메모리 가시성
1. Volatile 에 대하여
public static void main(String[] args) {
MyTask task = new MyTask();
Thread t = new Thread(task, "work");
log("runFlag = " + task.runFlag); // 시작은 당연히 True
t.start();
ThreadUtils.sleep(1000);
log("runFlag를 False 로 변경 시도 : work Thread 중지 예상");
task.runFlag = false;
log("실제 runFlag 값 = " + task.runFlag); // main 스레드에서 조회시 False 로 출력됨 (내가 바꿨으니)
}
static class MyTask implements Runnable {
boolean runFlag = true; // 많은 스레드에서 활용하지만 일반 변수
@Override
public void run() {
log("task 시작");
while (runFlag) { // runFlag 가 false 면 탈출
}
log("task 끝");
}
}
-----------
13:51:09.106 [ main] runFlag = true
13:51:09.114 [ work] task 시작
13:51:10.118 [ main] runFlag를 False 로 변경 시도 : work Thread 중지 예상
13:51:10.119 [ main] 실제 runFlag 값 = false
// 하지만 Java 는 종료되지 않음. (*) work 스레드가 while 문을 탈출하지 못하고 있다 (*)
위와 같이 work thread 가 flag 를 가지고 수행을 하고 있고, main thread 에서 이를 변화시켜서 스레드 중단을 명령하는 상황이 있다. 놀랍게도 위 상황을 실행시키면 work thread 는 종료되지 않는다. 이는 멀티스레딩의 현상이며, volatile 은 이 현상을 설명한다.
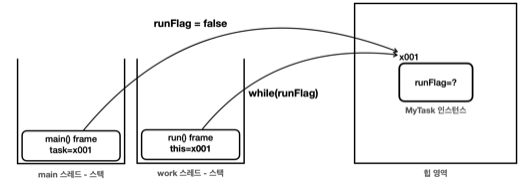
Work Thread 는 인스턴스가 생성되어 힙 영역에서 공간을 차지하고 있을 것이고, 두 스레드는 이 인스턴스의 runFlag 값을 참조하고 있다. 하지만 두 눈으로 runFlag = false 가 되었음을 출력값으로 확인했음에도, work thread 가 이를 빠져나오지 못하는건 매우 놀라운 현상이다. 이를 메모리 가시성 문제라고 한다 (메모리에 변경한 값이 언제 보이는가?).

CPU 가 메인 메모리 대신에 자신에게 가까운 캐시 메모리를 사용하는 건 다들 알고 있는 사실이다 (현대는 코어 단위로 캐시 메모리 존재). 스레드가 CPU에 할당되면서 runFlag 값을 사용하면 CPU 는 앞으로 이 값을 효율적으로 처리하기 위해 캐시 메모리에 로딩하고, 이후로는 이 값을 사용한다. 따라서 CPU 가 main 스레드를 실행시키면서 runFlag 를 바꿔야 할 때 자신의 캐시 메모리에 있는 runFlag 를 바꾼 것이고, 다른 CPU 는 work 스레드를 실행할 때 runFlag 를 자신의 캐시 메모리에 있는 true 값으로 읽어오고 있기 때문에 while 문이 종료되지 않은 것이다.
그렇다면 캐시 메모리에 있는 값들은 언제 메인 메모리에 반영되는가? 이 정답은 알 수 없다. 반대도 알 수 없다. 모두 다른 CPU 가 하고 싶을 때 하는거라, 매우 극단적으로 보면 프로그램 실행 중 영원히 되지 않을 수도 있다고 한다. 하지만 메인 메모리에 반영되어도, work 스레드를 실행하는 CPU 가 "좀 지났나? 다시 불러와볼까?" 라고 하기 전까지도 반영되지 않는다 (사실 CPU 입장에서 다른 스레드를 실행시킬 때 컨텍스트 스위칭을 하는데, 이 때 (높은 확률로) 캐시 메모리도 갱신하긴 한다 - 캐시 메모리 비워줘야 하기 때문).
static class MyTask implements Runnable {
volatile boolean runFlag = true; // 많은 스레드에서 활용하지만 일반 변수
...
}
이처럼 캐시메모리를 통한 성능 개선보단, 항상 메모리에 로딩되어 있는 정확한 값을 읽어오는게 중요할 때가 이다. 위처럼 volatile 을 사용하면 해당 값을 읽거나 쓸 때는 항상 메인 메모리를 접근해서 가져온다.
public static void main(String[] args) {
MyTask myTask = new MyTask();
Thread t = new Thread(myTask, "work");
t.start();
ThreadUtils.sleep(1000);
myTask.flag = false;
log("flag = " + myTask.flag + ", count = " + myTask.count + "의 값으로 종료");
}
static class MyTask implements Runnable {
boolean flag = true;
long count;
@Override
public void run() {
while (flag) {
count++; // 1억번에 한번만 출력
if (count % 100_000_000 == 0) {
log("flag = " + flag + ", count = " + count);
}
}
log("flag = " + flag + ", count = " + count + "의 값으로 종료");
}
}
---------------
...
16:16:56.223 [ work] flag = true, count = 200000000
16:16:56.567 [ main] flag = false, count = 293324804의 값으로 종료
16:16:56.588 [ work] flag = true, count = 300000000
16:16:56.588 [ work] flag = false, count = 300000000의 값으로 종료
이번엔 다른 예제를 살펴보자. 위와 같이 짠 후 실행시켜보면 main 시점에서 false 로 바꿨을때는 2억9천번째인데, 이후로 work 스레드는 3억번째에 false 로 바뀜을 감지하고, while 문을 탈출한다. 거의 천번 이상은 캐시메모리에서 조회한 모습을 볼 수 있다.
참고로 몇 번을 하든 work 스레드는 정확하게 10*n 번 째에 탈출하는데, System.out.println() 으로 뭔가를 출력하는 것은 커널 모드 전환이 필요하므로 해당 스레드는 대기 상태로 전환된다. 돌아오면 컨텍스트 스위치가 (*)보통 발생하기 때문에, 3억번 출력이후 돌아와서 갱신을 하니까 flag = Flase 전환을 확인한 것이다.
count 와 flag 를 volatile 처리하면, 다음과 같이 출력됨을 확인할 수 있다. 지속적으로 메모리에서 읽으므로 task.flag 를 메모리 값에 false 로 변경하고, work 스레드도 메모리 값의 false 값을 확인한다. 아무리 work 스레드가 수행을 하고 있어도, main이 값을 바꾸는 순간 work 스레드도 정확하게 이 값을 인지하기 때문에, 바로 다음줄에 출력되듯이 아래와 같이 완벽하게 일치하는 count 값을 반환할 수 있는 것이다.
17:07:02.817 [ main] flag = false, count = 94862366의 값으로 종료
17:07:02.817 [ work] flag = false, count = 94862366의 값으로 종료 // 성능에 영향을 준 모습까지 확인할 수 있다.
2. 자바 메모리 모델 (Java Memory Model)
JMM은 자바 프로그램이 어떻게 메모리에 접근/수정 하는지 규정하며, 특히 Multi-Threading 환경에서의 상호작용을 규정한다. 핵심 내용은 여러 스레드들의 작업 순서를 보장하는 happens-before 관계에 대한 정의다. hb 관계란 스레드 간의 작업 순서를 정의하며, A 작업이 B 작업보다 "happens-before" 관계라면, A 작업에서의 모든 메모리 변경사항은 B 작업에서 볼 수 있다 (A 작업의 내용은 모두 메모리에 반영된 최신상태 보장). 즉, 메모리 가시성을 보장하는 규칙이라고도 할 수 있고, volatile 도 한 종류이다. 멀티 스레드 내에서는 다음과 같은 상황에서 hb 관계가 성립된다고 얘기한다 (외울건 아님).
- 단일 스레드 내에서 프로그램 순서대로 작성된 명령문은 happens-before 순서로 실행된다 (당연한 것)
- volatile 변수에 대한 쓰기 작업은 해당 변수를 읽는 모든 스레드에 보인다. 즉, 쓰기 작업은 그 변수를 읽는 작업보다 hb 관계가 형성된다 (반드시 쓴 값을 읽을 수 있다)
- 스레드에서 {다른Thread}.start() 를 호출하면, 그 이전에 수행한 작업은 모두 다른 Thread 에서 확인할 수 있는 hb 관계
- 스레드 Join 을 호출시, 해당 스레드가 종료하며 올려놓은 값을 대기하는 스레드가 확실히 확인할 수 있는 hb 관계
- 스레드 interrupt 호출시, 호출 당하는 쪽은 확실히 interrupt 발생 여부를 확인할 수 있는 hb 관계
- 객체 생성 규칙도 있다. 객체는 완전히 생성된 이후에만 다른 스레드에 의해 참조될 수 있다 (타 스레드 참조시 hb 관계)
- 전이 규칙도 알아두자. A 가 B 보다 hb 관계, B가 C 보다 hb 관계일시, A 는 C 보다 hb 관계임이 보장된다.
메모리 가시성 문제에 대해서 쭉 살펴봤는데, 이후에 살펴볼 스레드 동기화 기법 (synchronized, ReentrantLock) 들을 사용하는 것도 메모리 가시성 문제를 예방하는 중요한 방법이다. 이제부터는 스레드의 꽃인 동기화 기법에 대해서 살펴본다.
동기화 (Synchronized) - ⭐ ⭐
1. 출금 예제
멀티스레드를 사용할 때 주의할 점은, 같은 자원에 여러 스레드가 동시에 접근할 때 (공유자원) 발생하는 동시성 문제이다. 인스턴스의 필드, 자료구조 등 모두 공유 자원에 속할 수 있다. 은행과 계좌에 대한 상황은 동시성 문제를 설명하기에 매우 적합한 예시이다. 다음과 같이 출금을 연속으로 시도하는 예제를 살펴보자.
public class BankAccountV1 implements BankAccount {
private int balance; // balance 생성자 주입됨
....
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
// 잔고가 출금액보다 적으면 실패!
if (amount > balance) {
log("[실패] - 계좌 잔액이 부족합니다");
return false;
}
// 잔고가 출금액보다 많으면 진행
log("[가능] - 출금액: " + amount + ", 잔액: " + balance);
ThreadUtils.sleep(1000); // 출금에 걸리는 시간으로 가정
this.balance = this.balance - amount;
log("[출금완료] - 출금액: " + amount + ", 잔액: " + balance);
log("거래 종료: " + getClass().getSimpleName());
return true;
}
//...
}
public static void main(String[] args) throws InterruptedException {
BankAccount account = new BankAccountV1(1000);
// 악의적인 유저의 동시 출금 시도
Thread t1 = new Thread(new WithdrawTask(account, 800), "w-t1");
Thread t2 = new Thread(new WithdrawTask(account, 800), "w-t2");
t1.start(); // 800 원 출금
t2.start();
ThreadUtils.sleep(500);
log("t1 state: " + t1.getState());
log("t2 state: " + t2.getState());
t1.join(); // 출금 완료 대기
t2.join();
log("최종 잔액: " + account.getBalance());
}
---------------
23:04:58.444 [ w-t1] [가능] - 출금액: 800, 잔액: 1000
23:04:58.444 [ w-t2] [가능] - 출금액: 800, 잔액: 1000
23:04:58.891 [ main] t1 state: TIMED_WAITING
23:04:58.892 [ main] t2 state: TIMED_WAITING
23:04:59.449 [ w-t1] [출금완료] - 출금액: 800, 잔액: 200
23:04:59.449 [ w-t2] [출금완료] - 출금액: 800, 잔액: -600
23:04:59.450 [ w-t1] 거래 종료: BankAccountV1
23:04:59.451 [ w-t2] 거래 종료: BankAccountV1
23:04:59.455 [ main] 최종 잔액: -600 // 은행 망함.
// 어떤 경우는 200으로 조회되는데, 이 경우에는 "스레드가 완전히 동시에 수행" 되는 경우

BankAccount 라는 인스턴스에 balance 가 있는 상황이고, WithrawTask 라는 인스턴스 두개가 800 이라는 amount 를 가지고 있다. 그리고 스택은 각 스레드마다 생성되었고, 각 스레드에서는 수행중인 Task 에 대한 메모리 주소를 this 에 저장하고 있다. 여기까진 계속 해온 상황.
이 상황에서는 run 이 각각돌면서, withdraw 역시 (w-t1, w-t2) 스레드가 각각 실행한다. 예상하는대로 두 스레드는 같은 BankAccount 인스턴스에 접근하게 되고, 해당 인스턴스에 있는 잔액 필드도 함께 사용한다 (이 부분에서 강조하시는게, withdraw, run 에서 말하는 "this" 가 뭔지 계속 따라가보는게 중요 - withdraw 함수의 this 는 모두 x001 로 치환 가능). 즉, BankAccount 인스턴스와 그 안의 멤버 필드 balance 는 "공유 자원"으로 간주한다.
우리가 원하는 상황은 한 스레드는 성공하고, 한 스레드는 실패하는 것인데, 둘다 검증 부분을 통과한 상황이 되어버린다. 악의적인 유저는 1000원 있음에도, 1600원을 가져가버리는 상황이 발생하며, 이제 이 문제를 해결할 것이다. volatile 문제와는 완전히 별개인 것도 이해가 되어야 한다 (근데 가시성 문제도 있지 않나? 라는 의심이 드는건 좋은 것 -> 이게 200원 상황으로 의심된다).
2. 동시성 문제


1번과 같은 상황에서, t2 입장에서 balance 는 여전히 1000원이고, 출금이 현재 가능한 상황이므로 "검증 로직을 통과" 하는 상황이 발생한 것이다. 따라서 순차적으로 진행되므로 -800 원이 두번 되어서 -600원이 되어 은행이 망한 것이다.
두번째 시나리오는 둘다 계속 동시에 수행되는 것이고 (멀티 코어라 가능한거겠지?), sleep 까지 같이 했다. balance-=amount 도 동시에 수행되었을 경우, t1, t2 는 완전히 동시에 balance 를 읽기 때문에 1000원, 결과는 모두 200원일 것이다. 둘다 200원을 balance 의 값으로 넣은 상황 (그냥 두번 넣은거다). 이건 아예 계산이 이상하기 때문에 은행 입장에선 더 큰 문제다.
3. 임계 영역 (Race Condition) - ⭐ ⭐ 모든 것의 시작
문제가 발생한 원인을 생각해보면, 우선 공유 자원을 사용함에 있어서 검증단계와 실제 출금단계로 (여러) 단계가 나뉘어져 있기 때문이다. 또한, 로직 내에서는 "1000원이 끝까지 유지된다" 라는 큰 가정 즉, 공유자원이 내가 사용시작한 시점 이후 중간에 변하지 않을 것이라는 가정이 있다. 하지만 balance 는 "공유 자원"이기 때문에, 중간에 얼마든지 변경될 수 있는 상황이고, 실제 바꾸기 때문에 위에 문제들이 발생한 것이였다.
만약 출금하는 로직을 한 번에 하나의 스레드만 접근할 수 있게 하면 해결된다. 즉, 검증 + 출금단계가 모두 이루어지는 동안 한 번에 하나의 스레드만 처리해야 한다. 이런 영역을 임계 영역이라고 한다. 여러 작업자(스레드)가 동시에 접근하면 데이터 불일치 / 예상 못한 동작이 발생할 위험이 있는 부분, 동시에 접근하면 안되는 공유 자원을 제어하려는 부분을 말한다. 즉 withdraw() 함수는 임계 영역으로 정의한다. 임계 영역은 한번에 하나의 스레드만 접근할 수 있도록 보호해야 한다.
4. Synchronized 함수
public class BankAccountV1 implements BankAccount {
private int balance; // balance 생성자 주입됨
....
@Override
public synchronized boolean withdraw(int amount) { // 동기화 키워드
log("거래 시작: " + getClass().getSimpleName());
...
log("거래 종료: " + getClass().getSimpleName());
return true;
}
}
public static void main(String[] args) throws InterruptedException {
BankAccount account = new BankAccountV2(1000);
// ... V2 로 동일하게 진행
log("최종 잔액: " + account.getBalance());
}
------------------
00:17:08.341 [ w-t1] 거래 시작: BankAccountV2
00:17:08.356 [ w-t1] [가능] - 출금액: 800, 잔액: 1000
00:17:08.786 [ main] t1 state: TIMED_WAITING
00:17:08.787 [ main] t2 state: BLOCKED
00:17:09.361 [ w-t1] [출금완료] - 출금액: 800, 잔액: 200
00:17:09.362 [ w-t1] 거래 종료: BankAccountV2
00:17:09.363 [ w-t2] 거래 시작: BankAccountV2
00:17:09.364 [ w-t2] [실패] - 계좌 잔액이 부족합니다
위 변형된 모습처럼, 함수에 synchronized 라는 키워드만 붙여주면 그 함수는 하나의 한 스레드만 접근이 가능하게 된다. t1, t2 가 순서대로 진행되어서, 계좌 잔액이 부족하여 검증에 실패하는 모습을 확인할 수 있다! 이 동기화 함수는 도대체 어떻게 동작하는 것일까?

우선 자바의 모든 객체 인스턴스는 사용하든 사용하지 않든 Lock 을 가지고 있다. 그리고 Synchronized 메서드를 호출하기 위해선 인스턴스의 락을 우선 획득해야 한다 (그럼 synchronized 함수가 여러개라면..?). 따라서 위처럼 T1 스레드가 먼저 가져갔으므로, T2는 락 획득에 실패하므로 스레드가 BLOCKED 상태로 전이되어 무한정 대기한다. T2 는 스케줄링 되지 않으며 대기하다가, t1이 반납하면 그제서야 락을 얻고 진입하게 되는데, 이미 BankAccount의 balance 값은 t1이 출금한 이후이므로 검증에 실패하게 된다. 자바에서는 이렇게 안전한 임계 구역을 편리하게 만들 수 있다 (참고로 당연히 락 획득 순서는 자바 표준에 정의되어 있지 않다).
또한, volatile 키워드를 사용하지 않아도 Synchronized 안에서 접근하는 변수의 메모리 가시성 문제는 해결된다. 자동으로 캐싱된걸 읽지 않고 메인 메모리에서 로딩하게 된다 (happens-before). 그럼 이제 임계 영역은 무조건 Synchronized 쓰면 되는걸까? 이 편리함의 대가에 대해서는 알 필요가 있다.
5. Synchronized 코드 블럭
S-함수의 가장 큰 대가는 목적과 같은데, 한 번에 하나의 스레드만 실행할 수 있다는 점이다. 즉, 성능에 영향을 끼친다. 따라서 임계 영역을 최대한 목적에 맞는 부분에서만 정의하는 것이 중요하다 (교속도로에서 사고 안나게 하려고 모두 1차로만 쓰는 것과 같음). 코드를 다시 살펴보자.
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
// 잔고가 출금액보다 적으면 실패!
if (amount > balance) {
log("[실패] - 계좌 잔액이 부족합니다");
return false;
}
// 잔고가 출금액보다 많으면 진행
log("[가능] - 출금액: " + amount + ", 잔액: " + balance);
ThreadUtils.sleep(1000); // 출금에 걸리는 시간으로 가정
this.balance = this.balance - amount;
log("[출금완료] - 출금액: " + amount + ", 잔액: " + balance);
log("거래 종료: " + getClass().getSimpleName());
return true;
}
사실상 위 코드에서 진짜 임계 구역은, if 절부터 시작해서 출금완료 로그를 찍는 부분까지다 (확인용 로그까지). 실제 현업 비즈니스 로직에서는 이와 같이 최적화가 필요한 구간이 더 생기고, 실제 성능에 중요한 영향을 준다. 따라서, 다음과 같이 변경할 수 있다.
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
// 잔고가 출금액보다 적으면 실패!
synchronized(this){ // 반드시 어떤 인스턴스의 락을 얻으려는건지 명시해야 한다
if (amount > balance) {
log("[실패] - 계좌 잔액이 부족합니다");
return false;
}
// 잔고가 출금액보다 많으면 진행
log("[가능] - 출금액: " + amount + ", 잔액: " + balance);
ThreadUtils.sleep(1000); // 출금에 걸리는 시간으로 가정
this.balance = this.balance - amount;
log("[출금완료] - 출금액: " + amount + ", 잔액: " + balance);
}
log("거래 종료: " + getClass().getSimpleName());
return true;
}
---------------
실행경과는 위와 동일, BLOCKED 상태도 조회된다.
하지만, 시작 log 가 상황에 따라 동시에 찍히기도 한다는 차이가 있음
S- 코드 블럭을 배우는 핵심은, 당연히 임계 영역의 정의를 대충하면 안되고, 최소한의 범위로 정의를 해야 한다는 것을 Java 가 직접 알려주는 것이다. 임계 영역을 해결하고, 데이터 일관성을 유지하기 위한 synchronized 는 Java에서 매우 중요하니, 잘 기억해 두자. 그리고, 다차선 도로를 일차선으로 만드는 상황이니, 성능을 최대한 신경써야 한다는 점도 꼭 기억하자.
Synchronized 의 단점을 더 정리해보자면, 우선 "무한정 대기"이다. 락을 얻지 못한 스레드는 락을 얻을 때까지 "무한정 대기" 하는 것이 기본 동작이므로, 유저의 요청을 무한정 대기 시킬 가능성이 있는 것이다. 약 10초 안에 응답하지 못하면 "나중에 다시 시도해주세요" 정도라도 띄워줘야 하는데, synchronized 만 가지고는 복잡하게 들어가야 하는 것이다.
또한 "공정성 이슈"가 있다. 어떤 스레드가 락을 얻을지 우리는 모르고, 운영체제 마음대로이기 때문이다. 먼저 왔다고 먼저 얻는게 아닌, 불공정성이 존재할 수 있다는 점도 알아두자. 즉, 극악의 상황에서 어떤 스레드는 Starvation 현상이 발생할 수도 있는 것이다. 따라서 더 세밀하게 제어하기 위한 java.util.concurrent 패키지가 Java 1.5 부터 추가되었고, 이를 이제 공부해볼 것이다.
고급 동기화 (Concurrent Lock)
1. Lock Support
LockSupport는 스레드를 WAITING 상태로 혹은 반대로 변경하는 역할을 수행하며, 다음과 같은 함수 수행을 제공한다. 예전에 배웠던 interrupt 함수도 WAITING 상태를 다시 RUNNABLE 상태로 바꾸는 역할 했던 것을 상기해봐도 좋다.
- park() - 스레드를 대기 상태로 둔다 (WAITING, 무한정 대기)
- parkNanos(nanos) - 일정 nano 단위의 초만큼 TIMED_WAITING 상태로 변경한다 (이후 RUNNABLE)
- unpark(thread) - WAITING 상태의 스레드를 RUNNABLE 상태로 변경한다
public static void main(String[] args) {
Thread t1 = new Thread(new ParkTest(), "T1");
t1.start();
// 잠시 대기하여 Thread1 이 Park 에 빠질 시간을 줌
ThreadUtils.sleep(100);
log("T1 의 상태 조회: " + t1.getState()); // t1 의 상태가 WAITING 임을 알 수 있다
log("main 함수가 T1 을 깨운다 : unpark!");
LockSupport.unpark(t1);
// t1.interrupt(); // interrupt 로 깨워도 WAITING에서 나옴, 단, interrupt 상태 조회시 true
log("T1을 깨운 후 상태 조회: " + t1.getState());
}
static class ParkTest implements Runnable {
@Override
public void run() {
log("park 시작");
LockSupport.park();
log("park 종료, state: " + Thread.currentThread().getState());
log("인터럽트 상태: " + Thread.currentThread().isInterrupted());
}
}
------------
23:13:30.984 [ T1] park 시작
23:13:31.037 [ main] T1 의 상태 조회: WAITING
23:13:31.038 [ main] main 함수가 T1 을 깨운다 : unpark!
23:13:31.039 [ main] T1을 깨운 후 상태 조회: WAITING // 아직 깨기 전에 log 찍음
23:13:31.040 [ T1] park 종료, state: RUNNABLE
23:13:31.048 [ T1] 인터럽트 상태: false
parkNanos 함수를 사용하면 특정 나노시간 동안만 TIMED_WAITING 상태로 변경시킨다. 참고만 하면 좋은데, parkUntil(ms) 도 있는데, 이는 에포크 시점을 넣어서 깨어나게 하는 거라고 한다. 잘 안쓴다. 참고로 parkNanos 역시 당연하게 TIMED_WAITING 이더라도 interrupt 받을 수 있다.
public static void main(String[] args) {
Thread t1 = new Thread(new ParkTest(), "T1");
t1.start();
// 잠시 대기하여 Thread1 이 Park 에 빠질 시간을 줌
ThreadUtils.sleep(100);
log("T1 의 상태 조회: " + t1.getState()); // t1 의 상태가 WAITING 임을 알 수 있다
}
// 이번엔 스스로 깨어난다
static class ParkTest implements Runnable {
@Override
public void run() {
log("parkNanos 시작");
LockSupport.parkNanos(2000_000000); // 2초 뒤에 깨어난다
log("2초 뒤 parkNanos 알아서 종료, state: " + Thread.currentThread().getState());
log("인터럽트 상태: " + Thread.currentThread().isInterrupted());
}
}
--------------
23:20:17.408 [ T1] parkNanos 시작
23:20:17.471 [ main] T1 의 상태 조회: TIMED_WAITING
23:20:19.419 [ T1] 2초 뒤 parkNanos 알아서 종료, state: RUNNABLE
23:20:19.426 [ T1] 인터럽트 상태: false
TIMED_WAITING 과 WAITING 은 그냥 똑같다고 보는게 맞다. 다만, 특정 시간 이후 깨어나야 함을 알고 있냐 마냐의 차이다. 그럼 이런 WAITING 들과, BLOCK 상태의 차이를 알겠는가?
(꼭 기억하기) BLOCKED 상태는 WAITING들과는 다르게 interrupt 를 걸어도 대기 상태를 빠져나올 수 없다. BLOCKED 는 sync 함수 앞에서 특정 인스턴스에 대한 락을 획득하기 위해 대기할 때만 걸리는 상태이다. BLOCKED 상태는 자바 스레드에서 사용되는 특수한 상태라고 생각하는게 낫다 (interrupt 가 안걸리기 때문!!). WAITING 은 스레드가 특정 조건 / 시간 동안 대기하는 상태이다. 하지만 둘다 스케줄링에 들어가지 않기 때문에, CPU 입장에선 별반 차이가 없다.
LockSupport 는 이처럼 스레드를 WAIT / TIMED_WAIT 상태로 변경할 수 있고, interrupt 함수 없이 깨울 수도 있다. 이 기능들을 통해서 synchronized 의 단점인 무한 대기를 해결할 수 있을 것 같다. 가령, 다음과 같이 BLOCKED 가 아닌 WAITING들을 사용하여 다음과 같이 로직을 설계할 수도 있을 것이다.
...
if(parkNanos(10초)동안 Lock 을 얻지 못함){ // 아니면 10초 뒤에 unpark() 를 직접 실행
log("10초 동안만 기다려줍니다");
return false;
}
// 임계 영역 시작
...
// 임계 영역 종료
기다리는Thread.unpark();
위처럼 특정 스레드가 "락"을 어떻게든 얻게 하고, 얻지 못하면 LockSupport 를 활용하여 WAITING 상태로 만든다. 이후 임계 영역이 종료되어 "락"을 얻을 수 있는 상태가 되면, 해당 스레드를 다시 unpark() 하여 다시 스케줄링 되도록 한다. 이 때, 너무 오래 대기한다면 종료시켜 버릴 수도 있다.
(여기까지만 들었어도, 시험에 붙었을 수 있겠다, 참 아쉽다) 락을 직접 구현하는 것은 매우 어렵다. 대기하고 있는 스레드들을 알고 있어야 하기 때문이다. 그리고 어떤 스레드를 깨울지도 결정해야 한다. LockSupport 도 괜찮을 뻔했지만, Lock 알고리즘을 직접 구현해야 한다는 단점이 있다. 이럴바엔 그냥 무한 대기 감수하고 sync 함수를 쓴다 해도 과언이 아님. 이제 이를 해결해주고 알고리즘까지 제공해주는 갓 자바의 ReentrantLock 을 알아보자.
지금 배울 Reentrant Lock은 "이것만 잘 활용했어도 모 기업의 과제 전형을 통과할 수 있었을 것이다" 싶을 정도로 중요하고, 자바 멀티 스레딩에 있어서 핵심적인 Library 이다.
2. Reentrant Lock - ⭐ ⭐ 모르면 절대 안되는 영역
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
Lock 인터페이스는 위와 같은 함수들을 제공하고, 안전한 임계 영역을 위한 락의 역할체이다. Reentrant Lock 은 대표적인 Java 1.5 구현체이다. 지금 말하는 Lock 은 BLOCKED / sync 함수에서 등장한 객체 내부 모니터 락과는 전혀 다르다!
- lock() - 락을 획득. 타 스레드가 소유시 락을 풀 때가지 WAITING State 전환. Interrupt 받지 않는다
- lockInterruptibly() - lock 과 동일하지만, Interrupt 를 허용한다
- tryLock() - 락 획득을 시도하고, 즉시 성공 여부를 반환한다. WAITING State 전환이 없다
- tryLock(time, unit) - 주어진 시간 동안 락 획득을 시도 후, true/false 반환한다. 정해진 시간동안 WAITING State 로 전환되며, Interrupt 를 받을 수 있다
- unlock() - 락 사용을 마친 스레드가 락을 해제한다 (락을 가지고 있는 스레드가 호출하지 않는다면 IllegalMonitorStateException 발생 가능성이 있다). Alert 을 하는거라, 대기중인 스레드 중 하나가 락을 얻는다
- newCondition() - 락과 결합되어 사용되는 Condition 객체를 반환하며, 뒤에서 자세히 다룬다
위와 같은 함수들을 통해 sync 블록보다 훨씬 더 유연하게 동기화 기법을 구현할 수 있다 (일정 시간 대기, 락을 직접 주거니 받거니 등등). 참고로, WAITING 상태는 Interrupt 받으면 RUNNABLE 로 변경된다고 했는데, lock 이 어째서 Interrupt 를 받지 않는지 의문이 들 수 있다. 사실 짧은 시간동안 변하지만, lock 함수가 다시 WAITING 으로 변경해버린다.
무한 대기는 어떻게 해결이 될 각이 보인다. 그렇다면 공정성 문제는 어떻게 해결할까? Starvation 문제를 어떻게 방지할까? 대표적으로 ReentrantLock 구현체는 스레드들이 공정하게 락을 얻을 수 있는 모드를 제공한다 (어떤 원리까진 아닌듯).
public class ReentrantLockEx {
private final Lock nonFairLock = new ReentrantLock(); // 비공정 모드
private final Lock fairLock = new ReentrantLock(true); // 공정 모드
public void nonFairLockTest(){
nonFairLock.lock();
try{
// 임계 영역
} finally {
nonfairLock.unlock();
}
}
public void fairLockTest(){
fiarLock.lock();
try{
// 임계 영역
} finally {
fiarLock.unlock();
}
}
}
- 비공정 모드 - 먼저 요청한 스레드가 먼저 획득을 보장하지 않는다 (공정성 문제 무시). 운영체제에게 맡기기 때문에, OS 입장에서 성능, 중요도에 따라서 스케줄링 하다록 맡긴다
- 공정 모드 (true 전달) - 먼저 요청한 스레드가 순서대로 락을 획득할 수 있게 한다. 당연히 T/O 로 성능 저하가, 그것도 생각 이상으로있다 (자료구조, 완전한 동시 등 처리할게 훨씬 많아짐, 중요한 스레드가 먼저 얻지 못하기도 함)
사실 비공정 모드도 그렇게 기아 현상이 발생하고 그러진 않는다. 요즘 운영체제들은 그런게 잘 처리되어 있기 때문이다. 그리고 비공정 모드여도 엄청난 스레드 경합 현상이 있는 SW가 아니라면... 엔간하면 순서대로 처리된다고 한다. 그래서 그냥 "아, 이건 공정 모드를 써야겠다!" 라는 엄청난 생각이 들기 전까지 비공정 모드 쓰면 된다 (가령, 티케팅처럼 순서가 정말 critical 하게 중요한 경우..?)
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
lock.lock(); // 앞으로 올 임계 영역을 실행함에 있어서, 먼저 온 스레드가 lock 을 획득한다 ==================
try {
if (amount > balance) {
log("[실패] - 계좌 잔액이 부족합니다");
return false;
}
log("[가능] - 출금액: " + amount + ", 잔액: " + balance);
ThreadUtils.sleep(1000); // 출금에 걸리는 시간으로 가정
this.balance = this.balance - amount;
log("[출금완료] - 출금액: " + amount + ", 잔액: " + balance);
// lock.unlock(); // 임계영역이 끝나는 구간, 락을 내려 놓으면 위에서 대기중인 스레드가 임계영역을 시작한다 =========
// 참고로 lock 을 사용했으면, 100% 무조건 unlock 을 해줘야 한다 안그러면 무한 WAITING 가능
// 지금 위에서 return false 하면 unlock 코드 안돈다 -> 따라서 unlock 은 finally 습관!!
// 이 부분 이후에 try 들어온 것
}finally {
lock.unlock();
}
log("거래 종료: " + getClass().getSimpleName());
return true;
}
===================
결과는 t1,t2 중 하나는 실패 (정상)
BankAccount 예제에 lock 을 간단하게 활용하는 모습을 볼 수 있다. 제일 중요한 것은 마지막에 lock.unlock() 을 꼭 해주기 위해 try/finally 문을 사용한다는 점이다. t1, t2 중 락을 얻지 못한 스레드는 lock() 함수 호출 시 내부적으로 LockSupport.park() 이 호출되어, WAITING 상태로 변하고, ReentrantLock 내부 대기 Queue 에서 관리된다. tryLock 함수였을 경우 당연히 TIMED_WAITING 상태로 변하고 Queue 에서 관리된다.

t1이 락을 반납하면, 대기큐에 있는 스레드 하나를 깨운다. 이 때, t1 은 unlock() 호출시 LockSupport.unpark(대기 중인 스레드)를 내부적으로 사용한다 (위에서 배웠던 것들이 느껴져야 함!!). 이 때 대기큐에 대해서 공정모드 / 비공정모드에 따라서 또 다른 부분들이 존재하는 것이다. 또한, Lock 을 사용할때도 동기화 기법이므로, 메모리 가시성 문제는 해결된다 (Lock, Sync, volatile).
이처럼 ReentrantLock 으로도 concurrency 제어가 충분히 가능하다. 이제는 sync 보다 더 나았던, "무한 대기"를 어떻게 방지하는지 살펴보자. 위에서 살펴봤던 tryLock 함수들에 대해서 살펴보자. 참고로, tryLock 은 락 획득 시도 자체도 포함되어 있다.
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
// 락을 얻을 수 있으면 얻고, 얻지 못하면 그냥 실패처리 해야 할때 (안기다려야 할 때) - 이걸 썼어야 했다
if (!lock.tryLock()) { // tryLock 은 얻을 수 있으면 얻는 행위도 포함되어 있다
log("[진입 실패]: 이미 락을 누가 사용중입니다");
return false;
}
// tryLock 에 lock 얻으려는 작업이 포함되어 있기 때문
// lock.lock();
try {
if (amount > balance) {
log("[실패] - 계좌 잔액이 부족합니다");
return false;
}
log("[가능] - 출금액: " + amount + ", 잔액: " + balance);
ThreadUtils.sleep(1000); // 출금에 걸리는 시간으로 가정
this.balance = this.balance - amount;
log("[출금완료] - 출금액: " + amount + ", 잔액: " + balance);
} finally {
lock.unlock();
}
log("거래 종료: " + getClass().getSimpleName());
return true;
}
------------------
01:49:02.869 [ w-t1] 거래 시작: BankAccountV5
01:49:02.869 [ w-t2] 거래 시작: BankAccountV5
01:49:02.875 [ w-t2] [진입 실패]: 이미 락을 누가 사용중입니다
01:49:02.882 [ w-t1] [가능] - 출금액: 800, 잔액: 1000
01:49:03.318 [ main] t1 state: TIMED_WAITING
01:49:03.318 [ main] t2 state: TERMINATED
01:49:03.884 [ w-t1] [출금완료] - 출금액: 800, 잔액: 200
01:49:03.885 [ w-t1] 거래 종료: BankAccountV5
01:49:03.888 [ main] 최종 잔액: 200
기존과는 다르게, 아예 늦게 들어간 t2 는 임계 영역에 들어가기 위해 대기하지 않고, 바로 빠져 나온 후 종료되어 TERMINATED 상태가 확인된다. 이번엔 tryLock(시간) 을 살펴보자. 그래도 바로 나오지 말고 좀 대기해봐라 하는 것이다.
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
try {
if (!lock.tryLock(500, TimeUnit.MILLISECONDS)) {
log("[진입 실패]: 이미 락을 누가 사용중입니다");
return false;
}
} catch (InterruptedException exception) {
log("뒤늦게 온 스레드가 그래도 잠깐 대기를 해보는 와중에 Interrupted 가 발생하여 RUNNABLE 로 변경");
throw new RuntimeException(exception);
}
try {
...
}
------------------
01:57:08.747 [ w-t2] [가능] - 출금액: 800, 잔액: 1000
01:57:09.195 [ main] t1 state: TIMED_WAITING // Main 함수에서 Thread.wait()
01:57:09.196 [ main] t2 state: TIMED_WAITING // 스스로 lock 500ms 간 대기
01:57:09.241 [ w-t1] [진입 실패]: 이미 락을 누가 사용중입니다 // 0.7 이후 0.5초간 대기후, 얻지 못하므로 바로 false 반환 후 종료됨
좀 빠르게 배운 concurrent 라이브러리들이였지만, 그래도 sync 보다 훨씬 섬세한 작업을 할 수 있다는 점으로 연장선을 그릴 수 있어야 한다. 그리고 Reentrant Lock 을 사용하면서 Thread 들이 어떻게 대기하고, 빠져나올 수 있는지 각 Lock interface 함수들과 해당 인터페이스가 내부적으로 사용하는 LockSupport 의 함수들을 잘 이해하고 있어야 한다.
조금씩 어려워지고 있다 슬슬. 간단히 훑으면서라도 복습을 통해 이 모든 강의는 확실히 박혀 있어야 하는 개념들인 것 같다. 이제야 반 정도 왔는데, 완강하자!!

출처
[실전 Java 고급 1편]으로 엮인 모든 포스트들은 교육 사이트 인프런의 지식공유자이신 김영한님의 [김영한의 실전 자바 - 고급 1편, 멀티스레드와 동시성] 강의를 기반으로 작성되었습니다. 열심히 정리하고 스스로 공부하기 위해 만든 포스트이지만, 제대로 공부하고 싶으시면 해당 강의를 꼭 들으시는 것을 추천드립니다.
김영한의 실전 자바 - 고급 1편, 멀티스레드와 동시성 강의 | 김영한 - 인프런
김영한 | , [사진]국내 개발 분야 누적 수강생 1위, 제대로 만든 김영한의 실전 자바[사진][임베딩 영상]단순히 자바 문법을 안다? 이걸로는 안됩니다!전 우아한형제들 기술이사, 누적 수강생 40만
www.inflearn.com
'Java' 카테고리의 다른 글
| [실전 Java 고급 1편] - 5. Executor Framework 에 대하여 (0) | 2025.04.27 |
|---|---|
| [실전 Java 고급 1편] - 4. CAS와 동시성 컬렉션 (0) | 2025.01.31 |
| [실전 Java 고급 1편] - 3. 생산자 소비자 문제 (BlockingQueue 만들기까지) (0) | 2025.01.31 |
| [실전 Java 고급 1편] - 1. Thread 의 제어 (0) | 2025.01.31 |
| [Java] OOP, 객체 지향의 5대 원칙 (SOLID) (0) | 2022.10.12 |