<297강 VPC 와 람다 - 좀 빡센 부분임! Networking 영역!>
> 람다 함수의 networking 에 대해서 좀 더 살펴보자
> 람다 함수는 기본적으로, 너의 VPC 에서 배포되는게 아니라, AWS-owned-manged VPC 에서 배포된다
>> 따라서 너의 VPC 에 있는 Resource (RDS, ElastiCache, internal ELB 등) 에는 접근할 수가 없다!!

> 위와 같은 양상을 기본적으로 띈다
> 외부 Websited (외부 API 사용 가능) 은 접근 가능, Dynamo DB 와 같은 서비스 접근 가능
>> 하지만 자체 VPC, 자체 서브넷 내에서 운영중인 RDS 와 같은 건 접근할 수 없다!
>> 그래서 이런게 필요할 경우, 람다 함수를 자체 VPC 에서 배포해야 한다
<Lambda In My VPC>
> VPC ID / Subnet / SG 등을 잘정의해야 한다
> 우리가 선택한 서브넷에, Lambda 는 네트워킹을 위해 ENI 를 설치한다 (Network Interface)
>> 따라서 Lambda 에게 ENI 를 설치하고 SU 을 할 수 있게 해주기 위해 당연히 Execution Role (IAM) 이 필요하다
>>> Managed Policy 인 AWSLambdaVPCAccessExecutionRole

> Private Subnet 내에 RDS 리소스에 RDS SG 가 존재
> 이 때 Lambda 가 VPC 안에서 배포되면, 각 서브넷 단위로 접근하기 위해 각각 서브넷의 ENI 를 만든다 (Lambda(ENI) 가 SG도 제어한다)
> 이렇게 Lambda 는 ENI 를 통해 RDS 와 통신할 수 있다
>> 당연히 RDS SG 는 Lambda SG 를 허용해야 한다
> 그럼 이렇게 사설망에 된 람다는 외부 공용 Interntet 에 대한 액세스가 가능한가?
> 사설 VPC 안에 있는 람다 함수는 당연히 외부 인터넷 접근을 할 수 없다
>> 그러면 Public VPC 에 배포하면 되겠네 ㅋㅋ 그럼 Internet Access & Public IP 가능하겠다
>>> EC2 의 경우는 이게 가능하지만, 람다함수는 이걸로도 안됨 (이거 무조건 시험에 나오는 내용) > Public VPC 에 배포해도, 람다는 외부 인터넷에 접근할 수 없음!

> 따라서 람다 함수를 Private Subnet 에 배포하고, NAT Gateway / Instacne 를 두어야 함 (이게 유일한 방법이다)
> Private VPC 안에서 필요한 리소스들과 협력은 한다
> 그리고 외부 Public Subnet 에 있는 NAT Device 를 통해서 외부 인터넷 / API 와 상호작용해야 한다
>> 위 그림처럼 NAT Gateway Instance 는 ING (Internet Gateway) Instance 를 통해서 외부 API 에 대한 액세스를 열어주게 된다
>> 이런건 라우팅 테이블, VPC 구성을 통해서 설정해야 한다
> 지금은 위에 있는 사항을 다 외울 필욘 없는 듯. VPC 네트워킹 등에 대해서 이 시험에서 세부적으로 다루진 않음
> 그렇다면 위 그림 처럼 DDB 에 접근하고 싶으면?
> NAT 가 구성된다면, Public route / IGW 를 통해서 액세스 가능하다 (똑같은듯?)
> 혹은 DDB 를 Private 하게 접근하고 싶으면, VPC Endpoint 를 사용하면 된다
>> VPC Endpoint 는 NAT, IGW 등을 사용하지 않고도 Cloud 내 AWS 서비스에 액세스 할 수 있게 해준다 (VPC 섹션에 나왔다고 함ㅋㅋ)
> 따라서 위 그림처럼 DDB 를 위한 VPC Endpoint (Gateway) 를 만들어준다
>> 참고로 Private 에 배포해도 CW Log 는 잘 생성된다 (NAT/IGW/VPC EP 없이도)
----------------------
<298강 VPC 와 람다 실습 >
> lambda-vpc 라는 함수 작성.
> EC2 콘솔 이동, 람다 함수를 위한 SG를 만들어 줄 것이고, 현재 있는 VPC 에 생성한다 (인바운드/아웃바운드 없이)
> 이제 만든 Lambda 함수를 사설 VPC 에 배포해보자

> 람다>Config>VPC 이동해서 이동 가능 (WARNING 확인시, VPC가 제공하지 않는한 외부 Internet 연결 없다고 뜸)
> 각 AZ 세 개의 서브넷에 배포함
*** 참고 ****
>> 사실 보통 VPC 내에서 람다 함수를 배포할 때는 VPC 내부 리소스에 대한 접근이 필요해서임
>> 굳이 외부 인터넷을 사용할 일이 많진 않을 거다. 보통 RDS DB, Elastic Cache 등에 접근해서 로컬 작업하기 위해서 함
> SG 는 아까 만든걸로 했다.
> 이렇게 생성하면 에러가 뜸

> 아까 말했듯이, 이거를 하기 위해서는 서브넷에 ENI 를 람다 함수가 만들려고 하기 때문에 권한이 필요하다
>> Execution Role 에 추가하러 갔다오면 됨 (아까 강의에선 다른거였던 거 같은데.. 여기선 AWSLambdaENIManagementAccess 정책 추가함)
> 이제 사설망에 VPC 배포를 성공하였다! 이제 RDS DB, Elastic Cache 등에 접근할 수 있다
> 외부 인터넷 접근까진 실습하지 않음
> EC2 > ENI 로 이동해 보면 내가 서브넷 지정한 만큼 ENI 가 형성되어 각 서브넷에 람다와의 통신을 담당하게 된다
----------------------
<299강 Lambda 함수 성능과 개선>
> RAM
>> 지금까진 128 MB 를 사용했으나 1MB 씩 증가 가능하고 10GB 까지 가능하다
>> RAM 성능이 증가할 수록 vCPU 도 증가한다 (vCPU 는 직접 설정은 불가하다) - 중요
>> 가령, RAM 이 1792MB 도달하면, 그제서햐 1개의 완전한 CPU 를 사용한다
>> (중요) 이 이상부터는, CPU 가 늘어난 것이므로, multi-threading 을 사용해서 늘어난 CPU 의 이점을 살리는게 좋음
>> 따라서, 람다 함수가 CPU 가 너무너무 중요해요. 빠른 연산을 해주고 싶어요 어떻게 해요?
>>> CPU 를 늘린다 하면 틀린거임. RAM 을 늘려야 함
> Timeout
>> 기본적으로 람다 함수는 실행 이후 3초가 지나면 TO 로 판단하고 오류를 뱉는다. (최대 900초 (15분) 까지 설정 가능)
>> 15분이 넘는 연산은 람다를 활용하기에 적합한 상황이 아니라는거임
>> 문제 : 내 연산이 15분으로 설정해도 자꾸 TO 가 납니다. 어떻게 해요?
>>> Lambda 를 안쓰는게 좋은 상황인 것임. Fargate / ECS / EC2 를 구성해서 돌리는걸 권장
<Lambda Execution Context>
Context 를 좀 더 이해해보면 좋을듯 (이게 그래도 분야마다 또 너무 다름 뜻이)
> 코드 실행의 배경이 되는 환경 정도를 말한다
> 람다 함수가 호출이 되었음. 그리고 종료가 되었음
> 그리고 또 호출이 되었음. 이 때 Execution Context 가 유지된다고 함?
> 그럼 도대체 호출의 간격? 이런게 있는거임? 아니면 호출이 유지되는 동안 또 된다는거임?
> 이게 Lifecycle 의 경계에 대해 명확히 설명해주진 않음. 일단 실습까지 들어보자 (지피티 상 정확하게 공개하진 않았다고 함)
> Temporary Runtime Env 로, 람다 코드의 외부 의존성을 시작하는 것을 말한다(?)
> 이 컨텍스트를 사용해서 DB 접속, HTTP Clients, SDK Clients 등을 활용할 수 있는 겄!!
> 이 기능의 좋은 점은, 또다른 람다 함수가 사용할 것을 대비해, 이 컨텍스트가 잠시 유지된다는 점
>> 따라서 연속으로 Lambda 함수를 호출하면, 컨텍스트는 기존의 모든 DB 접속, Http 클라이언트, SDK Client 등을 재사용 할 수 있다는 것
>>> init 해주는 시간을 절약해 줌으로, 정말 많은 시간을 save 해준다!!

> 위 모습은 Execution Context 를 사용하고 있는 모습이다.
> 좌측은 좋지 않은 사례인데, 환경 변수로 DB URL 을 받는 것까진 좋은데, 바로 db.connect 를 쎄려버린다.
>> 이는 람다 함수가 실행될 때마다 DB 연결을 하기 때문에 효율적이지 못한 것이다
> 모범 방식은 우측과 같다. handler 외부에서 DB 접속을 수행하면, 접속이 한번만 초기화 되고 re-use 가능하기 때문이다
> 외부에서 하는게 걍 Execution Context 쓰는 거인듯? ㅋㅋ
>> 시험 문제에서 이렇게 DB 접속, Http Client, SDK Client 가 열리는 곳 등을 어디서 할지 물어볼 수 있음
>> (그냥 결론) Init 을 하는데 오래걸리는 함수 수행은 바깥에 두고 재사용 하는게 모범
<Execution Context 의 비밀(?)>
> Execution Context 에는 /tmp 디렉토리가 있다 (약간 Pod 의 임시 Volume 같음) (위에서 활용되는 원리?)
>> 이 디렉토리는 유저가 파일을 작성할 수 있는 공간, 실행 중 파일 IO 로 사용될 수 있는 공간이다
>> Use Case : 작업을 수행하기 위해 파일 다운로드 필요 or 디스크 공간이 필요 > /tmp 에 저장후 지속 조회 후 사용하면 된다 (솔직히 깊이 들어가면 잘 모르겠음 ㅋㅋ)
>> 람다 함수가 수행될 때는 10GB의 공간이 할당되고, Execution Context 가 유지되는 동안에는 살아 있는 공간이다
>> Provides Transient Cache :: 해당 공간에서 똑같은 파일들을 다시 찾을 수 있고, 재사용 할 수 있어서 많은 시간을 절약하게 된다
>> 당연히 영구는 S3 사용해야함
>> 참고로, /tmp 공간에 있는 content 를 암호화 하고 싶으면, Lambda 기능으로는 어렵다. KMS Feature 을 사용해서 실제 암호화를 직접 해야한다
---------------------------
<300강 - Lambda 함수 성능 실습>

> Config 에 가서 Memory 양을 조절해 볼 수 있다 (CPU 도 자동조절)
>> 함수의 메모리 사용량을 잘 모니터링해서 비용을 최적화 할 수 있는 것이 중요함
>> 유명한 문제는 아까 말했듯이 CPU 더 필요하면 어떻게 해야합니까? 메모리 건드려야 함
> Timeout 설정도 둘 수 있음
>> import time 을 해서 time.sleep(2) 를 해봄.
>> sleep 을 3초로 변경하자 Error Message: 3.00 초 이후 TO 이 발생했다고 뜸
>> 그래서 timeout 을 5초로 바꿔서 재기동하니, Execution 이 정상적으로 동작했다
>> FAQ :그럼 그냥 항상 10분 15분 두면 안됩니까?
>> ANW : 에러 발견이 늦어질 수 있다. 가령, 10초만에 에러가 발생한건데, 데드락인데 될 수도 있으니 람다가 10분 15분 기다리는 수행일 수도 있다
> 이제는 Execution Context 대해 얘기해보자
> 위에서 봤던 것처럼, handler 바깥에 connect_to_db() 와 같은 initailizing 과정을 두는게 적합
def connect_to_db():
time.sleep(3);
> 이 함수를 두고 handler 안에 두고 연속적으로 Test 를 수행해보면, 매 수행마다 3초가 걸린다
> 하지만 이번엔 바깥 쪽에 둬봤음
>> 그리고 다시 Test 를 또 보내보니, 바로 결과가 나온다. 1ms 이하!
>> Execution Context 영역 (handler 외부) 은 re-use 하기 때문임
>> 실습을 봐도 그 "경계"? 가 뭔지는 잘 모르겠음..
---------------------------
<301강 - Lambda Layers>
> 두가지 기능을 제공한다
> 1 - Custom Runtime 을 지원해준다. (Lambda 를 위한 언어가 아니더라도 Layer 을 통해 가능하다)(? 도커 같은겄?)
>> C++, Rust 같은 언어들이 대표적인 예시
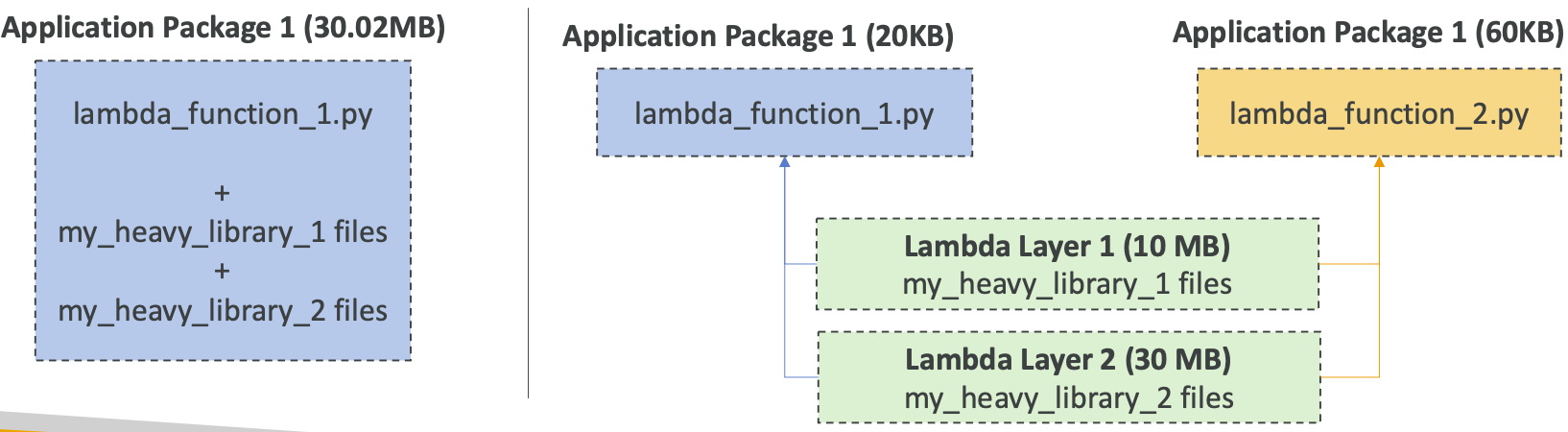
> 2 - 종속성을 다시 사용할 수 있게 외부화 (Externalize Dependencies for re-use)
>> 완전 Docker Image Layer 와 같은 부분!!!
>> 람다 함수를 Pacakging 해서 배포해도 꽤 무거울 수 있다 (람다 함수, 여러 파일, 외부 라이브러리 등등)
>> 람다 함수 업데이트를 위해선 이 heavy 파일을 계속 패키징하고 업로드를 해줘야함
>> 하지만 보면 사용하고 있는 라이브러리나 external dependency 들은 안바뀌거나 거의 바뀌지 않는다
>> 위 그림처럼, 함수에서 참조할 수 있는 Layer 화하여 구성? 을 하는 것. 훨씬 빠르게 배포 가능, 매번 패키징 불필요
>> 또한, 계층이 외부화되어 있으므로, 다른 Lambda, 다른 Package 따위에서도 동일한 계층을 참조할 수 있다.
---------------------------
<302강 - Lambda Layers 실습>
> Layer-demo 함수를 만든다
> 계층에 대해 공부는 했지만 실제 계층을 직접 생성하는 것은 매우 복잡. 따라서 AWS 제공 계층을 통해 작동 방식을 보자
> https://aws.amazon.com/ko/blogs/aws/new-for-aws-lambda-use-any-programming-language-and-share-common-components/
> 여기 중간에 있는 python 코드를 활용한다

> 현재 UI 콘솔을 보면, 람다아래 Layers(0) 이라고 적혀 있다
> 맨 아래 오면 Layer 를 Edit 하거나 추가할 수 있다
>> ADD Layer>AWS Layers 를 하고, Python38-SciPy 를 선택
>>> 이게 무슨 뜻이냐면, 이미지랑 똑같은거임 : Lambda 함수에서 사용할 수 있도록 Python 3.8에 맞게 SciPy 라이브러리를 컴파일한 계층이다 (컴파일?)
>>> 바로 이 라이브러리를 참조해서 쓸 수 있다
>>> 아까 복사한걸 붙여주고, numpy 를 import 하고, scipy.spatial 을 참조할 수 있다는것을 알 수 있다 (따로 람다 내부에 있지도 않은데 참조가 가능하다)
>>> 이 함수들은 우리가 애플리케이션 패키징에 포함시키지 않은 Library 들인데도 참조할 수가 있다는 것!
>> 실제 Deploy 해보고, 동작하는지 확인해봤는데, 잘 동작함을 확인할 수 있다. (numpy, Scipy 를 잘 활용하고 있다)
> 중요한 건, 우리가 import 한 것들이 있는데, 그 함수들은 미리 추가한 Lambda 계층에 있는 라이브러리를 사용했다는 것
> 실제 lambda 함수는 매우 간단하고, Deploy 할 때도 이것만 배포하면 된다는게 Layer 의 가장 큰 장점
---------------------------
<303강 - Lambda 파일 시스템 마운트>

> 람다 함수들은 (자체 VPC 에서 런닝시) EFS 파일 시스템에 접근할 수 있다
> INIT 도중 로컬 디렉토리와 EFS 시스템을 Mount 해주면 됨
> EFS Access Point 를 활성화해야한다 (이게 NFS 인듯?)
> 한계점은, 한 람다 함수 인스턴스마다 하나의 연결을 가져가게 된다 (람다가 매우 많이 실행되는 상황일 경우 connection burst 가능)

> Ephemeral 같은 경우에는 /tmp 를 말하는 것으로, 람다 함수 인스턴스가 종료되면 사라진다 (임시)
>> 가장 빠른 Data Access 방법이며, Invocation 끼리 공유할 수 없고, 함수에서만 접근 가능하다. (아깐 재사용이 장점이래매 ㅆㅂ) (그니까 그 재사용되는건 Invocation 의 단위가 아닌 느낌임)
> Lambda Layers
>> 보관가능한 속성을 가지고 있다
>> 람다 Function 에 제공 Storage 에 attach 되어 있으므로 Layer 역시 Data Access 속도가 매우 빠르다.
>> Invocation 간 공유가 가능하다 IAM 권한을 통해 Share 가능하다 (나머지 모드는 다 가능)
>> 하지만 Layer 에 있는 데이터를 Modify 할 수는 없다
> S3
>> IAM 권한 필요, 빠르긴 하지만 넷 중 제일 느림
> EFS
>> IAM + NFS (Network File System 으로서 Mount 되기 때문에, NFS 가 필요하며 Very Fast 한 속도를 제공)
------------------------------------------
<304 강 Lambda 의 동시성>
> 람다함수는 호출할수록 동시에 발생하는게 많아진다 (람다 함수는 Scaling 이 빠르기 대문이다)
>> Demand 가 많다면, 최대 1000 개의 동시 실행이 지원된다
> 굳이 왜하는진 모르겠는데, 발생할 수 있는 동시 실행자의 갯수를 Limit 할 수 있다
>> "Reserved Concurrency" 설정을 통해 가능 > 함수 레벨로 등록, 이 함수는 최대 50~100 개의 동시 실행만 가능! 이런식식
> Concurrency 를 넘어선 invocation 은 "Throttle" 을 발생시키게 된다
> Throttle 은 종류에 따라 다르게 반응한다
>> Sync Invocation 이였을 경우 >> 429 statusCode 를 반환하여 ThrottleError 임을 알린다
>> Async 이였을 경우 >> 재시도를 자동으로 진행 후 , 실패시 DLQ 로 이동시킨다
>> 1000 개 이상의 동시실행이 필요할 경우 "support ticket" 을 통해 가능 (문의하라는건가?)
<Lambda Concurrency Issue> - 동시성 문제!

> 위 상태에서 어떤 프로모션을 진행해서, 많은 유저들이 ALB 를 통해 람다함수에 접근한다고 하자.
> ALB 를 통한 람다 함수는 굉장히 많이 호출되어, 1000 개의 동시 호출을 거뜬히 넘었다고 하자
> 스케일링 한것 까지는 좋음..!! 근데 람다 함수가 위에서 다 썼기 대문에, 다른 두 개의 방안을 사용하는 유저들은 "Throttle Error" 를 반환받는다
> 해결방안도 말해줘야지 ㅋㅌㅋㅋㅋㅋㅋ (concurrency limit 해도 함수당 리밋이기 때문에 똑같은거 아님???)
<Concurrency and Asynchronous Invocation>

> 비동기 호출시 Throttle 상황일 때 어떤 단계를 거치게 되는지 좀 살펴보자.
> 여러 객체를 업로드 했기 대문에 람다 함수가 여러번 Trigger 되었다고 해보자
> 위와 같은 상황에서 1000개 까지 스케일링되거나 (아니면 설정한 limit 에 도달하여) Throttle 상황이라고 해보자
> 이 때, Throttling error 나 그 어떤 에러에 대해서, 람다 함수는 Queue 에게 Event 를 반환하고, 최대 6시간동안 함수를 재시도 한다 (설정해둔 DLQ 가 있다면인 부분? 필수적으로 설정해야 했나? ㄴㄴ 필수는 아니였던 듯)
>> 이 때 retry interval 은 지속적으로 증가 (기하급수 증가, 1초, 2초, 4초, 8초,...) 최대 5분까지 증가한다
>> 이건 그냥 비동기 호출의 에러 상황을 복습한 부분,,?
<Cold Starts & Provisioned Concurrency >
> Cold start
>> 새로운 람다 인스턴스를 기동할 때, 코드가 로딩되고 handler 바깥에 (그 execution context) 있는것들까지 다 실행하며 init 을 한다
>> 이 때, init 과정이 무거워서 (코드 많거나, 종속성 많거나, SDK 가 복잡) 좀 시간이 걸릴 과정일 수도 있다
>> 이 새로운 인스턴스를 기동시킨 "첫 요청" 은 훨씬 높은 Latency 를 가지게 된다. 이걸 Cold Start 현상이라고 한다
>>>>> (Lamda Instace 와 Lambda 요청의 차이를 모르겠음.....!!!!!! 그 기준이 뭐임?? 몇 초뒤엔 새로운 인스턴스 이런게 있음??)
>>>>> 이거 지피티한테 물어봤는데 명확한 기준이 제공되고 있진 않다고 함
> Provisioned Concurrency
>> cold start 에 대한 해결방안으로 사용된다
>> allocate concurrency before the function is invoked (미리 동시성을 배치..? 걍 미리 실행한단 뜻인가?)
>> 이 방법으로 Cold Start 는 방지되고, 모든 호출은 낮은 Latency 를 갖게된다 (cold start 를 request 와 독립적으로 가져가는 느낌이긴 한데 잘 모르겠음)
>> Application Auto Scaling (Schedule or target utilization) 을 사용하여 lambda function 이 throttle 되지 않은 상황을 보장하려고 노력할 수 있다
>> 걍 Provisioned Concurrency 를 사용해 Cold Start 를 방지할 수 있다고 외워만 두자.. 이해하기 시름..
> Note:
>> 자체 VPC 에서 실행하는 람다 함수의 Cold Start 는 2019 년 이후로 대폭 개선됨
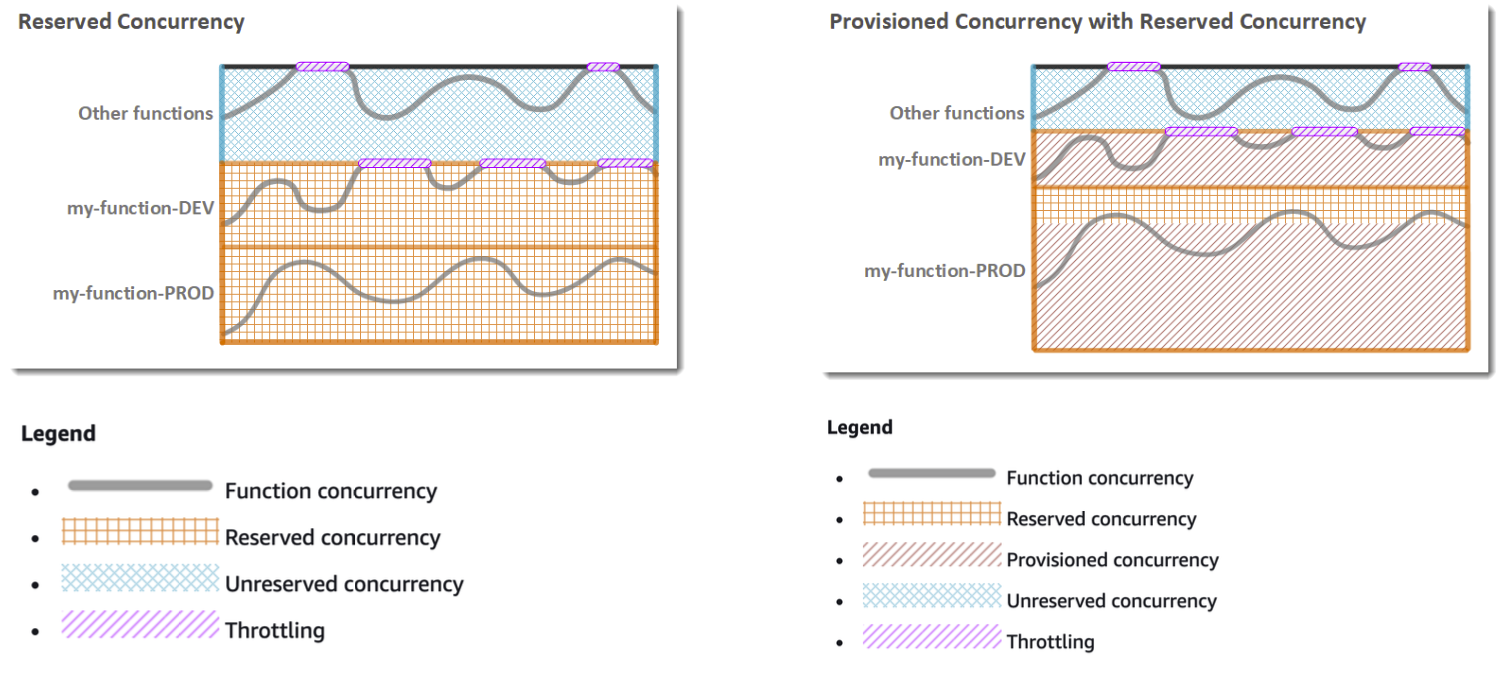
> 스스로 이해해보라고 함
> 일단 Other function 영역은 무시해도 될듯?
> 한계를 정해놓은 Reserved concurrency 만 사용하면, 제일 처음에 속도가 느린 느낌임 (Init 과정)
> 오른쪽을 보면 Provisioned Concurrency (대충 Init 해놓은 거라고 이해하자) 를 쓰기 때문에, Concurrency 를 훨씬 잘 다룰 수 있다는 도표인 것 같음 (더 많은 호출을 처리할 수 있음?)
------------------------------------------
<305 강 Lambda 의 동시성 실습>

> Config > Concurrency 탭 있음 > 현재 기본은 동시성 지원 400 으로 인하된듯
>> 예약 Concurrency 를 0으로 바꾼다음에 Test 를 하면 throttle 이 발생하는 모습 확인 가능
> Provisioned Concurrency Configurations (프로비저닝된 동시성 구성)
>> Cold Starts 를 최대한 방지하기 위해서 사용
>> 5개를 Provisioned concurrency 로 설정하면, 5개가 미리 init 을 해주는거..? 정확히 이해하진 못함
>> 이거 나중에 더 실습한다고 함
------------------------------------------
<306 강 Lambda 함수 (외부) 종속성>
> 지금까지 실습한 바와는 다르게, 보통 너가 람다를 사용할 때면 외부 종속성이 무조건 있을 것이다
> 가령, X-Ray SDK, DB Client 등만 하더라도 외부 의존성이 있는 것
> 코드와 함께 패키징을 해서 업로드 하게 된다
>> Node.js 는 관련된 npm, node_modules directory 연동
>> Python 같은 경우 pip --target 옵션
>> Java 같은 경우 필요한 .jar 파일 연동
> 모두 함께 zip 패키징 한 것이 50MB 이하라면 바로 람다에 올리면 되고, 아니면 S3 를 통해 업로드 해야 하는 듯
> Native Libraries 들은 람다가 보통 실행된 운영체제인 AWS linux 에서 컴파일 가능해야 한다
> 참고로 AWS SDK 같은 경우는 기본적으로 람다 함수에 제공되므로 AWS SDK 사용은 그냥 하면 됨
------------------------------------------
<307 강 Lambda (외부) 종속성 실습>
> 솔직히 실습하는 내용이 뭘 알아보려는건지 잘 모르겠음 ㅋㅋㅋ Cloud Shell 에서 ZIP 한 내용을 람다 함수로 올리는 영역?
> 지금까지 한 내용은 람다 콘솔에 직접 썼지만, 일반적으로는 필요한 코딩을 직접 한다음에 람다로 띄울 것이라는 부분인 듯
> 그래서 아마 로컬이나 이런곳에서 돌릴테니, 외부 의존성을 사용하는 람다 함수들을 보여주고, 이걸 ZIP 해서 올리는 것. 그리고 위에서 말했듯이 50 MB 넘어가면 S3 에 업로드
// Require the X-Ray SDK (need to install it first)
const AWSXRay = require('aws-xray-sdk-core')
// Require the AWS SDK (comes with every Lambda function)
const AWS = AWSXRay.captureAWS(require('aws-sdk'))
// We'll use the S3 service, so we need a proper IAM role
const s3 = new AWS.S3()
exports.handler = async function(event) {
return s3.listBuckets().promise()
}
또한 다음 Step 에 따라서 진행하고, 아래 설명도 같이 된다
#!/bin/bash
# You need to have nodejs / npm installed beforehand
npm install aws-xray-sdk
npm install aws-sdk
# Set proper permissions for project files
chmod a+r *
# You need to have the zip command available
zip -r function.zip .
# create the Lambda function using the CLI
aws lambda create-function --zip-file fileb://function.zip --function-name lambda-xray-with-dependencies --runtime nodejs14.x --handler index.handler --role arn:aws:iam::001736599714:role/DemoLambdaWithDependencies
> 강의 제공 파일 중 lambda.with-dependencies 경로를 확인
> cloudshell 을 쓸 건데, Cloud shell 은 기본적으로 npm 또한 깔려 있음
> 람다 폴더를 만든다
$ mkdir lmabda && cd lambda
$ sudo yum install -y nano 를 설치
$ nano inedex.js 를 통해 제공 파일 중 index.js 를 복붙한다
> index.js 를 살펴보면 XRay SDK, S3 SDK 가 필요하다
> step 에 나와 있는 순서대로 한다 (npm install xraysdk, chmod a+r *, zip 을 통해 현재 경로에 있는 모든 파일을 zip 으로 만든다)
>> npm 관련 파일, 의존성 package 들, index.js 소스코드 파일 등
> npm install 을 하면 현재 디렉토리 기준으로 SDK 를 받아와서 node_modules 디렉토리를 만들고 pacakge-lock.json 을 만들어 준다 (이건 NPM 의 동작방식!)
> 따라서 zip 까지 수행하면 현재 만든 lambda 디렉토리에는 zip 파일, js 파일, node_moudle 디렉토리, json 파일 총 4개가 보여야 함
> 이제 이 zip 을 업로드해야 한다
> CLI 를 사용할 수 있음
>> CLI 를 통해 업로드 할 때 IAM Role 도 같이 전달이 필요하다 (이거 람다 만들면 기본적으로 execution role 추가해줬던거를 이번에 CLI 로 직접하는거임!)
>> 새 Role 만들거임, Lambd 용 선택, AWSLambdaBasicExecutionRole 추가, lecture-307-lambda-basic-role 이름으로 추가
>> ARN 복사해서 --role 뒤 param 에 붙여 넣는다
$ aws lambda create-function --zip-file fileb://function.zip --function-name lecture-307-function-with-xray-dep --runtime nodejs14.x --handler index.handler --role {ARN}
> 해당 명령을 아까 그 디렉토리에서 실행 후 Successful 확인, 콘솔에서도 생긴 것을 확인할 수 있고, 코드창에는 아까 index.js 파일이 js 로 적혀있다!
--------------------------------------
<308강 Lambda 및 CF>

> CF Template 에 Lambda 를 추가할 수 있다 (INLINE 방식으로, 직접 추가)
> 간단한 함수 기동을 위함. Code.ZipFile 속성을 사용
> 이 경우에는 Function Dependency 를 활용할 수 없다 (외부 종속성 - 위 실습 NPM 패키징 한 것 처럼 직접 패키징하지 않았기 때문)

> 반면에, S3 를 통해서 CF 에 넣는 방법도 있다
> S3 에 람다 함수의 ZIP 된 패키지를 올려야 함. 이 위치를 CF Template 에 다음과 같은 속성들을 사용하여 명시해야 함
>> S3Bucket / S3Key (full path to zip) / S3ObjectVersion (versioned 시 추가)
> 람다를 변경 후 S3 는 최신화 했어도, 이 템플렛에 명시한 내용들을 최신화하지 않으면, CF 는 함수 업데이트를 해주지 않는다
> 함수만 변경해주면 업데이트 해주는거임? 아니면 저기에 명시될 내용 말하는거임? (함수만 변경하면 업데이트는 해주는 듯?)
<S3 와 CF 로 Labmda 배포하는데, Multiple Accounts 에서 특정 계정의 S3 에 있는 람다를 배포하고 싶을 때 >

> 1번 계정에 S3 버킷, 람다 코드 올라가 있고, 이걸 2번 계정, 3번 계정에 배포하고 싶음
> CF 를 각 계정에 활성화하고, 1번계정의 S3 객체를 참조해야 한다
>> 이 때 두가지 방안을 모두 실행해야 하는 듯
>> 1. S3 버킷의 Bucket Policy 를 명시, 원하는 특정 계정들에게 Allow 를 준다
>> 2. 참조하려는 계정의 CF에서 Execution Role (IAM Role) - 내가 타 계정의 것을 가져올 수 있다
>> 이 과정들로 타 계정들이 S3 버킷의 객체를 Get 하여 활용할 수 있다
<309강 실습>
Parameters:
S3BucketParam:
Type: String
S3KeyParam:
Type: String
S3ObjectVersionParam:
Type: String
Resources:
LambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
Path: "/"
Policies:
- PolicyName: root
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- logs:*
Resource: arn:aws:logs:*:*:*
- Effect: Allow
Action:
- xray:PutTraceSegments
- xray:PutTelemetryRecords
- xray:GetSamplingRules
- xray:GetSamplingTargets
- xray:GetSamplingStatisticSummaries
Resource: "*"
- Effect: Allow
Action:
- s3:Get*
- s3:List*
Resource: "*"
LambdaWithXRay:
Type: "AWS::Lambda::Function"
Properties:
Handler: "index.handler"
Role:
Fn::GetAtt:
- "LambdaExecutionRole"
- "Arn"
Code:
S3Bucket:
Ref: S3BucketParam
S3Key:
Ref: S3KeyParam
S3ObjectVersion:
Ref: S3ObjectVersionParam
Runtime: "nodejs20.x"
Timeout: 10
# Enable XRay
TracingConfig:
Mode: "Active"
> 강사 공유 자료 중 lambda>cf 쪽에 lambda-xray.yml 을 참조 (S3 에 올릴 람다 함수 yml)
> Parameter 에 S3BucketParam, S3KeyParam, S3ObjectVersionParam 3가지 변수를 명시해줬다. 이와 같이 해주면 CF 에서 이를 참조할 수 있으므로, 어디서 가져올지 쉽게 참조 & 추후 변경 가능하다
> yml 을 보면 우선 LambdaExecutionRole 리소스를 우선 생성한다
> 그 다음으로 Execution (IAM) Role 을 만드는데, 람다가 이 IAM Role 을 Assume 할 수 있도록 PolicyDocument 를 만들어주고(?), 그리고 Policy 자체를 명세한다 (항상 자동으로 해줬던 부분이라 어색한 느낌)
>> Allow 하는 액션으로는 CW 에 대한 로깅, S3 에 대한 GET, Xray 활용 등이 있다
> 그 다음으로는 람다 함수 그 자체를 명시한다
>> Fn::GetAtt 함수를 사용해 위에서 생성한 IAM Execution Role 을 참조 설정한다
>> 람다 함수의 코드는 S3 로 부터 가져오도록 설정한다
>> X-Ray Enable 도 해준다 (쓰기 때문)
> 이후 S3 버킷을 만들어서, 람다로 배포할 함수를 S3 에 패킹징하여 ZIP 을 올린다 (위에서 실습한걸 올림)
> CF 로 이동하여, 위 템플렛을 사용하여 생성한다
> CF 에서 인지한 3가지 Param 을 추가한다 (S3 버킷 소스 메타데이터 추가)

> CF 가 생성을 마친 후에는, 람다 함수도 생성될텐데, 이 콘솔에 들어가보면 "Application 에 종속된 람다 함수입니다" 라는 안내를 볼 수 있다 (CF 로 관리된다는걸 암)
> S3 에 ZIP 한 함수가 잘 배포된 것을 확인할 수 있다
--------------------------------------
<310강 Lambda 컨테이너 이미지>
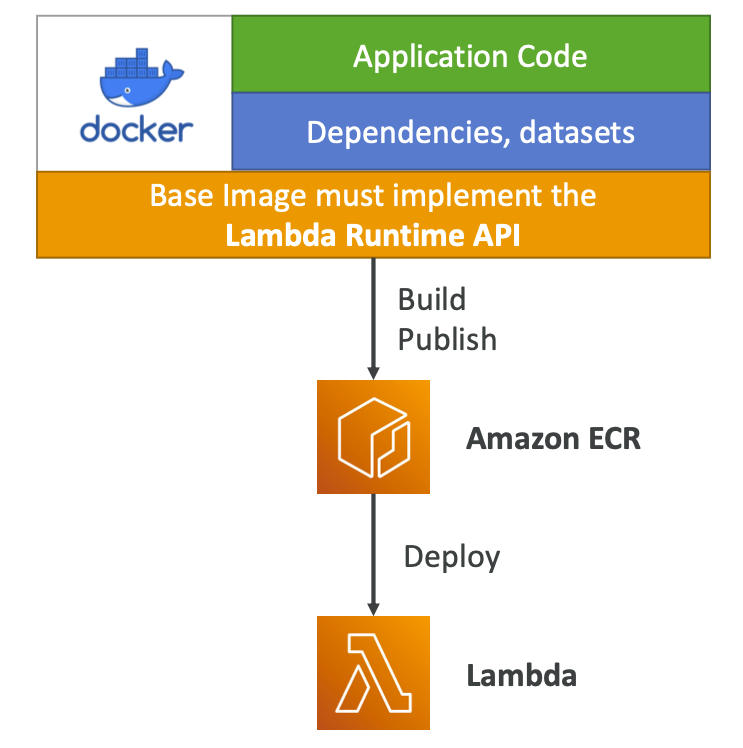
> 람다 함수를 컨테이너로서 배포 가능 (ECR에서)
> 복잡하거나 대규모의 의존성을 Packing 할 수 있다
> 도커로 기동되는 너의 컨테이너가 Base Image 위에 띄워져야 하는데, Base Image 는 "Lambda Runtime API" 를 사용해야 함
> Python / Node / Java / .Net / GO / Ruby 등의 Base Image 를 사용할 수 있다
>> Lambda Runtime API 를 상속하는 Base Image 를 직접 만들 수도 있다
<Lambda Container Images 실제 모습>
# Base IMG 로 Lambda Runtime API 를 사용하는 이미지를 추가한다
FROM amazon/aws-lambda-nodejs:12
# 사용할 소스 코드 및 파일들을 이미지에 넣는다
COPY app.js package*.json ./
# 컨테이너에 필요한 의존성들을 설치한다 (이미지에서 실행되어 주입되어 진 상태로 두는 것으로 난 이해하고 있음)
RUN npm install
# 마지막에는 RUN 할 함수를 지정해야 한다 (아마 Function Invoke 시 컨테이너가 띄워질텐데, 이 때 수행할 함수를 지정하는 듯)
CMD [ "app.lambdaHandler" ]
> aws 로부터 제공되는 Base Image 를 사용
> 그 이하는 앱 혹은 사용 언어에 따라서 Build 하는 방식이 바뀔 듯
<ECR 을 활용한 람다 배포의 Best 사용안> * (일부는 Dockerfile 전체적으로 사용하는 방법이라고 봐도 괜찮은 것 같음)*
> 위에서 말했듯, AWs-provided Base Image 사용
>> 람다 서비스로 이미 캐싱됨 - lambda can pull less info from the container
> Multi-Stage Building 사용
>> 앱을 컨테이너화 시키기위한 과정을 위에서 모두 한다음에, 마지막 container image 에 필요한 artifact 만 담는다 (이전 step 들은 모두 버림) (ex: 자바 앱을 빌드하기 위한 과정 위에서 다하고, 컨테이너에는 빌드 파일만 담는다)
> Build from stable to frequently changing
>> Dockerfile 안에서 "많이 바뀌는 영역" 은 뒤쪽에 와야 하고, "가장 less 하게 바뀌는 영역"이 앞쪽으로 오게 작성해야 한다
>>> ex: Java App 을 위한 Base Package 다운로드 및 환경 준비 -> 위에
> Large Layers 인 Function 은 Single Repository 를 사용해야 한다 (?)
>> Large Layer 가 모두 동일한 Repo 에 있으면, 이 ECR 이 Layer 들을 비교하기 용이 (avoid uploading & storing duplicate layers) - 원래 도커가 Layer 별로 지정된 Repo 에 있으면 그걸 참조함
> Large Lambda Function 을 배포하고 싶으면 (10GB 까지 ) 코드 직접 배포보단 이렇게 Container Image 화하여 배포하는 것이 효율적
-------------------------------------------------
<311강 Lambda Version & Alias>
> 람다함수를 작성할 때, $Latest 를 사용했음 (mutable)
> 람다 함수를 실제 배포를 할 때, version 을 사용한다. V1 이런식으로 되면, 이는 Immutable 하다
> 계속 업데이트/배포를 할 수록 버전 숫자는 증가한다
> Immutable 한만큼, 각 버전은 ARN 을 부여 받는다. 따라서 Version 객체 = code + config 이다 (아무것도 바뀔 수 없음)
> End User 에게 Stable End Point(?) 를 제공하려면?
> Alias 를 사용 할 수 있다. Alias 는 특정 버전으로 라우팅해주는 "pointer" 라고 볼 수 있다
>> dev/test/prod Alias 등을 설정, 각기 다른 Lambda Version 으로 가도록 지정
> Alias 는 Mutable 이다. ($Latest 역시 별칭의 일종)

> "DEV" 별칭은 $LATEST 를 지속 참조하도록 함 (코드를 수정 / 디버깅 가능하도록)
> "TEST" 별칭, "PROD" 별칭은 각기 V2/V1 을 참조하도록 함 (업데이트 준비 / 현재 운영중인 버전 구분)
> 별칭은 "Blue/Green" 배포를 가능하도록 해주며, 람다 함수에 "Weights" 들을 할당해준다
>> V1 을 (안정 배포) 모두 V2 로 전환해주고 싶다고 할 경우, 5% 만 V2 로 보내도록 설정 (이 방식의 배포 이전이 굉장히 좋은 듯! 계속 이 형태를 만힝 사용!)
>> PROD 영역에서 V2 를 테스트 하는 것 (간보기!)
>> ## 시험에서 나올 수도 ## ALIAS 역시 ARN 을 할당받음 (참고로 ALIAS 는 다른 ALIAS 를 참조할 수 없다!! 복잡성 훨씬 감소)
-------------------------------------------------
<312강 Version & Alias 실습>
> 우선 V1 과 V2 를 띄운다
> 함수 반환 : "this is version 1" 으로 변경
> Action > Publish new Version 함 > V1 으로 생성을 해준다
> 생성된 페이지에서 Code Source 로 이동하면 "Code and handler editing is only available on unpublished function page" 라고 적혀 있음 (Immutable 이기 때문)
>> 수정을 시도해보려 하면 안됨. 다시 Latest 로 이동해야 가능
> 다시 코드창으로 돌아가서, "this is version 2" 로 변경 후 다시 배포 (다시 발행을 하면 Version: 2라고 자동으로 명명된다)
> Test 해보면 V2 코드가 돌아간다
> 메인 함수 창에서 [버전] 탭으로 가면 배포한 버전들을 확인할 수 있다. 여기서 Alias 로 놀 수 있음

> Dev Alias 를 만들어보자.
> 별칭 생성, 이름: dev, 버전 $Latest 로 지정 (이것도 새로운 버전 마냥 새로운 화면으로 이동한다)
> 이렇게 되면 로컬에서 작업할 때는 사용하는 람다 함수를 dev alias 로 포인팅하면 된다
> 이런식으로 test, prod 를 각각 v2, v1 으로 연계해서 만든다

> 이제 test 스테이징을 해보기 위해, prod 로 들어가는 일부는 test 로 들어가게 하여, 문제가 발생하는지 간을 볼 것이다
> 이제 별칭을 통해 가중치를 둬보자 > Prod 별칭을 Edit 해보자.

> Weighted Alias 에서, 이 Alias 에서 V2버전 (test 였던 것) 으로 30% 로 분배하라고 설정할 수 도 있다 (기존 운영은 70% 받음)
> 이제 prod 람다로 이동해서 test 를 해보면, version 1,2 나뉘어서 뜬다 (이런식으로 배포된 것을 alias 를 통해 라우팅을 분리해줄 수 있다)
> 아마 API 를 호출 할 때 alias 를 지정할 수 있을 것 같음!!

-------------------------------------------------
<313강 Lambda 및 Code Deploy>

> Code Deploy 는 람다 Alias 에 대한 traffic shift 를 지원해준다
> 위 그림처럼, PROD 별칭이 있고, V1 에서 V2 로 업그레이드 하려고 함
> 이 때, Code Deploy 를 사용하면, X 값을 점차적으로 증가시켜, X=100 이 될 때가지 만든다
>> Linear 설정 : N분마다 100% 까지 점차적 증가 (ex 3분마다 10퍼 증가)
>> Canary 설정 : X % 로 우선 시도 -> 그 이후 100 으로 바로 변경 (ex Canary10Percent5Minute -> 10퍼로 5분간 유지 후 100퍼로 변경)
>> AllAtOnce 가능 : 트래픽을 바로 변환 가능 (risk 가 제일 큼, 굳이 이걸?)
> Pre & Post Traffic Hook 을 만들어서 람다 함수의 상태를 점검할 수 있다
>> 문제 발생시 후크 Fail, 알람 Fail 등등 Code Deploy 가 이를 감지해서 자동으로 V1 으로 롤백한다
< Code Deploy 하는 AppSpec.yml 을 사용할 경우 >

> 이 경우, 알아둬야 하는 몇 가지가 있음
> Name & Alias : 람다 함수의 이름과 별칭
> Current Ver & Target Ver : 현재 이 배포가 pointing 하는 함수 Ver / 트래픽이 분할되어야 하는 함수 Ver
> Code Deploy 와 Lambda 의 연동 실습은 SAM 에서 한다고 함
-------------------------------------------------
<314강 Lambda 함수 URL>

> 굳이 ALB 혹은 API Gateway 를 사용하지 않고 람다 함수를 HTTP(S) 엔드포인트로 노출시키고 싶을 때
> Funciton URL : Unique 한 URL 을 제공해준다 (불변) / 설정 이후 Web Browser, Curl, Postman 등 어떤 HTTP Client 로 시도 가능하며, 다음과 같은 형태이다
https://<url-id>.lambda-url.<region>.on.aws
> Public Internet 을 통해서만 접속이 가능하다
> 다른 도메인을 통해서 접속하는 경우 CORS 설정 해야 함. (브라우저 직접 호출보단 서버에서 호출하도록 하는게 낫긴 할듯)
> (중요) $Latest 나 별칭들마다 제공이 가능, But Funciton Version 에는 연동할 수 없다 (URL은 Version 제공 불가)
<URL 보안 >
> Resource-Based Policy (IAM) - 리소스 기반, 이 람다를 사용할 수 있는 정책
>> 람다 함수의 접근 가능 계정, IP 범위 (CIDR), IAM 정책을 명시 (항상 하던 짓)

> CORS
>> 다른 도메인에서 람다 함수를 호출하게 되는 경우, CORS 설정을 꼭 해야 함
>> S3 버킷은 A 도메인에서 제공, 람다 함수 URL 로 api.a.com 을 호스팅한다
>>> 도메인이 다르니, 람다 함수 URL 설정에서 CORS 설정을 해줘야 함

> AuthType_NONE
> 설정시 람다 함수를 전체 공개 하는 것 (물론 RBP 는 항상 작동하므로, RBP 에서도 public access 를 grant 해야함 - 위 그림이 전체 공개하라는 RBP 이다)
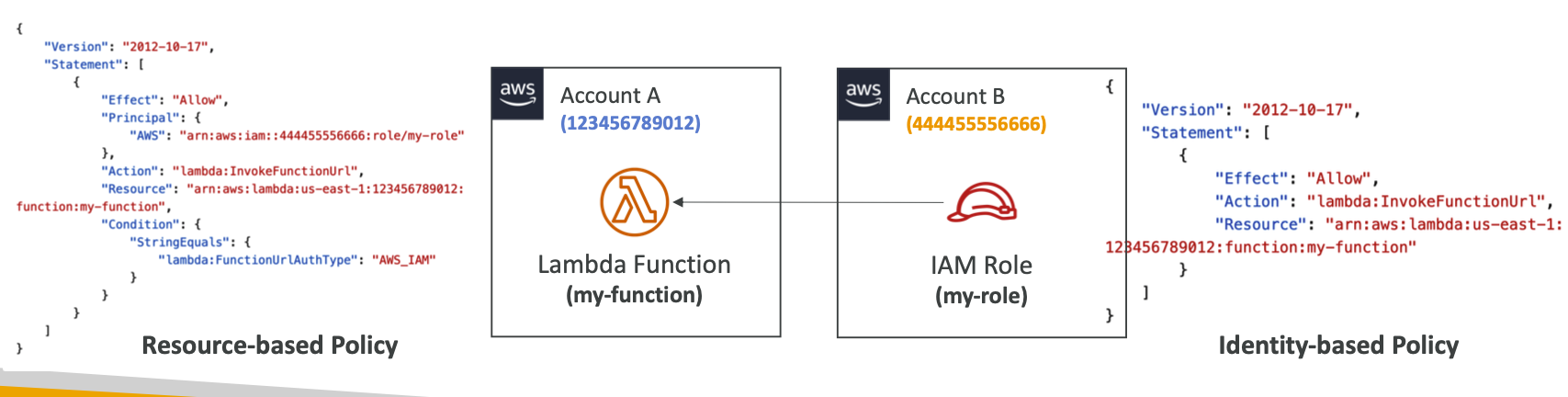
> AuthType AWS_IAM
설정시 인증 / 인가 단에는 IAM 이 사용된다는 뜻 (Principal's Identity-based Policy (IBP)(요청자의 권한인가? 씨발 뭔소리야 ㅇㅇ 요청자쪽 맞는듯) 와 RBP 로 평가한다)
>> Principal 은 lambda:invokeFunctionUrl permission 이 포함되어야 한다
>> 같은 계정 내에선 IDP 나 RBP 둘 중 하나만 ALLOW 되어 있으면 된다 (단일 계정에선 OR 조건)
>> Cross 계정 간에는 AND 조건임
> 위 그림에서 A 계정에 RBP 에 AWS_IAM 으로 타 계정의 접근 (IAM 소유시) 을 허용한다고 되어 있음
> 하지만 이건 Cross Account 설정 중이므로 사용하는 계정의 IBP 에서도 InvokeURL 권한을 가지고 있어야 한다 (A지역의 B ARN 의 람다함수를 Invoke 를 Allow 하는 권한)
> 이 AND / OR 조건은 람다의 권한 부분에서도 나왔던 거임!!
> 그냥 URL 역시 람다의 기본 권한 방식과 동일한 거인 듯, 다만 그 명칭을 AWS_IAM 이런걸로 명시??
-------------------------------------------------
<315강 Lambda 함수 URL 실습>
> 람다 함수 하나 만들고 Test 나 한번 돌려봄
> V1 하나랑 "DEV" 라는 Alias 하나 만들었음
> 구성에서 "Funciton URL" 이동

> CORS도 설정 같이 할 수 있음.
>> FUNCTION URL 이 발급되었다. 이걸 사용해보면 "Hello From Lambda" 라는 응답을 받는 것을 알 수 있음
> 다시 한 번 말하지만 Alias 혹은 $LATEST 만 URL 을 발급할 수 있다 (버전은 불가)
-------------------------------------------------
<316강 - Code Guru 연동하기>

> Code Guru 프로파일러를 통해 람다 함수의 런타임 성능을 모니터링 할 수 있다 (콘솔에서 활성화 가능)
> CodeGuru 는 너가 연동한 Lambda 함수에 대한 "Profiler Group" 을 만든다 (Java & Python 지원)
> 연동이 되면 람다가 하는 일은 다음과 같다
>> Layer 로 CodeGuru Profiler 를 추가한다
>> 내부 동작을 위해 필요한 환경 변수들을 추가한다
>> 기능이 동작하려면 IAM 필요 >> 함수의 IAM Role 에 AmazonCodeGuruProfilerAgentAccess 권한이 자동으로 추가됨
> 그냥 연동만 하면 알아서 다 해주는 듯! 그냥 이런 것도 있다 정도만 알아두자
-------------------------------------------------
<317강 - Limits - 외워두는 게 좋음>
> 시험에서 잘 물어보는 영역 (Per Region 별로 다르기 때문) // Execution 과 Deployment 두 종류의 제한이 있다
> Execution
>> 메모리 할당 : 128MB ~ 10GB 사이로, 1MB 단위로 조절 가능 (vCPU 는 같이 늘어난다)
>> 동작 시간 : 최대 900초까지 설정 가능 (15분) (그 이상 걸리면 Lambda 에서 할 일이 아님)
>> 환경 변수 : 최대 4KB (적은 용량)
>> 큰 파일을 활용해야 할 경우, /tmp 공간이 있음 : 512MB (ephermal 공간은 512!)
>> 동시 실행 Concurrent Exectuion 은 1000개까지 가능 (별도 요청이 있을 경우 늘릴 수 있다) (근데 이거 400개로 변경된건지?)
>>> 필요시 Reserved Concurrency 활용해서 (굳이?) 제어 가능
> Deployment
>> 크기: zip 의 경우 50MB / zip 이 아닌 경우 250MB
>> 환경 변수 : 4KB
> 예시 문제 : RAM 30GB 필요, 30분의 실행시간 필요, 3GB 의 대형 파일이 필요 등등 >> 이런 경우 람다를 쓰는 것이 적절하지 않다는 것 명심!!
-------------------------------------------------
<318강 - 람다의 마지막. Best Practices, 그냥 기억해야 할 점들!>
> Heavy_Duty 작업은 핸들러 외부에서 수행해야 한다 (Execution Context) (AWS SDK 초기화, DB 연결, 종속성 주입 등)
> 시간, 상황에 따라 바뀔 것들은 Environment Variable 을 사용한다 (DB Connection 값, S3 버킷 주소, 등등)
>> 보안값 환경 변수 활용시 Password / Sensitive Values 들은 KMS 암호화하여 환경 변수 사용 가능
> 배포 패키지 크기를 런타임에 맞게 최소화 (Minimize pacakge size to its runtime necessities)
>> 함수가 너무 크면 나누고, 람다에서의 제한 (위에 있는거) 기억, Layers 기능을 사용하는 것도 확인
> 람다 함수가 스스로를 호출하게 하지 말아라. 재앙. 비용 수천대로 청구 가능 (Recursive 주의!)
-------------------------------------------------
<퀴즈>
2. S3 업로드시 람다 호출. 이 때, CW 로그에 동일한 요청 ID 로 중복을 확인함. 이유는? > 정답 : Lambda 함수가 실패하여 재시도 발생
4. AWS 서비스 중 Lambda 함수를 매시간 호출되도록 예약 할 수 있는가? (스케줄링 가능한 것) -> CW Event
5 (틀림). 방금봤는데 틑리냐 ㅋㅋㅋ tmp 공간은 512!
8. CF 템플렛에서 Lambda 함수를 어떻게 선언하는가?
>> 모든 코드를 .zip 파일로 S3 버킷에 업로드하고, AWS::Lambda::Function 블록의 객체 참조!
9 (중요함, 틀림). 람다 함수는 PostgreSQL 용 Node.js 드라이버를 사용해서 DB 연결을 함. 종속성 추가를 위해 람다 함수를 어떻게 묶는가?
> 강의에 분명히 나옴
> 정답은 함수와 종속성을 하나의 폴더에 넣고 함께 압축. (외부 Dependency, Layer 부분 복습할 때 확인)
11. 람다에서 15분 이상 걸리는건 EC2 같은 곳에서 실행하는게 맞다
12. 비동기 호출에서 실패시, DLQ 를 추가하여 SQS 로 메세지를 전달해 놓는건 좋은 분석 방법이다
13 (틀림). 근데 솔직히 해석 문제 쫌 있는 듯 ㅇㅈ?
> 정답 : Lambda 함수 ExecutionRole 에 대한 권한이 없습니다 >> 이게 아니라 ExectuionRole 에 DLQ 로 보내는 권한이 없다가 맞음
> 내 오답: 대신 SQS를 사용해야 한다. SNS 용 DLQ 는 없다 (DLQ 는 SNS/SQS 만을 통해 가져갈 수 있다, 이거 복습 필요할듯!)
14> 뭔가 안된다면 권한 확인. X-Ray 데몬은 필요 없음. 람다는 알아서 해줌. 활성화만 하면 됨
16 (틀림) > 답변 확인 누르면서 잘못되었단걸 느낌. 환경 변수의 제한은 4KB. 반드시 메모리 용량 기억. 무조건 나옴.
19 (확인 필요) > 매핑은 스트리밍 쪽이였던 것 같은데? SQS, SNS 중에 뭘까? 정답: SNS : 비동기식이기 때문? (이거 확인 필요함)
21 (틀림) > 람다는 Go 는 지원하지만 C++ 은 지원하지 않음
23 (다 틀림) > 교차 계정 IAM 역할이 뭐임?? RBP 랑 ISP 이거 두개 아니였음?? 후자가 교차 계정인가?
>> 정답은 Execution Role 이라고 함. 사실 당연. Execution Role 본인이 하는일이 아니기 때문.
24 > 업데이트 하면 Param 도 같이 업데이트 필요, Version 이 계속 바뀔 것이므로!
25 (틀림, 확인 필요) > 모르겠는뎅 ㅋㅋㅋ 일단 이미지는 쓸 수 있었던 것 같음.
>> 계측, Image 사용 가능, Destination 사용 불가라고 함.. ㅠ
람다 드디어 끝!!!!
====================================================================================
교육 출처
- AWS Certified Developer Associate 시험 대비 강의 - Udemy
'웹 운영 > AWS' 카테고리의 다른 글
| [CDA] 섹션 23 - AWS 서버리스 : API Gateway (0) | 2024.09.09 |
|---|---|
| [CDA] 섹션 22 - AWS 서버리스 : Dynamo DB (0) | 2024.09.01 |
| [CDA] 섹션 21 - AWS 서버리스 : Lambda (I) (0) | 2024.08.13 |
| [CDA] 섹션 20 - AWS 모니터링 및 감사 (Audit): CloudTrail (0) | 2024.08.10 |
| [CDA] 섹션 20 - AWS 모니터링 및 감사 (Audit): CloudWatch, X-Ray (0) | 2024.07.30 |



