reource Based Policy 도 확인해보자

>> 람다 함수가 호출되었을 때 (ALB, S3, Eventbridge 정도) RBP 로 가면, 자동으로 생성되었던 것을 볼 수 있음 (강의 도중 다 확인했었음)
>> 참고로 SQS 나 KD 와 같이 EMS 를 이용하는 친구들은, Resource Based Policy 가 없다
>>> 왜냐하면 얘네는 람다 함수가 직접 Poll 을 시도하기 때문이다
>>> 반대로 이친구들은 IAM Role 에 해당 리소스들에 접근할 수 있는 (SQS, KD 등) Policy 가 필요하다
----------------------
<292강 Lambda 환경 변수>
> 람다 구성하기 / 배포하기 측면을 더 살펴보자
> 환경 변수란 String 형태의 Key / Value 묶음으로, Code update 없이 Function 의 행위를 조정할 수 있다
> 람다 서비스는 자체 시스템 환경 변수를 추가해서 사용할 수 있다
> 이 환경변수들을 Encrypt 할 수 있다
> KMS 따위로 암호화 할 수 있다. 이와 같이 Lambda Service Key 로 암호화를 제공하고, 또는 스스로 CMK (Customer Master) 주체가 되어 암호화할 수도 있다
----------------------
<293강 Lambda 환경 변수실습>
> 람다를 만들자 - lambda-config-demo
> 암호화 없는 상태로 실습할거다. 암호화 관련은 나중에 보안 섹션에서 철저히 할 예정
> 간단하게 환경변수를 넣고, 람다 함수가 이를 출력하도록 해보자

> 코드 수정 (간단하게 os import)
import json
import os
def lambda_handler(event, context):
# TOD implement
print(event)
print(os.getenv("hello"))
...
> Configuration > Env Var 로 이동 > 여기서 넣으면 됨
> hello / world 로 넣어보자
> Test 값 넣고 Test 를 해보면, Response 에 "dev" 라고 떠있는걸 확인할 수 있다 (정상적으로 Read)
> 만약 환경변수를 변경하면, 코드는 변경하지 않았는데, 응답이 prod 로 변경할 수 있다
> 환경변수가 원래 동적 영향을 위해서 존재하는 거임 ㅇㅇ
----------------------
<294강 Lambda Monitoring 과 X-Ray 연동>
> 람다는 우선 기본 ExceutionRole 에 CW 접근이 포함되어, 람다의 모든 실행 로그는 자동으로 CW 로그에 저장된다
> Lambda Metric 은 CW Metrirc UI / Lambda UI 에서 확인할 수 있으며, 대표적인 정보들은 하기와 같다

>> Invocation / Duration / Concurrent Execution (람다 여러개 호출되는 것, Demand 높을 때) 등
>> Error Count / Success Rate / Throttles
>> Async Delivery Failures (람다가 이벤트를 처리할 기회를 못얻었을 대) / Iterator Age (Stream 에서)
> X-Ray 를 활성화할 수 있는데, Active Tracing 만 활성화 하면된다
> X-Ray Daemon 을 자동으로 실행해주고, Lambda Code 에 X-RAY SDK 만 활용해주면 된다
>> X-Ray 에게 Write 를 직접 호출하며 하는거니까, Execution Role (IAM Role) 에 X-Ray Access 가능한 Policy 가 있어야 한다
>>> AWSXRayDaemonWriteAccess 라는 Manged Policy 활용하면 된다
>> 필요한 경우 X-Ray 와 환경변수를 통해 소통할 수 있다 (시험에 변수가 나올 수도 있다)
>>> _X_AMZN_TRACE_ID : Tracing Header 정보
>>> AWS_XRAY_CONTEXT_MISSING : 기본은 LOG_ERROR
>>> AWS_XRAY_DAEMON_ADDRESS : X-Ray 데몬 IP_ADDRESS:PORT 가 들어가 있다 (해당 람다 함수의 X-Ray 데몬이 실행되는 IP:port 를 알려줌)
----------------------
<295강 Lambda 모니터링 및 X-Ray Tracing 실습>
> S3 람다 이동 > 모니터링 이동 > Invocation / Duartion / Error count 이런 Metric 을 볼 수 있다
>> Error count / Success Rate 같은 지표는 실제 운영 환경에서 람다가 있을 때 매우 유용합니다
>> 위에 설명과 사진들 같이 두어놨음
> 이미 LogStream 은 많이 살펴봤다. 람다 함수가 수행하는 모든 로그가 다 적히는걸 알 수 있다
>> 가령, RequestID, 함수의 지속 시간, Billed 시간 등등에 대한 REPORT 로그 등등

> X-Ray 에 대하여는, Config>Monitoring&Operation tool>AWS-XRay 를 볼 수 있고, 활성화할 수 있다
>> 람다 함수의 추적들이 X-Ray 에 로깅된다 (당연히 처음에 Permission 없다고 하지만, 활성화 저장하면 Execution Role 에 아까 AWSXRAY 그 Policy 추가되어 있음)
>> 당연히 Role 열어서 확인해줘야함~
< 실제로 해서 X-Ray Trace 사진 참조하면 좋을 듯!>
> 이제 S3 로 이동해서 새로운 객체를 올려보자
> 람다가 이제 함수를 수행할 것임이 예상되고, X-Ray Trace 로 확인할 수 있을 것으로 예상 (Trace 확인은 모니터링 탭에서 X-Ray Trace 보기로 가면 된다)
> Client 가 Lambda 함수를 호출하는 것을 보여줬고, 람다 함수가 동작한 모습을 볼 수 있다
>> 주황색도 있으니까, 동작하지 않았던 부분도 있다는 점도 파악할 수 있다
>> SDK 를 추가하는 경운 Custom 하여 보낼 정보가 있을 대 사용하는 듯! 기본 정보는 그냥 활성화로도 되는듯!
----------------------
<296강 Lambda@Edge 및 CloudFront 함수>
> Customization at the edge..
> 앱이나 함수나 특정 Region 에 배포하는 느낌은 알겠음. 근데 CF 같은걸 사용할 떄는 Edge Location 에서 우리 컨텐츠를 분배하고 있는 상황이다.
> 따라서 앱에 도달하거나, 응답을 Client 에게 전달하기 전, 각 Edge 에서 어떤 Logic 을 처리해야 하는 경우가 있을 수 있다
> 이런 것들을 위해 일반적으로 Edge Function 이라는 기능을 사용한다 (CF 기능)
>> 작성 후 CF Distribution 에 추가한다
>> Users 가까이에서 실행하여 Latency 를 최소화하는 목적
> Use Case : CF 로부터 제공되는 CDN 을 customizing 하는 것
> Edge Function 은 두 가지가 있다
> CF Function & Lambda@Edge > 둘의 차이, 필요성의 차이를 이해해야함
<대표적인 Use Case 들>

> 구체적인 설명은 없었으니, 위 글 사진으로 대체, 한번씩 읽고 아~ 하면 됨
<CF Functions>

> Client 가 CF 에게 요청을 보내는데, View 측이기 때문에 Viewer Request 라고 부른다
> CF 는 이에 대하여 Origin Request 를 보내고 Origin Response 를 받는다
> CF 함수는 JS 로 작성된 가벼운 함수고, Viewer Req/Resp 를 Modify 하는 용으로만 사용한다
>> 내가 쓸 일은 없을 것 같긴 하지만, high-scale / latency-sensitive CDN 을 위해 사용된다
>>> High Performance, High Scale 용
>> 각각 Origin Req 로 보내기 전, Viewer Resp 자체를 보내기 전에 Modify 한다
> CF 와만 연계된 기능으로, Managed Entirely in CF including all codes
<Lambda@ Edge>

> 비슷하지만 조금 더 섬세한 제어를 위함. Node JS /Python 을 사용하는 함수
> 1000 req./sec 까지 스케일링 해줄 수 있다
> 4가지 요청을 다 제어할 수 있다 (근데 Viewer Req,Origin Req 단에서 제어한다는게 결국 똑같은거 아님..?)
> 람다 Function 을 관리하는 한 지역에서 함수를 작성 / 등록하면, CF 는 이 함수를 자신이 사용하는 모든 Edge Location 에 복사해서 배포한다

> 둘의 가장 눈에 띄는 차이는 Runtime 지원 (언어 지원이 다름)
> 규모 측면에서는 CF 가 훨씬 더 큰 규모 용이다 (초당 수백만개의 요청)
> Modify 가능한 Req/Resp (Lambda@Edge 는 Origin 단도 제어가능)
> 수행 시간 역시 CF Function 은 고성능이기 때문에, 1ms 이하로 수행을 가져간다 (간단한 Logic 을 위해서 사용하는게 적합)
<각각의 대표적인 Use Case >
> CF Function
>> 캐시 키 정규화(normalization) : 요청 Attributes 를 변환하여 최적의 Cache Key 를 만든다
>> Header Manipulation : Insert/Modify/Delete HTTP Header
>> URL Rewires / Redirects : URL 을 수정, 리디렉션 지정도 가능
>> Req Auth/Auth : JWT 토큰 검증을 추가할 수 있다 (굳이 앱단까지 가지 않더라도 allow/deny 를 1차 검증)
> Lambda @ Edge
>> 실행 속도가 훨씬 오래까지 잡고, CPU/Memory 를 조정 가능해서 많은 라이브러리 사용가능 (좀더 복잡한 작업 가능)
>> Code 자체가 다른 AWS 서비스를 제어하는 AWS SDK 일 수도 있다 (즉, 외부까지 봄, 아래 나오네 ㅋㅋ)
>> Network access to use external services for processing (다른 서비스에 외부 요청을 날릴 수 있다는 거인듯)_
>> 파일 시스템 액세스를 제공, HTTP 요청 본문에 접근할 수 있다 (Customization 추가)
> 아우 별 개같은게 다있네~~ 싶음
----------------------
====================================================================================
교육 출처
- AWS Certified Developer Associate 시험 대비 강의 - Udemy
'웹 운영 > AWS' 카테고리의 다른 글
| [CDA] 섹션 22 - AWS 서버리스 : Dynamo DB (0) | 2024.09.01 |
|---|---|
| [CDA] 섹션 21 - AWS 서버리스 : Lambda (II) (0) | 2024.08.19 |
| [CDA] 섹션 20 - AWS 모니터링 및 감사 (Audit): CloudTrail (0) | 2024.08.10 |
| [CDA] 섹션 20 - AWS 모니터링 및 감사 (Audit): CloudWatch, X-Ray (0) | 2024.07.30 |
| [CDA] 섹션 19 - AWS 통합 및 메시징: Kinesis (0) | 2024.07.25 |



