Thread Pool 과 Executor Framework
1. 스레드를 정말 직접 생성하며 사용할까?
스레드를 직접 생성하는 것은 자주 발생하진 않는다. 스레드는 단순 자바 객체를 생성하는 것과는 비교할 수 없는 매우 큰 작업이기 때문이다.
- 메모리 할당 → 물리 메모리 내에서 자신이 사용할 스택 공간 생성이 필요
- 운영체제 자원 사용 → 스레드 생성은 커널 영역에서 이루어진다. 시스템 콜을 통해 처리되며 CPU 및 메모리 소모율이 높다
- 운영체제 스케줄러 설정 → 운영체제가 관리할 스레드가 증가하며 순서 조정이 필요하다
만약 단순한 작업이라면, 오히려 스레드를 준비하는 과정이 더 커서 배보다 배꼽이 더 큰 상황일 수도 있다. 또한, 서버의 CPU 및 메모리는 한정되어 있기 때문에, 요청 당 스레드 할당하는 구조라면 순간적으로 요청이 많아지면 자원이 버티지 못한다. 직접 생성 후 사용한다면 Runnable 인터페이스를 사용할텐데, 이 친구도 만만하진 않다.
public interface Runnable {
void run();
}
Runnable 은 반환 값이 없기 때문에, join 등을 사용해서 멤버 변수에서 가져오는 방식을 활용하며 결과를 가져와야 한다. 또한, run 함수는 체크 예외를 던질 수 없다. 체크 예외 처리 필요시 try / catch 문을 꼭 활용해서 내부적으로 처리해야 한다. 즉, 결과값과 발생한 예외에 대해서 더 알 수 있다면 편리할 것이다.

위 그림처럼 필요한 만큼 스레드 풀을 만들어 스레드를 만들어 두고 (자원을 차지하며) 요청이 오면 스레드를 할당하여 처리, 작업이 완료되면 결과를 처리한 후 스레드를 반납하여 재사용하는 메커니즘을 도입할 수 있다. 이렇게 하면 스레드 생성과 종료 시간을 절약할 수 있다. 실제 스프링 역시 Thread Pool 로 요청들을 처리하는 구조이다. 하지만 막상 구현해보려고 하면, 단순히 자료구조에 넣는 것이 아니라, 아무 작업도 없는데 CPU를 소모하면 안되므로 생명주기 관리, 스레드 할당 등을 구현해야 해서 생각보다 복잡함을 이해할 수 있다. 자바는 역시 이 문제를 해결해주었다. java.util.concurrency 패키지에 있는 Executor Framework 는 이를 구현해놓은 스레드 풀이다.
Executor 는 지금까지 배운 스레드 기술의 총 집합이라고 할 정도로 섬세하게 구현된 라이브러리이다. 실무에서 직접 스레드를 사용하는 경우는 매우 드물고, 이 Executor 를 사용해서 스레드 프로그래밍을 수행한다.
2. Executor Framework - 🚨
Executor 는 프레임워크라고 부를 정도로 중요한 멀티스레드용 도구 모음이며, 멀티 스레딩 및 병렬 처리에서 활용할 수 있는 작업들을 편리하게 사용할 수 있도록 도와준다. 이 Executor 가 어떻게 구성되어 있는지 살펴보자.
public interface Executor {
void execute(Runnable command);
}
간단하게 Executor 에게 수행할 '작업'을 넘기면, Thread Pool 에 있는 누군가가 이 작업을 수행해 주는 구조이다. 앞으로 많이 사용할 이의 구현체 ExecutorService 를 볼 수 있다.
public interface ExecutorService extends Executor, AutoCloseable {
<T> Future<T> submit(Callable<T> task);
@Override
default void close(){...}
...
}
Callable 은 처음에 등장했지만 결과를 반환해주는 Runnable 이다. Future 와 같이 뒤에 더 나온다. ExecutorService 는 정말 많이 사용하게 되며, 기본 구현체는 ThreadPoolExecutor 이다. 작업하는데 1초가 걸리는 Runnable 을 구현한 RunnableTask 가 존재한다 가정하고, 다음 예제를 살펴보자.
public static void main(String[] args) {
ExecutorService executorService = new ThreadPoolExecutor(2, 2, 0
, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<>()); // BQ 도 넣어준다
log("== 초기 상태 ==");
printState(executorService);
executorService.execute(new RunnableTask("Task A"));
executorService.execute(new RunnableTask("Task B")); // max Size 가 2 이기 때문에 여기까지 "없으면" Thread 를 만들고, 그 다음부턴 재사용한다
executorService.execute(new RunnableTask("Task C")); // 그래서 수행 순서가 A,B 가 완료되어야 C,D 가 수행됨을 볼 수 있다
executorService.execute(new RunnableTask("Task D"));
log("== 작업 수행 중 ==");
printState(executorService);
ThreadUtils.sleep(3000);
log("== 작업 수행 완료 ==");
printState(executorService);
executorService.close(); // 다 썼으면 종료, shutdown 이라고 한다
log("== shutdown 완료 ==");
printState(executorService);
}
---------------------
23:46:03.992 [ main] == 초기 상태 ==
23:46:04.015 [ main] [pool= 0, active= 0, queuedTask= 0, completedTask= 0]
23:46:04.016 [ main] == 작업 수행 중 ==
23:46:04.016 [ main] [pool= 2, active= 2, queuedTask= 2, completedTask= 0]
23:46:04.017 [pool-1-thread-2] Task B 시작!
23:46:04.017 [pool-1-thread-1] Task A 시작!
23:46:05.024 [pool-1-thread-2] Task B 완료!
23:46:05.024 [pool-1-thread-1] Task A 완료!
23:46:05.025 [pool-1-thread-2] Task C 시작!
23:46:05.025 [pool-1-thread-1] Task D 시작!
23:46:06.030 [pool-1-thread-1] Task D 완료!
23:46:06.030 [pool-1-thread-2] Task C 완료!
23:46:07.025 [ main] == 작업 수행 완료 ==
23:46:07.025 [ main] [pool= 2, active= 0, queuedTask= 0, completedTask= 4]
23:46:07.026 [ main] == shutdown 완료 ==
23:46:07.026 [ main] [pool= 0, active= 0, queuedTask= 0, completedTask= 4]
위 상황은 기본적인 ExecutorService 에게 생산자 / 소비자 역할을 할 Queue 를 던져주고, 작업을 수행할 스레드 공간을 정의해주면서 생성하였다. 기본적으로 "없을 경우 Thread 생성하고, max 를 넘어가는 선에서는 재사용" 이 원칙이므로, 두번째 작업에서부터는 바로 스레드가 실행되지 않고 대기된다 (Task C,D 가 A,B 완료 이후에 시작). 작업이 완료되면 "pool = 2"의 출력을 유지하는 것으로 보아, Thread 를 종료시키지 않고 재사용하기 위해 Pool에 다시 넣어두고 대기시켜 놓고 있다. 그리고 ES를 shutdown 시키면 비로소 스레드를 파괴시켜 자원을 반납하게 된다.
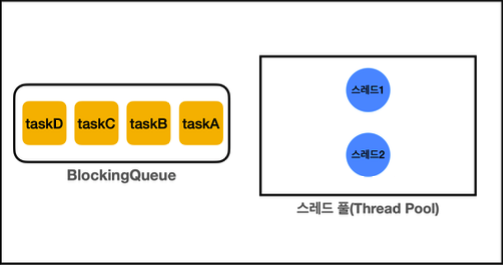
ThreadPoolExecutor 는 크게 두가지로 구성되어 있는데, Thread Pool 과 BlockingQueue 이다. 조금 헷갈릴 수 있어서, 확실히 알고 넘어가는게 좋다. ThreadPool 은 말 그대로 스레드를 보관하는 곳이고, BQ는 우리가 알고 있듯이 "작업"을 보관하는 곳이다 (생산자/소비자를 기억하라).
위에서 수행한 executorService.execute(TASK) 를 호출하면, 메인 스레드가 [생산자]가 되는 것이고, TASK (Runnable) 작업이 BQ에 보관된다. Thread Pool 에서 대기중인 Thread (Thread 생성 시점은 지금 크게 중요하지 않다) 들은 자연스럽게 "소비자"가 되어, 작업을 소비하게 된다. 즉, ES는 "작업"들과 "소비자"로 구성되었다고 볼 수 있다.
생산자 소비자에서 배웠듯이, BQ에 작업이 없다면 스레드 풀의 Thread 들은 Waiting 상태로 대기할 것이다. 그리고 작업이 들어오면 Waiting 에서 내부 구현에 따라 Thread 중 하나를 Runnable 로 바꾸고 작업을 실행시킨다. 이 때, 내부적으로 구현의 차이에 따라 notify() 함수나, LockSupport 의 unpark() 함수를 통해 진행된다고 한다. 천천히 살펴보자.
- corePoolSize - 관리되는 기본 스레드 수
- maximumPoolSize - 관리되는 최대 스레드 수 (생각하는거랑은 좀 다름, 뒤에서 더 나온다)
- keepAliveTime, TimeUnit - 초과해서 만들어진 스레드가 생존할 수 있는 대기 시간 (이 시간 내에 작업을 할당받지 못하면 종료된다)
- BlockingQueue - 작업 보관 Queue

생성된 ThreadPoolExecutor 는 스레드들을 미리 만들어두진 않는다. 메인 스레드가 execute 를 호출하면서 Task 를 전달하면 이를 수행하기 위한 스레드를 생성해서 Thread Pool 에 보관한다 (corePoolSize 까지). 즉, 이번 예시에서는 2로 설정했기 때문에 스레드2까지 만든다. 이후에는 스레드를 생성하지 않고 유지하려하며 재사용을 한다.
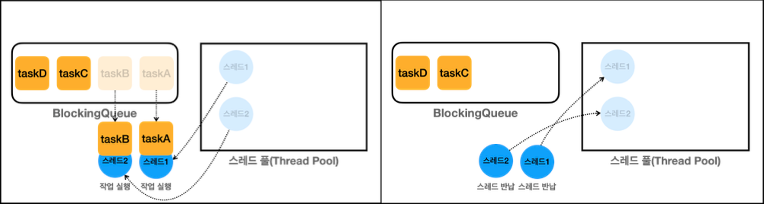
스레드는 상태들이 변경되며 작업을 수행하고, 중간 로그를 보면 작업을 수행중인 [스레드 2개, 풀에서 관리되는 스레드 2개, 대기중인 작업 2개] 로그의 상황을 좌측 그림에서 확인할 수 있다. 작업이 완료되면 우측 그림처럼 스레드 풀에 스레드를 반납하며, WAITING 상태로 다시 변경된다 (실제는 걍 변경만 된다). 이후에 다시 BQ에 작업이 있으니 바로 작업을 다시 수행하기 위해 상변이를 진행하고 작업(Runnable Task)을 수행한다. 이후 close() 를 호출하면 풀에 있는 스레드들을 종료시키며 ExecutorService 를 종료한다 (Java 19 이후에는 close, 이전에는 shutdown).
3. Runnable 의 불편함
위에서 언급했듯이 Runnable 은 반환 값이 없어서 작업의 결과를 반환받을 수 없고, join() 같은 메커니즘을 활용해야 한다. 또한, 예외 처리도 던질 수 없다는 단점이 있었다. Executor 는 이 문제 해결을 도와준다.
public static void main(String[] args) throws InterruptedException {
MyRunnable runnable = new MyRunnable();
Thread thread = new Thread(runnable, "th-1");
thread.start();
thread.join(); // 작업 결과 대기
int result = runnable.val;
System.out.println("작업 결과 값: " + result);
}
static class MyRunnable implements Runnable {
int val;
public void run() {
log("Runnable 시작");
ThreadUtils.sleep(2000); // 작업 소요 시간 2초라고 가정
val = new Random().nextInt(10);
log("create val: " + val);
log("Runnable 종료");
}
}
작업의 결과물을 어딘가에 보관하고, 작업을 완료를 위해 join 으로 기다리는 등 Runnable 을 활용함에 불편한 점이 많다. 즉, Client 에서 이 모든 과정을 다 알고 있어야 한다. 결과를 반환받을 수 있다면 훨씬 간단할 것이며, Executor 는 Callable 과 Future 를 도입하게 된다.
4. Future 에 대하여 1 - 🚨🚨
@FunctionalInterface
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}
우선 Callable 에 대해서 살펴보자. 자바 1.5 부터 등장했고, 반환 타입 Generic V 와 원하는 예외를 던질 수 있도록 설계 되어 있다. 단점을 보완하게끔 만들어졌으니, 이를 어떻게 활용하는지 이전 코드를 바꿔보자.
public class CallableMainV1 {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 우선 Callable 을 쓰려면 Executor 가 필요하다
ExecutorService es = Executors.newFixedThreadPool(1);// 이건 이전에 한거랑 똑같은데, core & max = 1 인 것
Future<Integer> future = es.submit(new MyCallable());// Callable 을 넘기고 Future 을 반환받도록 하는 submit() 함수
Integer result = future.get(); // future 를 활용해서 결과를 가져올 수 있다
// log("result: " + result);
es.close();
}
static class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
log("Runnable 시작");
ThreadUtils.sleep(2000); // 작업 소요 시간 2초라고 가정
int val = new Random().nextInt(10);
log("create val: " + val);
log("Runnable 종료");
return val; // 스레드의 결과를 어떻게 가져올 수 있는걸까?
}
}
}
----------------
21:55:32.523 [pool-1-thread-1] Runnable 시작
21:55:34.536 [pool-1-thread-1] create val: 4
21:55:34.537 [pool-1-thread-1] Runnable 종료
우선 Executors 를 사용해서 편리하게 ExecutorService 를 만들 수 있다. BQ 로는 LinkedBlockingQueue (무한히 넣을 수 있는 Queue 를 가진)를 넣는다. ExecutorService 는 작업을 Callable 로 submit 함수로 전달하고, 반환은 Future 라는 인터페이스를 통해 반환된다. 그리고 get 함수를 통해 작업의 call 함수의 반환 결과를 가져올 수 있다. 위 코드를 보면 오히려 싱글 스레드를 쓰는 것 같은 편리함까지 느낄 수 있다. 다음 SumTask의 예시도 살펴보자.
// SumTaskV1
main {
...
Thread th1 = new Thread(task1, "th1"); // 1~50 까지 더함
Thread th2 = new Thread(task2, "th2"); // 51~100 까지 더함
th1.start();
th2.start();
log("main 스레드는 th1, th2 작업이 끝날때가지 대기");
th1.join();
th2.join();
log("main 스레드는 대기 완료");
...
}
Runnable.run {
...
log("run : 작업 시작");
try {
Thread.sleep(2000); // 예외를 던질 수 없다
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
int sum = 0;
...
}
// SumTaskV2 -> ExecutorService 및 Callable 활용
main {
...
ExecutorService es = Executors.newFixedThreadPool(2); // 두개 돌려야 한다
Future<Integer> future1 = es.submit(task1); // 1 ~ 50까지 더함
Future<Integer> future2 = es.submit(task2); // 51 ~ 100까지 더함
Integer sum1 = future1.get();
Integer sum2 = future2.get();
log("task1 + task2 = " + (sum1 + sum2));
es.close();
}
Callable.call {
...
log("작업 시작 - call()");
Thread.sleep(2000); // 예외를 던질 수 있다!!
int sum = 0;
...
}
제일 처음에 쓰레드 기본으로 했던(https://mooncake1.tistory.com/296) SumTask 를 Callable 로 바꿔보면, int result 도 사라지고, 굳이 ThreadUtils 를 만들 필요 없이 Thread.sleep 해서 예외를 던질 수도 있게 되었다. 또한, main 함수에서도 start, join 을 계속 할 필요 없이 submit 후 Future 를 통해 간단히 결과만 받아오면 된다.
편리한건 편리한거고, 라이브러리에 대한 이해가 있어야 오류 없이 쓸 수 있는 것이다. 메인 스레드는 submit() 함수 이후 기다리지 않는다. 바로 get() 을 호출한다. 이 시점에 ExecutorService 는 작업을 이미 완료했거나, 작업을 하는 중일 수도 있다. 작업을 완료했으면 반환하면 되는데, 작업을 완료 못했으면 어떻게 되는걸까? 바로 값을 주는게 아닌, Future 를 주는 이유는 무엇일까? Future 에 대해 더 자세히 알아보자.
일반적으로 MyCallable 작업은 곧바로 시작되는 것이 아니다. 스레드 풀에서 스레드가 작업을 꺼내서 실행까지 해야한다. 즉, "나중에 이 MyCallable 작업을 누군가가 대신 수행해주는 것"이다. 미래에 어떤 시점에 누군가가 대신 수행해 준 결과를 받을 수 있도록 준비된 객체가 Future 객체이다.
// V1 에서 log 를 좀 더 찍어보자
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 우선 Callable 을 쓰려면 Executor 가 필요하다
ExecutorService es = Executors.newFixedThreadPool(1);// 이건 이전에 한거랑 똑같은데, core & max = 1 인 것
Future<Integer> future = es.submit(new MyCallable());// Callable 을 넘기고 Future 을 반환받도록 하는 submit() 함수
log("future 즉시 반환, future = " + future);
log("future.get() - [블로킹] 메소드 호출 시작 -> main 스레드 WAITING");
Integer result = future.get(); // *메인 스레드는 여기서 기다린다
log("future.get() - [블로킹] 메소드 호출 완료 -> main 스레드 RUNNABLE");
log("result: " + result);
log("future 완료, future = " + future);
es.close();
}
-----------
22:08:54.771 [pool-1-thread-1] Runnable 시작
22:08:54.771 [ main] future 즉시 반환, future = java.util.concurrent.FutureTask@79698539[Not completed, task = thread.sec11_executor_1.future_callable.CallableMainV2$MyCallable@6b2fad11]
22:08:54.778 [ main] future.get() - [블로킹] 메소드 호출 시작 -> main 스레드 WAITING
22:08:56.790 [pool-1-thread-1] create val: 0
22:08:56.790 [pool-1-thread-1] Runnable 종료
22:08:56.791 [ main] future.get() - [블로킹] 메소드 호출 완료 -> main 스레드 RUNNABLE
22:08:56.791 [ main] result: 0
22:08:56.792 [ main] future 완료, future = java.util.concurrent.FutureTask@79698539[Completed normally]

Callable Task 가 submit()을 통해 전달되면 ES는 먼저 Future 객체를 만들어서 Task를 넣어두고, "완료 여부"와 "결과"를 형성해둔다. 당연히 처음에는 false 와 결과도 없다. 그리고 Future 객체 자체가 BlockingQueue에 들어간다. 그리고 담기까지가 submit() 함수의 종료이므로, 결과로 작업에 들어간 Future 객체를 바로 반환한다 (위에서 submit 함수의 반환 값이 Future 객체임). 그래서 바로 찍은 로그는 다음과 같다.
22:08:54.771 [ main] future 즉시 반환, future = java.util.concurrent.FutureTask@79698539[Not completed, task = thread.sec11_executor_1.future_callable.CallableMainV2$MyCallable@6b2fad11]
구현체인 FutureTask 객체의 상태를 보면, "Not completed" 의 값이 출력되고 있다. 말 그대로 작업은 아직 완료되지 않았다. 이 시점에 포인트는, 생성된 Future 는 "submit" 함수 호출 즉시 반환되기 때문에, 진행하고 있는 스레드는 바로 다음 코드를 이어나갈 수 있다. submit 함수는 Thread.start() 느낌과 유사하다고 보면 된다 (바로 이어나감).

이후 Future 은 내부의 Runnable 도 구현하고 있기 때문에, 할당받은 Thread1 은 Future 의 run() 메소드를 수행하고, run() 메소드는 FutureTask 객체(본인)가 보관 중인 TaskA (Callable)를 가지고 call() 함수를 호출하게 된다 (내부 코드를 보면서 확인). 이제 Thread1 이 Callable에 있는 작업을 실행하기 시작했다! 하지만 main 함수는 기다리지 않고 get 함수를 호출한다.
참고로 이 시점에서 작업이 들어왔음을 감지하고, Thread1 이 작업을 시작하게 하는건 누가하는거지? 라는 의문이 들었는데, 이건 결국 생산자/소비자 모델을 덜 이해한 질문이였다. 복습하고 꼭 이해하고 넘어가라. 감지하는게 아니라 깨워진다는 것을 이해하자

이 시점에 TaskA 의 작업이 완료되지 않았기 때문에, 요청 스레드는 Future 가 완료될 때 까지 대기한다. 즉 이 경우 main 스레드는 WAITING 상태로 상변이한다. 만약 완료된 상태면 (완료 True) 상변이 없이 바로 결과 반환시킨다. 즉, Future 객체에는 언제든 get 함수를 호출할 수 있지만, not completed 라면 호출 스레드를 즉시 WAITING 으로 상변이 시킨다. 이처럼 다른 작업이 완료될 때까지 호출 스레드를 대기시키는 함수를 블로킹 메소드라고 한다. 우린 또 다른 블로킹 메소드를 본 적이 있는데, 바로 Thread.join() 함수이다. 즉 요청 스레드가 WAITING 으로 될 수 있다는 점을 인지하고 있어야 한다.

main 스레드는 대기 중, thread1 스레드는 작업 중이다. 그리고 작업이 완료된다면, Thread1 스레드는 다음과 같은 순서로 일을 마무리한다. 중요한 점은 직접 요청 스레드를 깨운다는 점이다.
- call 함수로 TaskA의 작업을 완료 후, 반환 결과를 TaskA에 담는다 (살짝 이해 안됨)
- Future 객체의 완료 상태를 'Completed'로 변경한다
- 요청 스레드 (이 경우 main 스레드) 를 깨워서 RUNNABLE 상태로 상변이 시킨다
이제 main 스레드는 RUNNABLE 상태가 되었고 get 함수의 결과를 반환할 수 있고, 이 시점 이후 언제든 동일한 Future 의 get 함수를 통해 결과를 대기없이 바로 조회할 수 있다. 수행을 완료한 Thread1 스레드는 다시 WAITING 상태가 되고 Thread Pool 로 반납된다. 이제 위에서 찍은 로그들의 모습과 그 이유를 모두 이해할 수 있다!
그렇다면 왜 굳이 Future 객체를 도입했을까? es.submit() 함수 호출했을 때 바로 결과가 나올리가 없으니, 그냥 이 시점에서 블로킹할 수는 없었을까? 마치 Thread.join 함수처럼 말이다. Future 가 필요한 이유를 조금 더 알아보자.
5. Future 에 대하여 2
필요성을 이해해보려면 ThreadPool 에 전달되는 작업이 하나가 아닌, 여러개인 상황에서의 생각이 필요하다. 위에서 잠깐 등장했던 SumTask 두 가지를 수행하는데, 작업이 한가지 이상을 ExecutorService 에게 요청한다고 해보자. 그리고, 존재하지 않지만 아래 코드처럼 사용된다고 가정해보자.
Integer sum1 = es.submit(task1); // 여기서 블로킹 후 결과 반환. (get 함수 없음)
Integer sum2 = es.submit(task2); // 여기서 블로킹 후 결과 반환. (get 함수 없음)

위 코드 상황은 왼쪽 그림처럼 진행이 될텐데, 요청스레드가 task2 를 전달하기 전에 blocking 되고 task1의 작업을 대기하게 된다. 즉, task2를 ThreadPool 에게 전달할 수 없어서, 그냥 싱글 스레드로 순차적 작업한 것과 똑같은 상황이다. 각각 2초가 걸리는 작업이라면, 멀티 스레드를 활용하면 2초면 모든 작업을 끝낼 수 있지만 위 코드 상황대로면 총 4초 걸리는 것이다. 즉, Future 가 없으면 그냥 싱글 스레드가 작업하는거랑 차이가 없어진다.
Future 를 사용하면 상황이 다르다. 요청 스레드는 Task1 을 수행 요청한 뒤 완료를 기다리지 않고 Task2 를 이어서 바로 요청한다. 요청 스레드는 작업을 원하는대로 다 지시한 이후 원할 때 Future.get 을 통해 대기하면 되는 것이다! 더욱이 Future1.get 을 해서 Future1의 작업을 기다리는 동안 Future2 도 작업을 완료했다면, Future2.get 을 할 때는 대기하지 않아도 된다. 멀티 스레딩을 제대로 활용할 수 있는 구조인 것이다 (요청 스레드가 원할 때 get 함수를 쓸 수 있다는 것도 큰 장점인 것 같다).
Future<Integer> future1 = es.submit(task1);
Integer sum1 = future1.get(); // 2초 기다림
Future<Integer> future2 = es.submit(task2);
Integer sum2 = future2.get(); // 2초 기다림
// ---------- 혹은
Integer sum1 = es.submit(task1).get(); // 더 이상 작업할당 없이 2초 기다림
...
만약 위 상황들 처럼 사용한다면, 이 방향 역시 단일 스레드로 작업을 수행하는 것과 아무 차이가 없이 사용하는 것이다. 따라서 작업이 많다면, 반드시 작업을 다 던진 후에 결과를 조회하는 이 ExecutorService 를 통해 멀티 스레딩을 제대로 수행하는 방법이다. Future 의 또다른 기능들과, 그 중 cancel 이라는 함수에 대해 더 알아보자
- boolean cancel(booleam mayInterruptIfRunning)
- 아직 완료되지 않은 작업을 취소한다 (반환된 Future 에 할당된 Task) -> Future 를 "취소" 상태로 변경한다
- true 를 넘기면 실행 중인 작업을 Thread.interrupt() 로 중단, false 일 경우 작업은 완료시켜본다
- 작업이 성공적으로 취소되었으면 true, 아니라면 false
- "취소" 상태의 Future 의 결과를 get 호출하면 CancellationException 이 발생
- 아직 완료되지 않은 작업을 취소한다 (반환된 Future 에 할당된 Task) -> Future 를 "취소" 상태로 변경한다
- boolean isCancelled()
- cancel 여부를 반환한다
- cancel 여부를 반환한다
- boolean isDone()
- 작업 완료의 여부를 확인한다. 정상 수행, 취소, 예외 발생 종료 모두 true 를 반환. 완료 안되었으면 false
- 작업 완료의 여부를 확인한다. 정상 수행, 취소, 예외 발생 종료 모두 true 를 반환. 완료 안되었으면 false
- V get()
- 대기 or 반환
- InterruptedException → 대기중인 스레드가 Interrupt 발생
ExecutionException → 작업 중 예외가 발생한 경우 (뒤에서 자세히 나온다) - timout parameter 를 전달하면 예외를 발생시킨다 (요청 스레드가 대기할 최대 시간 지정)
- 대기 or 반환
// private static boolean mayInterruptIfRunning = true;
private static boolean mayInterruptIfRunning = false;
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(1);
Future<String> future = executorService.submit(new MyTask()); // 작업은 1초당 한번씩 1~10까지 Count
log("Future.state: " + future.state());
// 일정 시간 후 취소 시도
ThreadUtils.sleep(3000); // 3초 뒤
log("future.cancel(" + mayInterruptIfRunning + ") 호출");
boolean cancelResult = future.cancel(mayInterruptIfRunning);
log("cancel(" + mayInterruptIfRunning + ") result : " + cancelResult);
// 결과 확인
try {
log("Future.result: " + future.get());
} catch (CancellationException exception) { // 런타임이라 잡고 싶으면 잡는거임
log("Future 는 취소되어서 get 을 할 수 없습니다");
} catch (InterruptedException | ExecutionException exception) { // 그냥 get 처리 중에 발생
exception.printStackTrace();
}
executorService.close();
}
---------------
// true 일 경우
13:04:25.065 [ main] Future.state: RUNNING
13:04:25.065 [pool-1-thread-1] 작업 중 : 0
13:04:26.076 [pool-1-thread-1] 작업 중 : 1
13:04:27.077 [pool-1-thread-1] 작업 중 : 2
13:04:28.076 [ main] future.cancel(true) 호출 // cancel 을 호출해서 스레드 작업을 종료
13:04:28.077 [pool-1-thread-1] 인터럽트 발생
13:04:28.084 [ main] cancel(true) result : true
13:04:28.085 [ main] Future 는 취소되어서 get 을 할 수 없습니다
mayInterruptIfRunning 값을 true 로 해놓으면, THREAD 작업을 바로 취소시킨다. 그리고 Thread.sleep 도중 발생했으므로 Interrupt 도 발생하는 것을 볼 수 있다 (즉, WAITING -> RUNNABLE -> canel로 종료). 만약 interrupt 처리가 잘 되어있지 않다면 당연히 작업은 진행된다 (복습 : Interrupt 는 강제 종료가 아닌 상태 개념이기 때문에, 반응하거나 체크하는 로직이 없다면 스레드는 무시한다). 위에서는 Interrupt 를 잘 구현해놨기 때문에 중단이 된다.
// false 일 경우
13:22:57.210 [pool-1-thread-1] 작업 중 : 0
13:22:57.210 [ main] Future.state: RUNNING
13:22:58.217 [pool-1-thread-1] 작업 중 : 1
13:22:59.218 [pool-1-thread-1] 작업 중 : 2
13:23:00.218 [ main] future.cancel(false) 호출
13:23:00.222 [pool-1-thread-1] 작업 중 : 3
13:23:00.226 [ main] cancel(false) result : true // 취소 체크는 되었지만, 뒷단에서 끝까지 수행하긴 함
13:23:00.226 [ main] Future 는 취소되어서 get 을 할 수 없습니다
13:23:01.223 [pool-1-thread-1] 작업 중 : 4
13:23:02.223 [pool-1-thread-1] 작업 중 : 5
13:23:03.226 [pool-1-thread-1] 작업 중 : 6 // 작업은 취소처리되었지만 thread 를 방해하진 않는다
...
false 가 전달될 경우는 실행되는 작업은 그냥 냅두기 때문에 위처럼 끝까지 작업은 하게 허용하는데, 결과값을 반환받을 수는 없다 (canel 처리가 되었기 때문). 따라서 사실 실제로 cancel 함수의 결과가 false 로 반환되는 경우는 잘 없다 (이미 작업이 완료되었거나, 취소된걸 또 취소하려고 할 때 정도). 이렇게 작업을 취소하는 로직도 이해해볼 수 있었다. cancel 시킨 작업의 결과는 반환받을 수 없는 원칙을 기억하자. 이제 cancel 의 Exception 받기에 대해서 더 알아보자. Future 에서는 get 으로 결과뿐만 아니라 작업 도중 발생한 예외까지도 받을 수 있다.
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(1);
Future<Integer> future = es.submit(new ExCallable()); // 이 작업은 바로 IllegalStateException 을 던진다
ThreadUtils.sleep(1000); // 작업 잠시 대기
try {
log("future.get() 호출 시도, future.state(): " + future.state()); // 예외 터졌으니 FAILED 상태
Integer result = future.get(); // get 함수 수행
log("result val = " + result); //
} catch (InterruptedException e) { // 대상 스레드가 Interrupt 받는게 아니라 future.get 하는 도중 요청 스레드가 Interrupt 받는 경우
log("요청 스레드 대기 중 인터럽트 발생");
throw new RuntimeException(e);
} catch (ExecutionException e) { // 실행중에 발생하는 예외를 반환해준다. 발생한 예외 그대로 나오긴 어렵고, 대체 예외가 나와준다
// 근데 나는 Illegal 을 던졌는데?
// 예외는 원래 Chain 으로 물린다 -> e 를 Throwable 에 두며는 근본 원인을 넘겨주는 것 (이건 기본기)
log("e = " + e);
Throwable cause = e.getCause(); // Future 안에서도 원본 예외를 Throwable 로 받아둔다
log("cause = " + cause);
}
es.close();
}
----------------------
12:15:38.215 [pool-1-thread-1] Callable 실행, 예외 발생
12:15:39.175 [ main] future.get() 호출 시도, future.state(): FAILED
12:15:39.176 [ main] e = java.util.concurrent.ExecutionException: java.lang.IllegalStateException: [예외발생]
12:15:39.176 [ main] cause = java.lang.IllegalStateException: [예외발생]
작업은 Exception 으로 마무리가 되기 때문에 .state 은 FAILED 상태이다. 또한, 발생한 예외는 ExecutionException 으로 감싸져서 던져지는데, 자바 예외처리 기본기에 따라서 원본 exception 은 Throwable 에 담긴채로 던질 수 있고, 이렇게 개발하는게 정석이다. 예외도 객체이기 때문에 가능한 것이며, .get 함수 역시 이 방식으로 개발되었다. 따라서, e.getCause 로 Throwable 을 가져오면, 어떤 예외가 담겼는지 확인할 수 있다 (개인적으로 좀 신기했던건, ExecutionException 의 상위인 Exception 까지 잡는다는 것이다. 아마 내부적으로 Exception 으로 잡고, 모든 ExException 으로 교체시켜서 그런 것 같다).
Future 의 상태가 Failed 면 무조건 실패로, 예외를 던지고 있는 상황이라고 보면 된다. 따라서 if 문으로 "FAILED 이면 exception 을 확인해라" 같은 조건절로 개발을 해놔도 안정적일 것 같다. "멀티스레딩을 마치 간단하게 개발하는 것처럼 쓸 수 있게 해주기"가 ExecutorService 의 주된 목표인만큼 얼마나 잘 설계되었는지 알 수 있다.
마지막으로 Future 은 여러 작업들을 한번에 던지는 방식도 존재한다. invokeAll (Future List 로 결과 반환) 과 invokeAny ( 바로 결과 반환 ) 두 함수가 바로 이를 지원하는 함수이다.
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(10);
CallableTask task1 = new CallableTask("task1", 1000); // 아무일도 안하고 대기한 시간 반환하는 작업
CallableTask task2 = new CallableTask("task2", 2000);
CallableTask task3 = new CallableTask("task3", 3000);
List<CallableTask> tasks = List.of(task1, task2, task3);
// 참고로 invokeAll 역시 InterruptedException 을 던지는데, 이는 "바로 대기" 하기 때문이다
// 앞서 살펴본 submit 으로 하나씩 작업을 전달하는 형태가 아니기 때문에, 바로 전체 작업을 던진 뒤 대기를 해도 되는 것이다!
// Q)) 그럼 얘는 왜 굳이 Future 를 썼을까? 그냥 Class 의 동작성 일치 때문인 것 같다
List<Future<Integer>> futures = es.invokeAll(tasks);
for (Future<Integer> future : futures) {
Integer val = future.get();
log("value = " + val);
}
es.close();
}
invokeAll 함수는 Callable 작업들을 Collection 으로 묶은 parameter 를 전달 받아, 이를 하나의 작업 단위로 인식하고 바로 모든 작업이 종료될 때까지 대기한다 (왜 Future 임에도 바로 대기하는지는 바로 이해할 수 있으면 좋음). 그리고 작업이 완료되면 future List 를 반환해서 결과를 바로 get 으로 확인할 수 있는 구조이다 (get 할 때는 대기가 당연히 없겠지).
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(10);
CallableTask task1 = new CallableTask("task1", 1000);
CallableTask task2 = new CallableTask("task2", 2000);
CallableTask task3 = new CallableTask("task3", 3000);
List<CallableTask> tasks = List.of(task1, task2, task3);
// 다 취소시키지만, Interrupt 를 거는 행위이기 때문에 Interrupt 체킹이 안되어 있으면 딱히 잡진 않는다
// 하지만 작업 결과는 받아올 수 없다. 그래서 Future 를 제공해주지 않는다
Integer firstFinishedResult = es.invokeAny(tasks);
log("(firstFinished) value = " + firstFinishedResult);
es.close();
}
invokeAny 는 위처럼 그냥 전달한 모든 Task 중에 가장 첫 결과를 반환하면 된다. 다른 작업들의 결과는 반환받지 못하게 하기 위해서 Future 도 제공해주지 않는다. 역시 바로 요청 스레드는 대기상태로 들어간다. 자원이 많이 남아돌아서 먼저 완료된 결과 하나만 주면 충분한, 그런 상황에서 쓸 수는 있을텐데 자주 사용되지는 않을 것 같다. 반대로, 결과가 다 필요하면 invokeAll 을 사용하면 되는 것이다.
단일 스레드로 작업을 실행하는 로직을 ExecutorService 를 사용하여 간단하게 멀티 스레딩을 지원하도록 개선하는 문제 예제를 강의에서 같이 풀기도 했다 (스레드 생성하고 앉아있으면 적게 걸리는 것도 아니다). 참고로 ExecutorService 에서 "결과값이나 예외를 처리할 필요가 없고 스레드 풀만 편하게 쓰고 싶을 경우"를 위해 execute(Runnable) 함수도 제공한다. 이 때는 그냥 뒷단에서 Thread.start() 와 동일하게 동작한다고 보면 되고, 만약 요청 스레드 대기를 활성화하고 싶으면 동일하게 submit(Runnable전달) 로 사용한 후, Future<?>.get 을 사용하면 된다. 반환값은 NULL 이지만, 요청 스레드가 작업 완료를 대기하게 된다. ES 는 AutoClosable 이던데.. .편하게 쓸 수 있는 방법 없을까 싶기도 하다.

정리하며
실전 자바 고급 1편은 솔직히 정말 어려운 것 같다는 생각이 많이 든다. 내용이 많아서 이전 내용이 잘 기억 안나지만, 연결되며 이해되어야 한다는 것이 많이 느껴진다. 코드들을 통해 로직만 처리하는 것이 아니라, "운영 입장에서 상황에 대한 제어"를 하는 영역이기 때문에, 그만큼 어려운 것 같은데, 이런게 정말 중요하다는걸 느끼고 있다.
ExecutorService 는 Thread 관련 Test 를 할 때 GPT의 추천으로 그냥 간략하게 써본 적은 있는데, 솔직히 무슨 차이인지 잘 모르고 그냥 사용했었다. 정말 잘못 사용하고 있었고, 이번 기회에 자바 멀티스레딩의 기본기에 대해서 정말 확실하게 배울 수 있어서 너무 좋은 강의인 것 같다. ExecutorService 가 대단한 점은 어려운 멀티 스레딩을 최대한 단일 스레드에서 프로그래밍 하고 있는 것처럼 추상화시켜서 제공해주고 있다는 것이다. 멀티 스레딩을 추상화하다니.. 정말 대단한 프레임워크인 것 같다.
출처
[실전 Java 고급 1편]으로 엮인 모든 포스트들은 교육 사이트 인프런의 지식공유자이신 김영한님의 [김영한의 실전 자바 - 고급 1편, 멀티스레드와 동시성] 강의를 기반으로 작성되었습니다. 열심히 정리하고 스스로 공부하기 위해 만든 포스트이지만, 제대로 공부하고 싶으시면 해당 강의를 꼭 들으시는 것을 추천드립니다.
'Java' 카테고리의 다른 글
| [Java Multi-Threading] 생산자 소비자 Queue 예제 연습해보기 (2) | 2025.05.30 |
|---|---|
| [실전 Java 고급 1편] - 6. Executor Framework 에 대하여 2 (0) | 2025.05.04 |
| [실전 Java 고급 1편] - 4. CAS와 동시성 컬렉션 (0) | 2025.01.31 |
| [실전 Java 고급 1편] - 3. 생산자 소비자 문제 (BlockingQueue 만들기까지) (0) | 2025.01.31 |
| [실전 Java 고급 1편] - 2. 메모리 가시성과 동기화 (0) | 2025.01.31 |