생산자 소비자 문제 1 - Synchronized 심화
1. 소개
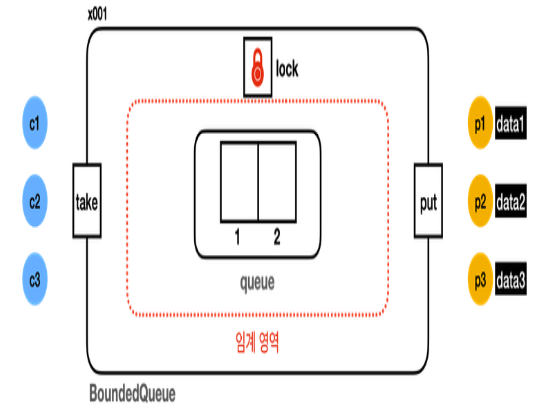
생산자 소비자 문제는 멀티 스레딩 세계에서 자주 등장하는 동시성 문제이다. 데이터 생산/소비하는 스레드가 동시에 많을 상황을 다룬다. 생산자는 데이터를 생산하는 스레드들을(파일에서 읽어오거나, 네트워크에서 받아옴) 말하고, 소비자는 이를 출력하거나, 저장하거나, Message Queue 로 활용하는 등 데이터를 소모하는 역할이다. 마지막으로 버퍼는 한정된 크기를 가지고, 데이터가 일시적으로 저장되는 공간이다. 생산자/소비자는 이 버퍼를 중심으로 데이터를 주고 받는다.
문제는 생산/소비 속도가 차이가 심해서, 한 쪽이 대기하는 상황에서 발생한다. 데이터가 생산 속도가 더 빠르면 버퍼에 더 이상 공간이 없으므로, 생산자 스레드는 대기해야 한다. 반대로, 소비 속도가 더 빠르면 버퍼에 소비할 데이터가 없으므로, 소비자 스레드가 대기해야 한다. 이 문제는 생산자/소비자 문제(생산자와 소비자가 함께 데이터를 사용해서 발생)라 하며, 한정된 버퍼 문제(버퍼의 크기가 한정되어 있어서 발생) 라고도 한다.
2. 문제의 시작
public class BoundedQueueV1 implements BoundedQueue {
private final Queue<String> queue = new ArrayDeque<>();
private final int MAX;
public BoundedQueueV1(int MAX) {
this.MAX = MAX;
}
@Override
public synchronized void put(String data) {
if (queue.size() == MAX) {
log("[put실패] 큐가 가득 참, 요청 데이터 버림: " + data);
return;
}
queue.offer(data); // 삽입
}
@Override
public synchronized String take() {
if (queue.isEmpty()) {
return null;
}
return queue.poll();
}
}
위 클래스는 한정된 Queue 를 공유자원으로 사용하는 클래스이다. 각 함수들은 여러 스레드가 접근할 수 있으므로 sync 함수를 붙였다. put 함수와 take 함수를 임계영역으로 하는 이유는, A 스레드가 put 을 호출하는 동시에 take 함수를 호출해서, 내가 정한 MAX 이상의 데이터가 들어가는 일이 발생할 수도 있는 상황 같은 동시성 문제가 생기기 때문이다. 위에서 버퍼 사이즈를 넘었는데 생산자가 저장하려고 하거나, 데이터가 없는데 소비자가 가져가려 할 때 정상 수행이 되지 않는다. 이후 생산자, 소비자도 다음과 같이 정의한다.
public class ProducerTask implements Runnable{
private BoundedQueue queue; // 어디서 가져올건지
private String req; // 넣은 데이터
public ProducerTask(BoundedQueue queue, String req) {
this.queue = queue;
this.req = req;
}
@Override
public void run() {
log("[생산 시도] " + req + " -> " + queue);
queue.put(req);
log("[생산 완료] " + queue);
}
}
public class ConsumerTask implements Runnable {
private BoundedQueue queue;
public ConsumerTask(BoundedQueue queue) {
this.queue = queue;
}
@Override
public void run() {
log("[소비 시도] ? <- " + queue);
String data = queue.take();
log("[소비 시도] " + data + " <- " + queue);
}
}
스레드가 전달받은 공유 자원에 데이터를 생산하거나 소비하거나 하는 작업들의 모습을 확인할 수 있다. 그리고 다음과 같은 Main 함수를 수행한다.
public static void main(String[] args) {
//1. BoundedQueue 선택
BoundedQueue queue = new BoundedQueueV1(2);
//2. 생산자, 소비자 실행 순서 선택 (반드시 하나만 선택해서 수행)
producerFirst(queue); // 생산자 먼저 실행
// consumerFirst(queue);
}
private static void producerFirst(BoundedQueue queue) {
log("===== [생산자 먼저 실행 작업] 시작, " + queue.getClass().getSimpleName() + "=====");
List<Thread> threads = new ArrayList<>();
buildAndStartProducer(queue, threads);
printAllState(queue, threads); // 만든 스레드들이 담긴 모습을 출력해보자
buildAndStartConsumer(queue, threads);
printAllState(queue, threads);
log("===== [생산자 먼저 실행 작업] 종료, " + queue.getClass().getSimpleName() + "=====");
}
private static void consumerFirst(BoundedQueue queue) {...} // 위와 동일하나, 순서만 반대
private static void buildAndStartProducer(BoundedQueue queue, List<Thread> threads) {
System.out.println();
log("생산자 시작");
for (int i = 1; i <= 3; i++) { // 생산자 3개 만들기
Thread producer = new Thread(new ProducerTask(queue, "data" + i), "생산자 " + i);
threads.add(producer);
producer.start();
sleep(100); // 1,2,3 순서대로 시행되게끔 해줘보자
}
}
private static void buildAndStartConsumer(BoundedQueue queue, List<Thread> threads) {...} // 동일, ConsumerTask 할당
버퍼의 크기를 2로 준비했다. 그리고 생산자들을 생성 후 순차적으로 start 되게 하거나, 소비자들을 생성 후 순차적으로 start 되게 하였다. 생산자들이 먼저 수행될 때, 소비자들이 먼저 수행될 때 모습들이 어떻게 다른지 알아볼 수 있다.
- producerFirst() 순서: [생산자1] → [생산자2] → [생산자3] → [소비자1] → [소비자2] → [소비자3]
- consumerFirst() 순서: [소비자1] → [소비자2] → [소비자3] → [생산자1] → [생산자2] → [생산자3]
생산자 우선 작업부터 무슨 일이 일어나고 있는지 살펴보자. 우선 위에서 열심히 작성한 로그들을 출력해보면 다음과 같다.
16:19:37.733 [ main] ===== [생산자 먼저 실행 작업] 시작, BoundedQueueV1=====
16:19:37.738 [ main] 생산자 시작
16:19:37.750 [ 생산자 1] [생산 시도] data1 -> []
16:19:37.751 [ 생산자 1] [생산 완료] [data1]
16:19:37.848 [ 생산자 2] [생산 시도] data2 -> [data1]
16:19:37.848 [ 생산자 2] [생산 완료] [data1, data2]
16:19:37.951 [ 생산자 3] [생산 시도] data3 -> [data1, data2]
16:19:37.953 [ 생산자 3] [put실패] 큐가 가득 참, 요청 데이터 버림: data3
16:19:37.954 [ 생산자 3] [생산 완료] [data1, data2]
16:19:38.055 [ main] 현재 상태 출력, 큐 현황: [data1, data2]
16:19:38.055 [ main] 생산자 1: TERMINATED
16:19:38.056 [ main] 생산자 2: TERMINATED
16:19:38.057 [ main] 생산자 3: TERMINATED
16:19:38.060 [ main] 소비자 시작
16:19:38.062 [ 소비자 1] [소비 시도] ? <- [data1, data2]
16:19:38.063 [ 소비자 1] [소비 시도] data1 <- [data2]
16:19:38.168 [ 소비자 2] [소비 시도] ? <- [data2]
16:19:38.170 [ 소비자 2] [소비 시도] data2 <- []
16:19:38.269 [ 소비자 3] [소비 시도] ? <- []
16:19:38.269 [ 소비자 3] [소비 시도] null <- []
16:19:38.372 [ main] 현재 상태 출력, 큐 현황: []
16:19:38.373 [ main] 생산자 1: TERMINATED
16:19:38.373 [ main] 생산자 2: TERMINATED
16:19:38.374 [ main] 생산자 3: TERMINATED
16:19:38.374 [ main] 소비자 1: TERMINATED
16:19:38.374 [ main] 소비자 2: TERMINATED
16:19:38.374 [ main] 소비자 3: TERMINATED
16:19:38.375 [ main] ===== [생산자 먼저 실행 작업] 종료, BoundedQueueV1=====
위에서 순차적으로 살펴보면, 생산자 1,2,3 이 순서대로 sync 를 보장받은채 data 를 넣으므로, data1,2,3 이 순서대로 들어가려 한다. data3 이 들어갈 때는 큐가 가득 찼으므로 data3 가 버려지는 모습을 볼 수 있다. 이 상황에서 "데이터를 어떻게 버리지 않을까?"를 고민하는 것이 생산자 소비자 문제의 핵심이다. 간단하다. [생산자3] 스레드가 빈 공간이 생길 때까지 대기하면 되는 것이다.
근데 지금까지 공부해왔던 것과 좀 다른 것을 알아야 한다. "큐가 빈 공간이 생겼다는 것을 인지해야 한다"는 점이 핵심이다. [생산자3] 스레드를 계속 들고 있다가 꺼내올 것인가? 반복문을 돌면서 큐에 빈공간이 생기는지 계속 체크해줄 것인가?
이어서 [소비자3] 스레드도 아무것도 획득하지 못하고 NULL 을 반환받게 된다. 이 때 역시 [소비자3]은 데이터가 큐에 추가될 때까지 대기하고 싶을 수도 있다. "큐에 데이터가 채워진 것을 어떻게 알 수 있는가?" 이 부분 역시 동일한 문제이다. 두 상황은 다르지만 같은 문제를 야기하고 있다는 점이 한정된 버퍼 문제의 핵심이다.
소비자가 먼저 실행된다 해도 상황은 크게 다르지 않다. [소비자1,2,3] 스레드가 먼저 데이터를 요청하러 왔다고 해도, 데이터가 들어온 적이 없기 때문에 모두 데이터를 얻지 못한채로 null 을 가져간다. 대기하지 않고 그대로 종료되어 버린다는 것이다. 이처럼 V1 에서의 생산자 소비자는, 대기 없이 한정된 버퍼 공간을 바라보며 데이터를 누락시키거나, 아무 값을 가져오지 않는 결과를 보여주는 문제를 가지고 있다.
지금 상황이 간단해서 그렇지, 실제 쇼핑몰, 레스토랑 이런 곳에서는 항상 주문이 들어오고, 주문을 처리하는 과정이 무한하게 발생한다. 절대 누락 주문이 있거나, 처리 요청이 되었음에도 처리되지 않은 주문이 발생하면 안된다. 어쨌든 목표는 스레드를 기다리게 하고, 적합한 상황을 인지하여 임계 영역에 진입시키는 것이다.
3. 스레드를 기다리게 해보자
@Override
public synchronized void put(String data) {
while (queue.size() == MAX) { // 1초에 한번씩 확인한다
log("[put실패] 큐가 가득 참, [" + Thread.currentThread().getName() + "] 은 대기한다");
ThreadUtils.sleep(1000);
}
queue.offer(data);
}
@Override
public synchronized String take() {
while (queue.isEmpty()) {
log("[take실패] 큐에 데이터가 없음, [" + Thread.currentThread().getName() + "] 은 대기한다");
ThreadUtils.sleep(1000);
}
return queue.poll();
}
가장 간단하게는, While 문을 돌면서 1초에 한번씩 확인하는 것이다. Queue 가 비거나, 데이터가 발생할 경우 while 문을 탈출해서 목표 로직을 수행할 수 있다. 이렇게 하면 안되지 않나? 란 생각이 들었다면 좀 뿌듯했을 것 같은데.. 위 로직을 수행하면 다음과 같아진다.
...
18:17:28.515 [ 생산자 3] [생산 시도] data3 -> [data1, data2]
18:17:28.516 [ 생산자 3] [put실패] 큐가 가득 참, [생산자 3] 은 대기한다
18:17:28.620 [ main] 현재 상태 출력, 큐 현황: [data1, data2]
18:17:28.621 [ main] 생산자 1: TERMINATED
18:17:28.621 [ main] 생산자 2: TERMINATED
18:17:28.622 [ main] 생산자 3: TIMED_WAITING
18:17:28.622 [ main] 소비자 시작
18:17:28.623 [ 소비자 1] [소비 시도] ? <- [data1, data2]
18:17:28.728 [ 소비자 2] [소비 시도] ? <- [data1, data2]
18:17:28.832 [ 소비자 3] [소비 시도] ? <- [data1, data2]
18:17:28.935 [ main] 현재 상태 출력, 큐 현황: [data1, data2]
18:17:28.936 [ main] 생산자 1: TERMINATED
18:17:28.937 [ main] 생산자 2: TERMINATED
18:17:28.937 [ main] 생산자 3: TIMED_WAITING
18:17:28.937 [ main] 소비자 1: BLOCKED
18:17:28.938 [ main] 소비자 2: BLOCKED
18:17:28.938 [ main] 소비자 3: BLOCKED
18:17:28.938 [ main] ===== [생산자 먼저 실행 작업] 종료, BoundedQueueV2=====
18:17:29.521 [ 생산자 3] [put실패] 큐가 가득 참, [생산자 3] 은 대기한다
18:17:30.525 [ 생산자 3] [put실패] 큐가 가득 참, [생산자 3] 은 대기한다
... 이하 반복
[생산자3]이 무한으로 대기하고 있으며, [소비자]들이 아무것도 가져가지 못한 점, 그리고 [소비자 1,2,3] 이 "BLOCKED" 상태가 된 점을 본다면, sync 함수 때문에 take 함수에 진입을 하지 못한 것을 알 수 있다. 즉, [생산자 3] 이 검증 단계의 임계 영역을 탈출하지 못했으므로, V2의 모니터 락을 반납하지 않은 것이다. 따라서 [소비자] 스레드들은 모두 V2 인스턴스의 모니터 락을 얻지 못하고 BLOCKED 상태에서 벗어나지 못한다.
TIMED_WAITING 상태로 ([생산자3]이 Thread.sleep() 의 진입) 변할 때 락을 반납하지 않을까? 반납을 했다면, [소비자1]이라도 들어가서 데이터를 꺼내올 수 있었을 것이다. 즉, [생산자3]이 상태 전이할 때 락을 반납하지 않은 것이다. 뒤에 나오지만, 이 상태로는 그냥 임계 영역 안에서 코드 호출하는 상황이기 때문에 반납한 상태가 아니다. 따라서, 그 누구도 절대 임계 영역에 들어갈 수 없는, 누구도 락을 양보하지 않는 무한대기 상태가 되어버린다.
이 부분 지피티랑 좀 짚어봤는데, 스레드 상태와 Intrinsic Lock (모니터 락) 의 반납 여부는 별개로 생각하는게 맞다고 한다. 즉, JVM 메서드에서 정해주는 것이다. 스레드 상태는 OS 관점, Lock 을 놓냐 마냐는 JVM 내에서 알아서 할 일이라는 것이다. 그리고 확실히 맞는 말 같다.

위 상황이 데드락인가? 라고 생각해볼 수 있다. 데드락의 정의는 "둘 이상의 스레드가 서로 자원을 점유한 채, 상대방의 자원을 기다리면서 영원히 대기 상태에 빠지는 것"이다 (데드락의 4가지 조건에 대해서 기억하면 좋을 듯). 무한 대기를 하는 쪽은 자원을 점유한 상황으로 보긴 어려우므로, 무한대기 혹은 기아상태로 보는 것이 적합하다.
기다리는건 좋은데, 임계 영역 안에서 락을 가지고 대기하는 것이 문제이다. 차피 대기하는 동안 아무것도 안하는데, 그렇다면 이 상황에서 락을 다른 스레드에게 양보할 수는 없는걸까? 즉, "임계 영역 안일지라도, 내가 아무것도 안할때는 락을 반납" 할 수 있으면 문제가 바로 해결된다. 이 동작을 해주는 함수가 바로 Java 에서 "모든 최상위 객체 Object"에서 제공하는 Object.wait(), Object.notify() 함수이다.
4. Object 객체의 wait()과 notify() - 꽤 어려움 🛑 🛑 🛑
자바는 멀티스레드를 위해 탄생한 언어이기도 하며, Object 클래스에 존재하는 기능들은 자바의 기본 기능이다. 그만큼 멀티 스레딩은 자바의 기본기라는 뜻이다. 살짝 어려운 부분이다 (깨운다, 락을 양보한다 등). 복습할 때는 wait 함수와 notify 함수, 그리고 WAITING, BLOCKED, RUNNABLE 상태의 전이 흐름, 그리고 한계점만 생각하면 다 기억난거다.
- wait() - 현재 스레드가 가진 락을 반납하고 WAITING 으로 전이시킨다. 스레드가 Intrinsic Lock (모니터 락)을 소유하고 있을 때만 호출 가능하다. wait() 을 호출한 스레드는 notify() / notifyAll() 을 통해 호출받을 때까지 대기한다
- notify() - 소유 객체의 락을 WAITING하고 있는 스레드를 깨운다. "깨운 스레드는 락을 얻는게 아니라, 다시 획득할 기회를 얻게 된다". WAITING 하고 있는 스레드가 여러개면, 하나만 깨운다. 역시 Intrinsic Lock 을 소유하고 있는 스레드만 호출할 수 있다. notify 함수는 BLOCKED 스레드에게는 아무 영향을 주지 않는다 (WAITING -> BLOCKED 가 됨)
- notifyAll() - 대기중인 모든 스레드를 다 깨운다. I-Lock 을 소유하고 있는 스레드만 임계 영역 안에서 호출할 수 있다 (모두 BLOCKED 로 전이시켜버림)
지피티와 중요한 얘기를 했는데, wait() 함수 자체가 BLOCKED 스레드들을 위한 함수라고 하면 좀 애매하다고 볼 수 있다고 한다. 즉, 결론적으로 BLOCKED가 I-Lock 을 얻게되는건 맞는데, wait() 함수 자체는 "현재 스레드"가 WAITING 상태로 가기 위한 함수라고 해야 맞다고 한다. 그리고 notify() 와 notifyAll() 은 위에 설명만으로는 명쾌하지 않은 느낌이다.
@Override
public synchronized void put(String data) {
while (queue.size() == MAX) { // 1초에 한번씩 확인한다
log("[put실패] 큐가 가득 참, [" + Thread.currentThread().getName() + "] 은 대기한다");
// ThreadUtils.sleep(1000);
try {
wait(); // RUNNABLE -> WAITING, 락 반납
log("[put 중임], [" + Thread.currentThread().getName() + "] 이 깨어남 ");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
queue.offer(data); // 삽입
log("[put 임계영역 완료 직전]: [" + Thread.currentThread().getName() + "] 작업 완료, notify 호출");
notify(); // 이 notify 는 WAIT 중인 소비자를 위한 것 // WAITING -> BLOCKED
}
@Override
public synchronized String take() {
while (queue.isEmpty()) {
log("[take실패] 큐에 데이터가 없음, [" + Thread.currentThread().getName() + "] 은 대기한다");
// ThreadUtils.sleep(1000);
try {
wait();
log("[take 중임], [" + Thread.currentThread().getName() + "] 이 깨어남");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
String data = queue.poll();
log("[take 임계영역 완료 직전]: [" + Thread.currentThread().getName() + "] 작업 완료, notify 호출");
notify(); // 이 notify 는 큐가 가득차서 대기중인 생산자를 위함
return data;
}
위에서는 생산자가 큐에 공간이 없거나, 소비자가 큐에 데이터가 없을 때 wait() 를 호출하여 I-Lock 을 반납하고 대기한다. 깨어나면 그 지점에서 다시 수행되어 자연스럽게 while 문을 다시 호출하게 된다. put 함수가 notify 를 호출하는 것은 BoundedQueue 객체의 I-Lock 을 WAITING 상태로 대기중인 스레드 중 하나를 골라서 깨우게 된다.
🛑 이 때, 우선 꼭 소비자를 깨우는건 아니다. WAITING 중에 생산자를 또 깨울 수도 있는 것이다. 🛑 또한, WAITING 중인 스레드 하나를 BLOCKED 상태로 전이시키고, 다른 sync 를 대기중인 스레드들과 다시 한번 경쟁하고, 락을 획득하게 되면 아까 그 지점에서 다시 진행하게 된다 (바로 RUNNABLE 되는게 아님을 이해해야 한다). ㅋㅋㅋ 강사님이 포기하지 말라고도 한 번 한다. 이제 위 코드의 결과를 한 번 보자.
21:46:30.734 [ main] ===== [생산자 먼저 실행 작업] 시작, BoundedQueueV3=====
21:46:30.744 [ main] 생산자 시작
...
21:46:30.957 [ 생산자 3] [생산 시도] data3 -> [data1, data2]
21:46:30.957 [ 생산자 3] [put실패] 큐가 가득 참, [생산자 3] 은 대기한다
21:46:31.062 [ main] 현재 상태 출력, 큐 현황: [data1, data2]
...
21:46:31.064 [ main] 생산자 3: WAITING
21:46:31.064 [ main] 소비자 시작
21:46:31.066 [ 소비자 1] [소비 시도] ? <- [data1, data2]
21:46:31.067 [ 소비자 1] [take 임계영역 완료 직전]: [소비자 1] 작업 완료, notify 호출
21:46:31.067 [ 소비자 1] [소비 시도] data1 <- [data2]
21:46:31.068 [ 생산자 3] [put 중임], [생산자 3] 이 깨어남
21:46:31.069 [ 생산자 3] [put 임계영역 완료 직전]: [생산자 3] 작업 완료, notify 호출
21:46:31.069 [ 생산자 3] [생산 완료] [data2, data3]
21:46:31.171 [ 소비자 2] [소비 시도] ? <- [data2, data3]
...
21:46:31.279 [ 소비자 3] [소비 시도] data3 <- []
21:46:31.382 [ main] 현재 상태 출력, 큐 현황: []
21:46:31.383 [ main] [모든스레드]: TERMINATED
21:46:31.385 [ main] ===== [생산자 먼저 실행 작업] 종료, BoundedQueueV3=====
출력 모습을 보면, [생산자3]이 큐가 가득 차서 대기(WAITING) 으로 전이된다. 이후, [소비자1]이 완료되자 notify() 를 호출해서 [생산자3] 을 다시 BLOCKED 로 만들었을 것이다. 이후로 [소비자2,3] 과 [생산자3] 락을 얻기 위해 경쟁했을 것이고, [생산자3]이 락을 얻어 먼저 출력된 모습이다 (실제로 다를 수도 있음, 계속 [생산자3] 이 얻긴 하지만.. 이 부분은 JVM이 보장해주지 않음).
또한, 위에서 "[put 중임], [생산자 3] 이 깨어남"이란 로그가 출력되기 때문에, WAIT->BLOCK->RUNNABLE 의 과정을 겪은 스레드는 처음 임계영역으로 돌아가는게 아니라, wait() 호출 이후부터 수행된다는 것도 알 수 있다. 전체 과정을 그림으로도 살펴보자.

모든 객체는 Wait Set 을 가지고 있다. 자신.wait() 을 호출한 스레드는 모두 이 Wait Set 에 보관된다. 락과 Wait Set 은 세트라고 보면 된다. 물론 BLOCKED 는 이 대기 집합에 들어가는건 아니다.
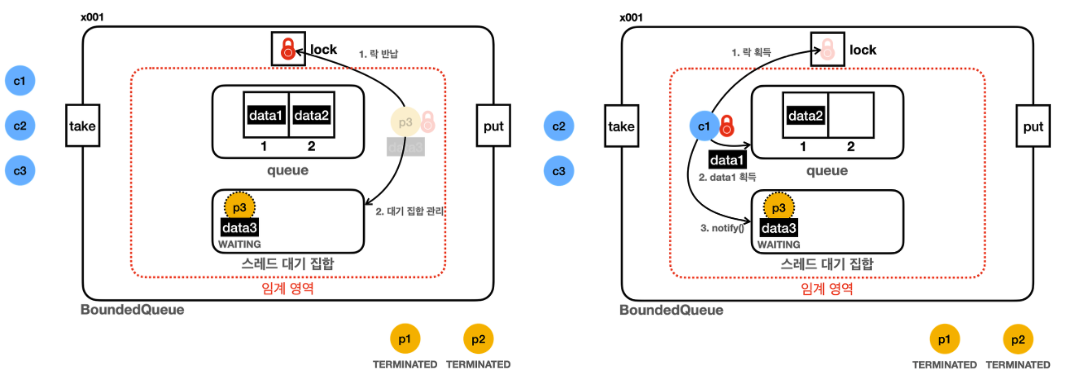
[생산자3] 은 Queue 가 가득 찼기 때문에, this.wait() 을 호출하여 wait set 으로 들어가게 된다. 이후 [소비자1] 이 data 를 얻은 이후 notify() 를 하면, Wait Set 안에서 한 스레드를 골라 Blocked 로 전환시키는 것이다. 이후 [생산자3] 은 아까 지점부터 다시 락을 얻어 데이터를 넣고 종료한다. 이 때, notify()도 후촐되긴 하는데 wait set 에 아무도 없기 때문에 아무런 일도 일어나지 않는다. 이후로는 소비자들이 원활하게 데이터를 소모하게 된다.

소비자가 먼저 실행되면, Wait Set에 소비자들이 쌓이게 된다. 이후 [생산자1]이 락을 얻고 데이터를 쓰면, notify() 를 통해 Wait Set 중 하나를 BLOCKED 로 바꾸라고 할 것이다. 참고로, 이 때 [소비자] 스레드 중 누가 나올지는 JVM 스펙에 명시되어 있지 않다. BLOCKED 가 되어서 다른 I-Lock 을 대기중인 스레드들과 경쟁을 하게 된다. 못 얻으면 당연히 그대로 BLOCKED 상태를 유지한다.
또한 [소비자1] 이 나와서 실행한다면, 마지막에 notify() 함수가 있으므로, 의도치 않게 [소비자2]나 [소비자3]을 깨우게 된다 (원하는 스레드를 고를 수는 없음). 하지만 다시 while 문을 돈 후 wait() 을 다시 호출하게 될 것이다. 이런 비효율도 존재 한다는 점도 체크할 수 있다 (무작위로 깨우기 때문에, 아무 일도 못하는 친구가 비효율적으로 CPU를 소모하게 된다).
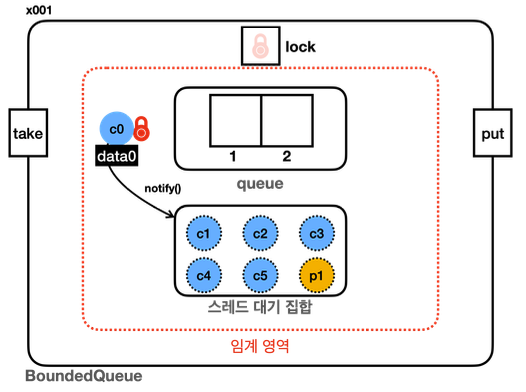
또 다른 비효율이 있는데, 바로 스레드 기아 현상(thread starvation)이다. 극단적으로 생각했을 때, 위 상황에서 [생산자1] 을 깨워야 하는 상황인데, [소비자] 스레드들만 반복적으로 깨울 수도 있다 (계속 다시 Wait Set 으로 들어가기 때문).

notifyAll() 함수를 사용하면 Wait Set에 있는 모든 스레드가 BLOCKED 상태가 된다. 따라서 [소비자] 스레드들이 순차적으로 실행되며 다시 WAITING 상태로 전이된다 해도, 어쨌든 [생산자] 스레드도 I-LOCK 을 획득할 기회는 얻을 수 있는 방법이라, 해결 방안 중 하나긴 하다.
어쨌든 정리해보면, wait(), notify() 덕분에 무한 대기도 없고, 누락 건도 없이 두 상황 모두 데이터를 정상적으로 저장하고 소비할 수 있었다! 하지만 notify 로는 불가능 하지만, 소비자는 생산자만 깨우고, 생산자는 소비자만 깨울 수 있다면 조금 더 효율적일 수 있을 것 같다는 점도 있다 (생/소 문제에서 같은 종류의 스레드를 깨우면 notify 로는 비효율이 발생한다). 어떻게 하면 원하는 스레드들을 대상으로 notify() 할 수 있을까?
생산자 소비자 문제 2 - Lock Interface 심화
1. Lock Condition
Lock 인터페이스와 Reentrant Lock 을 활용해서 위에서 언급된 비효율성을 해결할 수 있다. 위 예제에선 자바 기본 I-Lock 과 wait/notify 로 관리되는 wait set 을 사용했다면, 이제는 직접 제어를 시작하기 위해 Explicit Lock (Lock Intf) 에 대한 wait set 인 Condition 을 들여올 것이다 (Condition c = lock.newCondition()).
...
private final Lock lock = new ReentrantLock();
private final Condition condition = lock.newCondition(); // Lock 에서 가져오는데, 해당 락에 대한 대기집합이 된다
...
// 일단 똑같은데, 자바 기본 -> 직접 제어할 수 있는 concurrent 패키지로 이동
// take() 함수도 동일한 구조로
@Override
public void put(String data) {
lock.lock();
try {
while (queue.size() == MAX) {
log("[put실패] 큐가 가득 참, [" + Thread.currentThread().getName() + "] 은 대기한다");
try {
// wait(); // RUNNABLE -> WAITING, 락 반납 (이건 자바 내부 객체)
condition.await(); // 스레드에게 "condition 에세 기다려라" 라고 명령
log("[put 중임], [" + Thread.currentThread().getName() + "] 이 깨어남 ");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
queue.offer(data); // 삽입
log("[put 임계영역 완료 직전]: [" + Thread.currentThread().getName() + "] 작업 완료, notify 호출");
// notify(); // 이 notify 는 WAIT 중인 소비자를 위한 것
condition.signal(); // condition 에게 notify 하는거라고 생각하면 된다
}finally {
lock.unlock();
}
}
...
lock.newCondtion() 을 통해서 Condition 을 생성하면, 해당 ReentrantLock 을 대기하는 스레드 대기 공간을 만들 수 있다. I-Lock 과는 다르게, E-Lock 은 직접 대기 공간을 만들어서 사용해야 한다. await 와 signal 은 Object의 함수들과 동일하게 동작한다. 위 함수를 돌려보면 main 에서도 누락없이 동일하게 잘 동작한다.

2. 생산자 소비자 대기 공간 분리
비효율 개선을 이제 해볼 준비가 되었다. 비효율을 개선하기 위해서는 생산자는 소비자 스레드들만, 소비자는 생산자 스레드들에게만 notify 를 주는 것이 목적이였다.
// ReentrantLock 과 Lock 에 대한 Condition 을 활용하여,
// 생산자 소비자 집합을 분리한다
public class BoundedQueueV5 implements BoundedQueue {
private final Lock lock = new ReentrantLock();
private final Condition producerCond = lock.newCondition();
private final Condition consumerCond = lock.newCondition(); // 락은 하나인데 대기 공간을 분리할 수 있는 기술
...
// take 도 동일한 구조, 단 condition 은 반대
@Override
public void put(String data) { // 생산자 용 대기 공간에 넣어주고, 소비자를 깨운다
lock.lock();
try {
while (queue.size() == MAX) {
log("[put실패] 큐가 가득 참, [" + Thread.currentThread().getName() + "] 은 대기한다");
try {
producerCond.await(); // 생산자 스레드에서 대기
log("[put 중임], [" + Thread.currentThread().getName() + "] 이 깨어남 ");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
queue.offer(data);
log("[put 임계영역 완료 직전]: [" + Thread.currentThread().getName() + "] 작업 완료, notify 호출");
consumerCond.signal(); // 소비자 스레드를 깨움
}finally {
lock.unlock();
}
}
...
}

위처럼 한 락에 대하여 대기 공간을 나눌 수 있다 (이건 의도에 따라 다르게 설계할 수 있다). 그리고 put 함수는 생산자가 사용하니 대기시 producer 공간에, take 함수에서는 반대로 하도록 만들 수 있다. 또한, 생산자는 소비자만을 깨우고, 소비자는 생산자만을 깨우니 비효율이 개선된 모습을 확인할 수 있다 (실제로 로그도 비효율 로그가 찍히지 않았다).
notify 와 signal 함수는 둘다 락을 가지고 있는 (각각 I-lock, e-lock) 스레드가 호출해야 정상 동작한다. notify 는 보통 먼저 들어온 스레드가 먼저 수행되지만, 차이가 있는 경우가 종종 있다. 하지만 signal 은 Condition 구조는 Queue 기 때문에 FIFO 순서로 보통 깨운다 (구현체에 따라 다르긴 하지만 보통). V5 레벨 정도면 실무에서 실제로 사용해도 되고, Library 들도 이 정도의 레벨로 구현되어 있다고 한다.
참고로 Lock 이 없는 스레드가 notify 혹은 signal 을 호출하면 java.lang.IllegalMonitorStateException 이란 예외가 발생한다. 동작하지 않는게 아니라 아예 예외가 터진다.
3. 스레드의 대기 정리 (한 번 정리하는 시간) ⭐
최종 V6까지 보기 전에, sync와 ReentrantLock에 대해서 정리를 해본다. 우선 Synchronize 함수에 대해 알아보자. Sync 함수는 Intrinsic Lock 과 관련된 대기로, 잘 생각해보면 두가지 대기 상태만 존재하는 것을 알 수 있다.
- I-Lock 획득 대기 : BLOCKED 상태. sync 구간을 시작할 때 객체의 모니터 락이 없으면 대기하며, 다른 스레드가 구간을 빠져나갈 때 자동으로 Block 스레드는 락 획득을 시도한다.
- Wait() 호출 대기 : WAITING 상태. 내부적으로 구현된 wait set 에서 대기하며, 다른 I-Lock을 소유한 스레드가 notify 호출로 JVM에 의해 간택되었을 때 BLOCKED 상태로 변하면서 탈출한다.

위 그림을 보면 알겠지만, 사실 BLOCKED 상태의 스레드들도 자바 내부에서 따로 자료 구조로 관리된다 (단, 정확한 이름이 없다 - 락 대기 집합정도). E-Lock 을 설명하면서 처음으로 wait set 의 모습을 보여줬고, 이제 BLOCKED 집합소도 설명하는 것 (wait, notify 를 처음 이해하기도 어렵기 때문). 위 그림상 소비할 데이터가 없기 때문에 wait() 함수가 있다면, C1 은 "I-Lock을 반납"한 다음에 WAITING 으로 진입한다. 이후 락이 반납되었기 때문에 C2,C3 스레드들도 순차적으로 임계 영역에 진입하고, 결과적으로 모두 WAITING 상태로 wait set 에서 대기한다. 지금까지 총 3가지의 대기 집합 자료구조가 나왔음을 이해하면 넘어가도 된다.
락 대기 집합이 1차 대기소이고, 스레드 대기 집합이 2차 대기소인 느낌이다. 스레드 대기 집합을 탈출해도 BLOCKED 가 되어 1차 대기소에서 락 획득을 기다려야 하기 때문이다 (이제 다 이해 되어야 함). 즉, 모~든 자바 객체는 없어도 있을 수 있는 "임계 영역" 관리를 돕기 위해 내부적으로 3가지 기본 요소를 가져가는데, 모니터 락 (Intrinsic Lock), 락 대기 집합 (Blocked 스레드들), 그리고 스레드 대기집합(Waiting 스레드들)이다. 이 세가지 요소가 어떻게 순환되는지 설명할 수 있어야 한다.
이젠 Reentrant Lock 에 대해서 정리해본다. 위 sync 를 자바에서 기본으로 제공했지만, 성능상 이슈들이 존재해서 좀 더 섬세한 제어를 위해 코드 Lv 로 Java Lib 에서 제공하게 된다. 정확하게 언제 어떻게 되는지를 확실히 외우고 이해하는게 좋다 (두 락 모두).

- Lock 획득 대기 - Reentrant 대기 큐에서 관리되며, WAITING 상태로 대기한다. lock.lock() 호출 시 얻지 못할 경우. 락 소유 스레드가 lock.unlock() 을 호출 했을 때 큐에 있는 애가 RUNNABLE 로 전환되며 락 획득을 시도하고 성공 시 큐를 빠져나간다.
(헷갈리지 않는 법 - BLOCKED 는 오직 sync 함수에서만 사용되는 자바의 특별한 스레드 상태이다, CPU는 모름) - await() 호출 대기 - someCondition.await() 을 호출 시, 해당 Condition 자료구조에서 WAITING 상태로 대기할 것을 명령. signal() 호출시 하나를 빼줘서 Reentrant Lock 대기 큐에 넣어준다. (바로 락을 주는 건 없다, 이 때 WAITING 쭉 유지)
이 모델은 아주 옛날부터 완성된 모델로, 지금까지 자바 앱에서 잘 사용되고 있는 모습이다. 스프링에서도 내부적으로 락 모델을 정말 많이 사용하고 있다고 한다. ReentrantLock 에서는 lock.lock() 말고도 제공하는 함수들과 잘 연계가 되니까, 더 심화적으로 파봐도 좋다. V6로 넘어가기 전에, "데이터 유실" 문제로 시작된 생산자/소비자 문제가 V1 ~ V6까지 어떻게 발전해 왔는지 잘 이해하면 좋다.
지금까지 생산자/소비자 문제, 즉 "한정된 버퍼 문제"를 해결하기 위한 BoundedQueue 클래스를 살펴보았다. 하지만 이는 스레드 입장에서 "차단"을 하기 때문에, BlockingQueue 라는 말이 존재한다. put 함수는 공간이 가득차면 추가 작업을 차단 시키고, take 함수는 비어있으면 획득 작업을 차단시킨다. 이는 실제 동일한 pckg 에서 제공하는 BlockingQueue 의 내용이다. 다 제공해주는 내용이지만, 생산자/소비자 문제를 잘 이해하면 Java 멀티스레딩의 기본기를 잘 익혔다 할 수 있기 때문에 지금까지 공부한 것.
4. BlockingQueue 소개
BlockingQueue 는 Queue 를 상속받는 concurrent 패키지에서 제공하는 멀티스레드 자료구조이다. 내부 큐가 가득 차면 데이터 추가 작업 put() 을 시도할 때 스레드를 차단하며, 큐가 비어있으면 take() 함수가 차단된다. 그밖에 다양한 메소드들도 있다. 대표적으로 버퍼의 크기를 고정시킨 ArrayBlockingQueue, 버퍼의 크기를 고정/무한 선택할 수 있는 LinkedBlockingQueue 가 대표적인 구현체이다.
public class BoundedQueueV6_1 implements BoundedQueue { // 역할을 위임만 한다
private BlockingQueue<String> queue;
public BoundedQueueV6_1(int MAX) {
this.queue = new ArrayBlockingQueue<>(MAX);
}
@Override
public void put(String data) {
try {
queue.put(data);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Override
public String take() {
try {
queue.take();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
--------- ArrayBlockingQueue 의 put 함수
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
put() 함수를 들어가서 살펴보면, ReentrantLock 과 Condtion 을 동일하게 사용하고 있다. while 을 돌리면서 가득 차있으면 소비자용 (notFull Condtion) 집합소에 넣는 모습이다. enqueue 함수는 배열을 제어한 이후 마지막에 signal() 함수까지 사용하고 있다. take 함수도 비슷하게, 우리가 만든 V5와 거의 완벽히 동일한 구조다. lock은 대기시 더이상 못기다리겠으면 Interrupt 를 발생시킬 수 있는 함수를 사용하고 있다.
로그를 찍어보면 data3 까지 대기하다가 잘 들어오고 소비자들이 잘 소비하는 모습도 확인할 수 있다. 라이브러리 코드들을 보면 상당히 어려운 구조인데, lock, condition, await, 등등을 잘 이해할 수 있어서, 이제는 해석할 수 있다!! Blocking Queue 에 대해 더 살펴보자.
5. BlockingQueue 심화
만약 생산자가 서버에 상품을 주문하는 고객이라고 해보자. 큐가 가득차서 더 이상 주문을 못 넣게 된다면, 생산자 스레드는 큐 앞에서 대기할 것이고, 고객은 같이 무한정 기다리고 있다. 따라서 이런 상황에는, 포기 후 처리 할 수 없음 / 나중에 다시 시도 등을 전달하는게 맞다. 상황이 매우 다양한 만큼, BQ는 4가지를 제공한다
| 동작 | 예외 던짐 | Special Value | Blocks | Times Out |
| Insert | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| Remove | remove() | poll() | take() | poll(time, unit) |
| Examine | element() | peek() | X | X |
- 예외 던짐 (대기 없음)
- add(e) : 지정 요소를 큐에 추가, 가득 차면 실패 후 IllegalStateException 예외
- remove() : 큐에서 요소 제거, 비어 있으면 NoSuchElementException 예외
- element() : 큐의 머리 요소 반환, 그냥 peek 만 해서 제거 안함. 비어 있으면 remove 와 동일
- Special Value (대기 없이, 예외 없이 값 반환)
- offer(e) : add 와 동일, 가득 차면 실패 후 false 반환
- poll() : remove 동일, 비어 있으면 null
- peek() : element 동일, 비어 있으면 null
- Blocks (대기한다) - 우리가 구현했던 것과 동일, examine 단은 없음, Interrupt 제공
- Times Out (시간 대기) - special val + blocks 라고 보면 되며, examine 단 없음, Interrupt 제공
- offer(e), poll() - 동일하게 동작하나, 특정 시간 대기하며, 대기 시간이 지나도 실패하면 false, null 반환
@Override
public void put(String data) {
boolean result = queue.offer(data); // 실패시 대기하지 않고 결과를 바로 반환한다
log("저장 시도 결과 = " + result);
}
@Override
public String take() {
return queue.poll(); // 가지고 나올게 없으면 NULL 반환
}
-----------
12:24:05.741 [ 생산자 3] [생산 시도] data3 -> [data1, data2]
12:24:05.741 [ 생산자 3] 저장 시도 결과 = false
12:24:05.742 [ 생산자 3] [생산 완료] [data1, data2]
...
12:24:05.847 [ main] 생산자 3: TERMINATED
위와같이 offer 로 바꾼 뒤에 돌려보면, data3 은 들어가는 것을 실패하고 TERMINATED 상태로 전환된다. 즉, data loss 를 감수하는 것이다. V1 과 다른 점이 있다면 선택해서 버렸다는 점이다. 일정 시간만큼 대기 후 반환하기 위해선 시간을 넣어줄 수도 있다.
@Override
public void put(String data) {
try {
boolean result = queue.offer(data, 1, TimeUnit.SECONDS); // 대기 시간도 설정 가능
log("저장 시도 결과 = " + result);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
...
12:28:59.878 [ 생산자 3] [생산 시도] data3 -> [data1, data2]
12:28:59.979 [ main] 현재 상태 출력, 큐 현황: [data1, data2]
12:28:59.979 [ main] 생산자 1: TERMINATED
...
12:28:59.980 [ main] 생산자 3: TIMED_WAITING
12:28:59.980 [ main] 소비자 시작
12:28:59.981 [ 소비자 1] [소비 시도] ? <- [data1, data2]
12:28:59.982 [ 생산자 3] 저장 시도 결과 = true
12:28:59.982 [ 소비자 1] [소비 시도] data1 <- [data2]
12:28:59.982 [ 생산자 3] [생산 완료] [data2, data3]
1초만 기다리게 해도 [생산자3] 이 TIMED_WAITING 중이며, 1초 안에 [소비자1]이 소비해서 성공적으로 저장하는 모습을 확인할 수 있다 (이 때, 락 같은건 다 알아서 Blocked Queue 가 적용하는 것). 만약 소비자들이 다 끝날때가지 대기하면 시도 결과가 false 인 것을 알 수 있다. take 함수도 마찬가지로, 특정 시간동안 데이터가 안들어오면 null 을 가지고 나간다.
@Override
public void put(String data) {
queue.add(data); // 넣을 공간이 없으면 IllegalStateException 을 터뜨린다 (예외를 잡어서 처리)
}
@Override
public String take() {
return queue.remove(); // 가져올 데이터가 없으면 NoSuchElementException 을 터뜨린다 (예외를 잡어서 처리)
}
-----------
12:35:32.473 [ 생산자 3] [생산 시도] data3 -> [data1, data2]
Exception in thread "생산자 3" java.lang.IllegalStateException: Queue full
at java.base/java.util.AbstractQueue.add(AbstractQueue.java:98)
at java.base/java.util.concurrent.ArrayBlockingQueue.add(ArrayBlockingQueue.java:329)
add 와 remove 를 활용하면 예외 발생을 확인할 수 있다. 예외는 사용하는 Client 에서 잡아서 알아서 활용하면 되는 것이다. 따라서 이 함수들은 Custom 하게 상황을 처리하라는 의미와 마찬가지로 보면 된다. 참고로 BlockingQueue 란 우리가 만든 인터페이스를 활용할 필요도 없이, 실무에서 진짜 쓸 경우엔 그냥 BlockingQueue<String> 을 선언해서 사용하면 된다.
라이브러리들은 보면 Dough Lea 라는 교수님이 다 만들어 주심. 이 concurrent 패키지의 주요 설계 및 구현을 주도하셨다고 한다. 해당 패키지는 매우 견고하고, 높은 성능을 보장한다 (ConcurrentHashMap 도 이 패키지 소속). 이 패키지는 동시성 문제를 열심히 해결하려 할 뿐만 아니고, 개발자가 각자 자신의 시나리오에 잘 대응할 수 있도록 지원도 해준다. 많은 선배 개발자분들께 감사하고, 더 다음 단계의 고민을 하라는 강사님의 말씀..

출처
[실전 Java 고급 1편]으로 엮인 모든 포스트들은 교육 사이트 인프런의 지식공유자이신 김영한님의 [김영한의 실전 자바 - 고급 1편, 멀티스레드와 동시성] 강의를 기반으로 작성되었습니다. 열심히 정리하고 스스로 공부하기 위해 만든 포스트이지만, 제대로 공부하고 싶으시면 해당 강의를 꼭 들으시는 것을 추천드립니다.
김영한의 실전 자바 - 고급 1편, 멀티스레드와 동시성 강의 | 김영한 - 인프런
김영한 | 멀티스레드와 동시성을 기초부터 실무 레벨까지 깊이있게 학습합니다., 국내 개발 분야 누적 수강생 1위, 제대로 만든 김영한의 실전 자바[사진][임베딩 영상]단순히 자바 문법을 안다?
www.inflearn.com
'Java' 카테고리의 다른 글
| [실전 Java 고급 1편] - 5. Executor Framework 에 대하여 (0) | 2025.04.27 |
|---|---|
| [실전 Java 고급 1편] - 4. CAS와 동시성 컬렉션 (0) | 2025.01.31 |
| [실전 Java 고급 1편] - 2. 메모리 가시성과 동기화 (0) | 2025.01.31 |
| [실전 Java 고급 1편] - 1. Thread 의 제어 (0) | 2025.01.31 |
| [Java] OOP, 객체 지향의 5대 원칙 (SOLID) (0) | 2022.10.12 |