CAS, 동기화와 원자적 연산
1. 원자적 연산에 대하여
CS에서 원자적 연산이라 함은, 해당 연산이 더 이상 나눌 수 없는 단위로 수행된다는 것을 의미하며, 중단되지 않고 간섭 없이 완전히 실행되거나 전혀 실행되지 않는 연산이다. 즉, 다른 스레드의 간섭 없이 안전하게 처리되는 연산이라는 뜻이다. 가령, i = 1 은 둘로 쪼갤 수 없는 원자적 연산이다. 하지만, i = i+1 은 원자적 연산이 아니라, i 값을 읽고, 1을 더하고, 더한 값을 i에 대입하는 세가지 순서로 나뉘어진다. 이 모든 것은 CPU 입장에서이다! 원자적 연산이 아닌데 멀티 스레딩이 적용되는 상황에서 우리가 동기화 처리를 해왔던 것이다. 다음 상황을 살펴보자
public class V1BasicInteger implements IncrementInteger{
private int value;
@Override
public void increment() {
value++;
}
@Override
public int getValue() {
return this.value;
}
}
----- 해당 작업을 1000개의 스레드가 돌리게끔 설계 후 실행
thread.sec9_cas.V1BasicInteger's result :: 984
절대 1000이 나오지 않는다. 우리는 지금까지 이 상황을 막기 위해서 동기화 기법들을 공부했던 것이다. 혹시 volatile 을 적용하면 해결될까? 지금까지 공부했듯이 지금 메모리 가시성 문제는 아니다. 각 CPU 가 자신의 캐시 메모리에서 읽지 않는다 한들, A 스레드 값을 CPU 가 읽고 다음 연산을 수행하기 전에 B 스레드가 CPU 를 읽는 과정이 수행 되기 때문이다. Volatile 은 연산 문제를 해결하는게 아니라, 단순히 캐시 메모리를 무시하게 해줄 뿐이다.
"이 문제가 발생하는 이유는 무엇인가?" 라고 했을 때 멀티스레딩, 스레드가 읽었을 때 다른 스레드가 읽어서, 뭐 이런 대답도 맞다. 하지만 "저 연산이 CPU 입장에서 수행 단위가 나뉘어져 있기 때문이다" 라고 말하는게 가장 정확하다. 만약 수행 단위가 나누어져 있지 않은 원자적 연산이라면, 스레드 문제는 발생하지 않는다. 만약 synchronized 함수를 하면 1000이 찍힐 것이다. 그리고 volatile 역시 제외해도 synchronized 에 포함되는 것도 알고 있다.
이처럼 함수를 동기화 기법 처리해서 수행해도 되지만, CPU 입장에서 수행하려는 코드를 "원자적 연산"으로 정의해줄 수는 없을까? 자바에서는 안전하게 원자적 연산을 수행할 수 있는 클래스들을 제공하는데, AtomicInteger는 그 중 하나이다.
// 동기화 처리를 안해도 된다. 내부적으로 구현되어 있음
public class V3AtomicInteger implements IncrementInteger{
private AtomicInteger atomicValue = new AtomicInteger(0);
@Override
public void increment() {
atomicValue.incrementAndGet();
}
@Override
public int getValue() {
return atomicValue.get();
}
}
------------
thread.sec9_cas.V1BasicInteger's result :: 996
thread.sec9_cas.V2VolatileInteger's result :: 989
thread.sec9_cas.V3AtomicInteger's result :: 1000
이 결과를 보면 AtomicInteger를 활용하는 것은 1000개의 스레드가 안전하게 증가 연산을 수행했음을 알 수 있다. sync 함수 없이, 자바 클래스 내부적으로 다 동시성 구현이 되어 있어서 안전하게 연산을 오류 없이 처리할 수 있었다. 값을 공유해야 하는데, 여러 스레드가 변경하며 공유해야 한다면 AtomicInteger(Long, Boolean 등) 을 사용하면 된다. 그럼 sync 함수도 되고, CAS 연산도 되는데, 성능은 어떤지 생각해볼 필요가 있다.
private static void test(IncrementInteger integer) {
long startMs = System.currentTimeMillis();
for (long i = 0; i < CNT; i++) {
integer.increment();
}
long endMs = System.currentTimeMillis();
System.out.println(integer.getClass().getSimpleName() + ":: ms = " + (endMs - startMs));
}
----------
V1BasicInteger:: ms = 165 // CPU 캐시의 위력
V2VolatileInteger:: ms = 821 // volatile 은 최대 10배까지도 성능 차이가 간다
V3SyncInteger:: ms = 2019 // Atomic 연산보다 성능이 느리다
V4AtomicInteger:: ms = 983
Atomic 클래스를 활용한 것이 sync 함수, 심지어 ReentrantLock 을 활용하는 경우보다 약 1.5~2배 빠르다. i의 값을 증가시키는 연산은 무조건 원자적 연산은 아니다. 따라서, sync, Lock 등을 활용했을텐데.. 성능은 훨씬 좋다. 왜 그럴까?? 이유는 AtomicInteger는 락 기법을 사용하지 않기 때문이다. (*CAS 연산과 원자적 연산은 다른 말이다. CAS 는 기법이다)
2. CAS 연산에 대하여 ⭐
참고로 우리가 직접 CAS 연산을 구현하는 경우는 없다. 대부분 복잡한 동시서 라이브러리들이 CAS 연산을 사용한다 (AtomicXX). 하지만 CAS 연산은 반드시 원리를 이해해야 하는 중요한 컴퓨터 과학 내용이다.
우리가 지금까지 열심히 배웠단 Lock, sync 함수 사용은, 직관적이고 쉽지도 않았지만, 락을 지속적으로 확인, 작업 수행, 락 반납, State 전이 등을 지속적으로 반복해야 한다. 즉, 상당히 무거운 방식이다. 이건 Java 만의 문제가 아니라, 컴퓨터 과학안에서의 문제이다. 따라서, 락을 걸지 않고 원자적인 연산을 수행하는 방법이 바로 CAS(Compare And Swap) 연산이다.
CAS 연산은 락을 완전히 대체할 수는 없고, 작은 단위로 적용하기에 최적화 되어 있다 (연산 단위를 분석하는 Level). 따라서, 락이 기본이되, 특수한 경우 성능을 높이기 위해 CAS 연산을 적용하는 느낌으로 이해하자.
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(0);
System.out.println("start val = " + atomicInteger.get());
boolean result1 = atomicInteger.compareAndSet(0, 100); // 비교하고 값이 맞다면 비교해라
System.out.println("result1 = " + result1 + ", value = " + atomicInteger.get());
boolean result2 = atomicInteger.compareAndSet(0, 500); // 비교하고 값이 맞다면 비교해라
System.out.println("result1 = " + result2 + ", value = " + atomicInteger.get());
}
-------------
result1 = true, value = 100
result1 = false, value = 100
AtomicInteger 의 내부적인 cas 함수는 CAS 기법을 이해하는데 기본적인 함수라고 할 수 있다. 즉, "현재 이 값이 expected 값이면, new 값과 바꾸고 아니면 바꾸지 마라"의 연산으로, result2 는 실패하고 값이 유지됨을 알 수 있다 (트랙젝션 하는 느낌이다). CAS 연산은 그냥 이걸 말하는 것이긴 한데, 이 연산 하나로 많은 것을 이룰 수 있는 것이다. 단순하지 않은 이유는, 이 메서드가 CPU 가 방해받지 않는 "원자적으로 실행" 되기 때문이다.
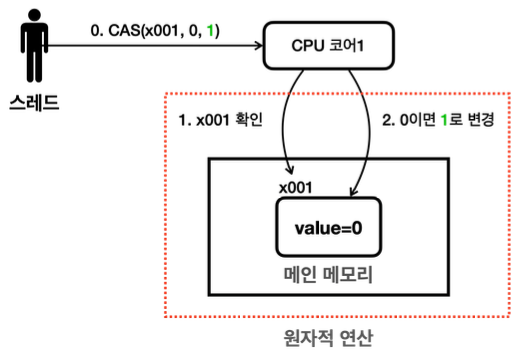
위 상황을 보기만 하면 if 절 나열 같은데, 이상하다고 느껴지는게 정상이라고 한다. CAS 연산은 "메모리에 있는 값이 기대하는 값이라면 원하는 값으로 변경"하는 연산을 말한다. 이 연산이 원자적인 이유는 CPU 하드웨어의 지원을 받기 때문이다. 원자적이지 않은 일렬의 연산 과정을 CPU 하드웨어 차원에서 특별하게 하나의 연산으로 묶어서 제공한다. 대부분의 현대 CPU들은 CAS 연산을 위한 명령어를 제공한다.
즉, 위에서 수행한 compareAndSet 연산은 두 과정을 하나로 묶어서 원자적인 명령으로 실행한다. 1) x001의 값을 확인하고, 2) 읽은 값이 0이면 1로 변경한다. 이렇게 두 과정을 하나의 원자적 명령으로 만들기 위해 CPU에게 내릴 수 있는 CAS라는 특수한 명령어를 사용한다고 한다 (OS 개입 없이 컴파일러가 CAS 명령어로 컴파일). 이는 1번 연산과 2번 연산 사이에 다른 스레드가 x001 의 값을 변경하지 못하게 막는 과정이다.
즉, 위에 compareAndSwap 함수는, x001, 0, 100 을 같이 CPU 코어에게 전달한다 (전달하는 과정에서 CAS 명령어가 사용됨). 그럼 CPU는 x001을 확인하는 동시에 막아버린다 (CPU 입장에서의 락이라고 볼 수 있지만, 락이라고 하지 않는다. CPU는 물리적으로 확인하고 막는다). CPU 입장에서 이건 정말 찰나의 순간이기 때문에, 성능에 큰 영향을 주지 않는다. 그래서 CAS 연산은 CPU가 연산들을 하나로 묶어서 원자적으로 처리해주는 기법인건 알겠는데, 이게 락을 어떻게 대체하는걸까?
3. CAS 연산의 락 대체 🚨
// 만약 CompareAndSet 을 하는 시점에서, 다른 Thread 가 AtomicInteger 의 값을 변경해 놓았었다면?? -> False 가 반환되고 수행되지 않는다
// while 문이니까 다시 수행할 것이다 - 이 때 타 thread 의 방해가 없다면 정상적으로 수행된다
// * 락을 사용하지 않고 CAS 연산을 사용해서 동시성을 보장하는 상태에서 값을 변경한 모습 *
private static int myIncrementAndGet(AtomicInteger atomicInteger) {
int getValue;
boolean result;
do { // 먼저 시도하고 while 진행
getValue = atomicInteger.get(); // 현재 값 읽는다
log("getValue: " + getValue);
result = atomicInteger.compareAndSet(getValue, getValue + 1); // update 명령을 치는 시점에 같다면 올려라 - CAS 연산 지원 (Thread-safe)
log("result: " + result);
} while (!result);
// 연산 성공시 빠져나옴
// 연산 성공시 빠져나옴
// getValue + 1 을 하는 이유 : result 찍고 여기까지 오는 중 타 스레드가 또 atomicInteger 를 바꿀 수 도 있다
// 따라서 이 함수의 결과를 반환해주기 위해 getValue +1 을 해준다
return getValue + 1;
}
AtomicInteger 는 기본적으로 incrementAndGet 이란 함수를 지원해주지만, 직접 만들어봄으로써 락을 대체했다. 위 함수에서 compareAndSet 을 사용하는 부분은 CAS 연산을 명령하는 것이다. 막상 CAS 연산이 수행될 때, 예상값과 다르다면 (getValue 를 읽고 CAS 연산으로 넘어가는 사이에 어떤 스레드라도 이 값을 건드렸을 경우) 수행이 되지 않고, while 문에 의해 재실행된다.
참고로 atomicInteger.get() 으로 반환해주지 않는 이유는 다른 스레드가 return 하기 전에 또 건드려서, 해당 함수의 결과를 반환해주지 않을 수 있기 때문이다. 반환의 목적은 "현재 저장된 값"이 아니라 "해당 함수의 결과"이기 때문에, getValue + 1 을 해준다.
public static void main(String[] args) throws InterruptedException {
AtomicInteger atomicInteger = new AtomicInteger();
System.out.println("start val = " + atomicInteger.get());
Runnable runnable = new Runnable() {
@Override
public void run() {
myIncrementAndGet(atomicInteger); // 위에서 만든 거
}
};
List<Thread> ths = new ArrayList<>();
// ... Thread 2 개 만들고 join 함
int result = atomicInteger.get();
System.out.println("result = " + result);
}
----------------
start val = 0
21:57:40.847 [ Thread-0] getValue: 0
21:57:40.847 [ Thread-1] getValue: 0
21:57:40.855 [ Thread-0] result: true
21:57:40.855 [ Thread-1] result: false
21:57:40.855 [ Thread-1] getValue: 1
21:57:40.855 [ Thread-1] result: true
result = 2
result: false 인 부분을 주목해 볼 수 있다. 2번 스레드가 읽은 뒤에 1번 스레드가 compareAndSet을 수행하였기 때문에 2번 스레드가 읽은 값과 실제 값이 달라져서, CAS 연산을 실패시킨 모습이다. 우리가 설계한 로직대로 trigger 된 목적을 어쨌든 수행을 다시 하고 (while 문), 2를 반환한다. (Thread 갯수가 100이면 False 가 여러번 뜨더라도 어쨌든 100을 반환)
위와 같이, CAS 연산을 사용해서 스레드 충돌이 나면, 재시도하는 로직로 설계할 수 있기 때문에, 락을 사용하지 않고 데이터를 안전하게 변경할 수 있다. 또한, 락을 사용하는 것보다 (스레드 상전이, WAITING 등등) 훨씬 높은 성능을 발휘한다. 하지만, 위처럼 "while" 문을 돈다는게 나오면 자연스럽게 CPU 소모율이 높을 수도 있는데? 라는 생각으로 이젠 이어져야 한다.
CAS 연산도 단점이 있는데, 만약 스레드가 충돌이 정말 많은 상황이라면, CAS 연산을 계속 실패하고 while 문을 지속 돌기 때문에 CPU 소모율이 높다 (락과는 다른 점).
| Lock | CAS | |
| 사용 락 방식 | 비관적 락 (스레드가 방해하려 할 것이므로) | 낙관적 락 (충돌이 많진 않을 것 같으므로) |
| 데이터 제어 순서 | 락 획득 후 데이터 제어 | 데이터 바로 접근 |
| 안전성 보장 방법 | 타 스레드 접근 막음 | CPU가 타 스레드 접근 막으며, CAS 활용하는 곳에선 충돌 발생시 재시도 방식 |
| 장점 | CPU 절약, 충돌 관리와 안전성 | 락 없이 동기화 지원, 충돌이 많지 않을시 우수한 성능 |
| 단점 | 대기 시간 및 컨텍스트 스위치 | 충돌이 빈번한 경우 CPU 소모율이 높다 |
| 비유 | 도로를 1차선으로 만들어서 CPU 가 처리하도록 해줌. 앱이 한 명씩 지나가세요~ 하는 느낌 |
앱이 일단 다 지나가~ 하고, 만약 통과 못했으면 다시 뒤로 가서 서! 하는 느낌 (충돌이 많으면 비효율적일 느낌이 확 듬) |
낙관적과 비관적은 이름 그대로 해석해보는게 좋다. 비관적 락은 Worst 를 대비하는 느낌이다. 스레드 충돌이 겁나 많을 것이기 때문에 이를 대비하자는 것으로, Lock 이란 실체를 통해 이를 제어한다. 낙관적 락은 충돌이 많이 없겠지~ 혹시 발생하면 버전 비교(?) 를 통해서 해주면 돼~ (내 해석으로 그냥 품) 라는 느낌이다. 실제로 CAS 연산은 "충돌이 많이 없는 경우"에 락에 비해 훨씬 높은 성능을 보인다.
만약 비즈니스 로직 A 를 수행하는데 1~2초까지나 걸리는데 이를 CAS 연산으로 활용하면, 이를 접근하려는 스레드들은 수백번씩 실패하고 재시도하게될 것이다. 이런 경우에는 락을 활용하는 것이 훨씬 낫다. 하지만, 간단한 CPU 연산은 사실 CPU 입장에서 거의 충돌을 내지 않는다 (1000개 중 50 수준? 그리고 50개는 재시도 해줌). 따라서 간단한 연산일 경우에는 CAS 가 훨씬 우수한 성능을 보일 수 있다.
그럼 CAS 를 활용하여 Lock 을 대체하는 로직을 한 번 살펴보자. 참고로 이런 CAS를 활용한 임계영역 보호는 SpinLock 기법을 활용한다. SpinLock 이란 스레드를 대기시키지 않으면서 락을 만드는 기법이다. (참고로, 이 때 스레드가 대기하는 모습을 CPU 를 소모하며 기다린다 하여 busy-wait, 제자리에서 돌면서 대기한다하여 spin-wait 이라고 부른다)
// * Spin Lock - 스레드를 대기시키지 않으면서 락을 만드는 기법
// 우선 잘못된 SpinLock 먼저
@Slf4j
public class SpinLockBad {
private volatile boolean lock = false;
public void lock() throws InterruptedException {
log.info("락 획득 시도 ");
while (true) {
if (!lock) { // 1 - 공용 자원 LOCK 이 사용중이지 않다면
Thread.sleep(1000); // 스레드 중첩을 위함, 단순 확인용
lock = true; // 2 - LOCK 을 사용중이도록 변경
break;
} else {
// 락을 획득할 때까지 Spin 대기 (스레드 = RUNNABLE 상태로 대기)
// WHILE 문을 계속 돈다
log.info("락 획득 실패 - 스핀 대기");
}
}
log.info("락 획득 완료 - 함수 종료");
}
public void unlock() {
lock = false;
log.info("락 반납 완료");
}
}
---------------------
...
23:33:13.101 [ t1] 락 획득 완료 - 함수 종료
23:33:13.101 [ t2] 락 획득 완료 - 함수 종료
23:33:13.102 [ t1] 비즈니스 로직 실행
23:33:13.103 [ t2] 비즈니스 로직 실행
...
위 모습처럼 lock 을 공유자원으로 선언하고, volatile 로 메모리 가시성 문제를 없애려고 해봤다. 이 로직이 정상적으로 수행이 되지 않는다는건 이제 쉽게 알 수 있다. 위 결과에서 "락 획득 완료" 가 두 번 출력되는 모습은 Lock 이 정상적으로 동작하지 않았다. Lock = false 인 상태에서 스레드 중첩이 발생해 둘다 "락을 얻었다"고 착각하는 상황이 발생했다.
"락 사용 여부 확인", "락의 값 변경" 에 대한 두 부분이 원자적이지 않았으므로 발생한 문제이다. Lock 혹은 sync 를 사용해서 이를 해결할 수 있지만, [a라면 변경하고 아니면 하지 않도록] 이라는 하나의 연산으로 합쳐서 CAS 연산으로 해결할 수도 있다. 우선 스스로 짜보자.
public class MySpinLockTrial {
// private volatile boolean lock = false;
private final AtomicBoolean lock = new AtomicBoolean();
public void lock() throws InterruptedException {
log.info("락 획득 시도");
do {
// 확인해서 없는 상태라면 GET 시도
Thread.sleep(1000); // 확인용
boolean successful = lock.compareAndSet(false, true);
if (successful) {
break;
} else {
log.info("락 획득 실패 - 스핀 대기");
}
} while (true);
log.info("락 획득 완료 - 함수 종료");
}
public void unlock() {
lock.compareAndSet(true, false);
log.info("락 반납 완료");
}
}
우선 강의를 진행하기 전에 MySpinLock 을 만들어보았다. 조금 더 생각을 하고 짰으면 더 깔끔했을텐데, 너무 이전에 했던 구조들을 활용해서 만들려고 한 것 같다. CAS 연산을 활용하긴해서 보장되긴 하지만, 잘못되었다고 할 수 있다. get& get-set 이 여전히 나뉘어져 있다. get-set 보장이 있기 때문에 결과는 맞았지만, 두 연산으로 나뉘어진 느낌이 여전히 있기 때문에, "하나의 연산" 으로 하기 위한 CAS 연산의 목적을 제대로 생각하지 않았다는게 보인다.
public class SpinLock {
private final AtomicBoolean lock = new AtomicBoolean();
public void lock() {
log.info("락 획득 시도 ");
// CAS 연산이 성공할때까지 (실패하면 계속 돈다)
// ㅋ.. 훨씬 깔끔
while (!lock.compareAndSet(false, true)) { // get 을 통한 확인 생략 (이미 포함되어 있다)
// 락을 획득할 때까지 Spin 대기 (스레드 = RUNNABLE 상태로 대기)
log.info("락 획득 실패 - 스핀 대기");
}
log.info("락 획득 완료 - 함수 종료");
}
public void unlock() {
lock.set(false); // lock = false 는 값 대입이므로 (확인 필요 없음) 원자적이다. 따라서 단순 set 활용한다
log.info("락 반납 완료");
}
}
------------------
...
23:46:15.953 [ t2] 락 획득 시도
23:46:15.957 [ t1] 락 획득 완료 - 함수 종료
23:46:15.957 [ t2] 락 획득 실패 - 스핀 대기
23:46:15.958 [ t1] 비즈니스 로직 실행
23:46:15.958 [ t2] 락 획득 실패 - 스핀 대기
23:46:15.958 [ t1] 락 반납 완료
23:46:15.959 [ t2] 락 획득 완료 - 함수 종료
...
대표적인 차이는 unlock 함수의 연산은 이미 원자적인 연산이기 때문에 (기본 값으로 돌리는 것이므로 "true일 경우"를 굳이 확인할 필요가 없음) setter 로 바꿔주는 모습을 볼 수 있다.
하지만 락을 얻는 lock() 함수는 다르다. boolean 이 false 를 확인한 이후로 true 로 변경되기 전까지 false 를 유지해야 하는, 즉 확인/변경 두 연산은 "원자적"일 필요가 있다. CAS 연산으로 이를 원자적 연산인 "락을 사용하지 않는다면 변경"으로 바꾼 것이다. (CAS 연산에는 "확인"과정이 포함되어 있다는 걸 명심)
어쨌든 두 함수 모드 로그를 확인해보면, T1 이 Lock 을 반납한 이후에야 T2가 Lock 획득을 성공해서 비즈니스 로직을 실행하는 모습을 확인할 수 있다. 즉, Intrinsic, Extrinsic Lock 을 직접적으로 사용하지 않고 CAS 연산을 활용하여 안전한 임계 영역을 구현한 모습이다. CAS 연산을 활용해서 무거운 동기화 과정 없이, 아주 가벼운 락을 만들어 준 모습이다 (스레드 상변이, 상변이로 인한 Context Switch, 대기 상태로 대기 등등..).
하지만 CAS 연산은 가벼운 락인 만큼 책임이 있는데, "비즈니스 로직"에 걸리는 시간을 단 1ms 만 추가해도 그 책임을 확인할 수 있다.
...
Runnable runnable = new Runnable() {
public void run() {
spinLock.lock();
try {
// 임계 영역
ThreadUtils.sleep(1);
...
};
...
------------------
...
00:06:43.610 [ t1] 락 획득 실패 - 스핀 대기
00:06:43.611 [ t1] 락 획득 실패 - 스핀 대기
00:06:43.611 [ t1] 락 획득 실패 - 스핀 대기
00:06:43.612 [ t1] 락 획득 실패 - 스핀 대기
00:06:43.612 [ t1] 락 획득 실패 - 스핀 대기
00:06:43.612 [ t1] 락 획득 실패 - 스핀 대기
00:06:43.612 [ t1] 락 획득 실패 - 스핀 대기
00:06:43.613 [ t2] 비즈니스 로직 실행
개념상 "오래걸리는 비즈니스 로직"을 수행할 때 SpinLock 을 활용하면 "while 문이 엄청 많이 도는" 모습을 확인할 수 있다. 즉, 상황에 따라서 정말 맞는 기술을 사용해야 하는 것이 중요하단 것을 알 수 있다. "락 획득 가능 여부를 계~속 체크" 해도 이게 더 효율적으로 판단 될 경우에 활용하는게 좋다. 스레드 상변이가 없고 대기도 없기 때문에 락 획득 및 반납하는 과정 자체는 비교가 안될 정도로 빠르기 때문이다 (true/false 변경).
4. CAS 연산 쓰라는거야 말라는거야?
그냥 "안전한 임계 영역이 필요한데, 영역 내의 로직이 매우매우매우 짧게 끝날 경우" 활용하는 것이 좋다고 요약할 수 있다 (숫자 값 증가, 자료구조 데이터 추가/변경/삭제 등). DB 대기, 타 요청 수행, 꽤 많은 비즈니스 로직 수행 등의 경우에는 최악의 결과를 낳을 수 있다. 따라서 생각해봤을 때 대부분의 경우는 Lock 을 직접적으로 사용하는게 더 맞다. 하지만 실제로 위 예시처럼 연산 로직이 누가봐도 매우매우 짧을 것으로 보일 때는 실무에서도, 많은 라이브러리에서도 CAS 기법을 활용한다. 그 이유를 살펴보자.
피크 시간에 주문이 1시간에 100만건 들어온다고 해보자. 이 정도면 우리나라 손가락 안에 드는 탑 티어 서비스라고 한다. 이를 역으로 추적하면 1초에 대략 277건 정도 된다. 요즘 성능 좋은 CPU들은 1초에 수십억까지 계산을 할 수 있다. 따라서 충돌이 나는 경우는 요청수 대비 극히 적을 것이기 때문에, 그 정도는 CPU를 소모하면서 루프를 돌리는 것이 성능에 더 효과적이라고 보는 것이다. 이는 단순한 연산이기 때문이다. 여전히 DB대기 혹은 타 서버 요청 등은 락이 훨씬 효과적이다.
이제 살펴볼 동기화 컬렉션 라이브러리들에서는 CAS 연산을 굉장히 적극적으로 활용한다. 따라서 라이브러리들을 활용하기 우리가 직접 CAS 연산을 사용해서 제어할 일은 드물긴 하다. 다만, 이 라이브러리들이 어떻게 최적화되어 있는지 이해하는 것은 중요하다. CAS가 뭔지 아는 것과 모르는 것은 라이브러리를 분석할 때 큰 차이를 보여준다.
동시성 컬렉션
1. 필요한 이유
List<Object> list = new ArrayList<>();
list.add("A");
list.add("B");
System.out.println(list);
위에서 List를 서로 다른 두 스레드가 add 한다고 해보자. 자료구조에 단순 추가하는 것은 마치 원자적인 연산처럼 느껴져서 멀티스레드 상황에서 문제가 안될 것처럼 느껴진다 (계속 말하지만, 스레드의 위험성은 원자적 연산이라 하는게 정확한 답변이다. 원자적인 연산은 쪼개지지 않아서 Thread Safe 하다). 하지만 단순 컬렉션 프레임워크가 제공하는 대부분의 연산은 원자적이지 않다고 한다. 배열을 사용해서 기초적인 List 를 만들어 보자.
// 일반적인 자료구조를 구현해보자
// - 왜 일반 Collection 계열이 Thread Safe 하지 않은지 먼저 보자
public class BasicList implements SimpleList{
private static final int DEFAULT_CAPACITY = 5;
private Object[] elementData;
private int size = 0;
...
// 절대 원자적일 수 없다
@Override
public void add(Object obj) {
elementData[size] = obj;
sleep(100); // 멀티 스레드 문제 쉽게 확인 가능
this.size++; // 이미 연산이 나뉘고, Object 배열은 동시이다
}
...
}
add 함수를 작성할 때부터 이미 연산이 쪼개져 있다. 더욱이 size++ 하나만으로도 원자적 연산 아니다. 멀티스레드로 돌려보면, 딱봐도 처음 넣은게 drop 될 것임이 보인다. 이렇게 원자적이지 않은 연산이 공유 자원에 사용된다 = 무조건 Thread Safe 하지 않다. 다음과 같이 돌려보자.
private static void test(SimpleList list) throws InterruptedException {
log(list.getClass().getSimpleName());
// A 를 리스트에 저장하는 스레드
Runnable aTh = new Runnable() {
@Override
public void run() {
list.add("A");
log("Thread-1 : adds A");
}
};
// 동일하게 B를 저장하는 Thread-2
...
Thread th1 = new Thread(aTh, "Thread-1");
Thread th2 = new Thread(bTh, "Thread-2");
th1.start();
th2.start();
th1.join();
th2.join();
log("결과:: " + list);
}
-------------------
01:26:06.029 [ Thread-1] Thread-1 : adds A
01:26:06.029 [ Thread-2] Thread-2 : adds B
01:26:06.042 [ main] 결과:: [B, null] size= 2, capacity= 5
우선 elementData[size]=obj 란 줄을 수행할 때 Th1, Th2 가 모두 실행될때 size=0 이므로 먼저 넣은 데이터가 삭제된다. 또한 Th1과 Th2가 size++ 를 실행할 때, Th1이 약간 먼저 대기를 깨고 나와서 0임을 읽고 1로 증가시킨 뒤, Th2 가 1로 읽게 된다면 위와 같은 결과가 나온다. 만약 동시에 0으로 읽었으면 size=1 로 나온다.
이렇게 우리가 엄청 쓰는 LinkedList, ArrayList, HashMap 등의 자료구조들의 내부는 원자적 연산이 아니며, 공유 자원으로 사용시 절대 Thread Safe 하지 않고, 여러 스레드들이 사용하면 이처럼 고장난다. 따라서 잘 동기화를 해주거나, 최적화가 이미 잘 되어있는 동시성 컬렉션을 사용해야 한다. 만약 위 add 함수에 synchronzied 하나만 있다면 해결되긴 한다.
복습해보면, Sync 함수가 적용된다면 List 의 add 함수를 수행하기 위해 I-Lock 을 가져가려 하지만, 누가 add 함수를 수행중이라면 BLOCKED 로 전환되어 대기한다 (I-Lock 에 대한 BLOCKED 대기소). 그리고 만약 락을 반납하면 BLOCKED 에 있는 녀석 중 하나가 선택되어 RUNNABLE 전환, CPU 실행시 락을 획득하게 된다. 이렇게 Th1, 2 가 안전하게 등록할 수 있다.
그러면 모든 컬렉션들 (ArrayList, LinkedList 등등) 함수에 synchronized 를 붙여서 새로운 객체들을 다시 만든게 concurrent 패키지일까? 당연히 그렇게 무식하게 구현되지 않았다. 동시성 컬렉션이 만들어지기 위해 사용된 Proxy 기술을 살펴보자.
2. 프록시 기술이 사용된 동시성 컬렉션
기존에 제공되는 클래스의 기능을 그대로 사용하면서, synchronized 처럼 간단한 기능만 살짝 제어하고 싶을 때 프록시를 사용할 수 있다. 프록시란 요청을 대신 처리해서 요청자와 응답자를 서로 모르게 하는 기술이다 (패턴?). 즉, sync 처리 되어 있는 프록시 클랙스에게 그 내부에서 기존 클래스의 역할을 수행하는 것을 요청할 수 있다.
// SimpleList 를 받아서 하는 일에 Sync 처리만 지원해주는 클래스
public class SyncProxyList implements SimpleList {
private SimpleList target;
public SyncProxyList(SimpleList target) {
this.target = target;
}
@Override
public synchronized int size() {
return this.target.size();
}
@Override
public synchronized void add(Object obj) {
this.target.add(obj);
}
@Override
public synchronized Object get(int index) {
return target.get(index);
}
@Override
public String toString() {
return target.toString() + " + by " + this.getClass().getSimpleName();
}
}
기존 SimpleList 의 역할체를 그대로 수행해주지만, synchronized 만 걸어주는 역할을 수행하기 위해 만들어진 클래스이다. 정말 syncrhonized 추가의 역할만 추가되는 것을 알 수 있다.
// Proxy 를 사용
public static void main(String[] args) throws InterruptedException {
// test(new BasicList());
// test(new SyncList());
BasicList bl = new BasicList();
SyncProxyList proxyList = new SyncProxyList(bl);
test(proxyList);
}
------------
17:57:25.231 [ main] 결과:: [A, B] size= 2, capacity= 5 + by SyncProxyList
BasicList 의 add 를 호출하거나, size 를 호출하거나 SyncProxyList 는 우선 Sync 함수를 걸고 실행을 대행해준다. 따라서, 결과가 안정적으로 수행됨을 알 수 있다. 기존에 BasicList 를 활발하게 사용하고 있었다면, 위와 같이 프록시 객체를 활용해서 기능을 확장시켜줄 수 있다. 객체를 넘겨줘서 타 객체를 수행시키는 이 관계는 굳이 길게 설명하진 않겠다.
위에서 살펴본 패턴은 "기존 코드에 전혀 손을 대지 않고, 기능을 추가를 하는" 경우에 많이 사용되는 프록시 패턴이다. 이 상황에서 사용되는 "프록시 객체"는 실제 객체에 대한 참조를 유지하며, 그 객체에 접근하거나 행동을 수행하기 전에 추가적인 처리를 할 수 있다. 주요 목적은 접근 제어, 성능 향상 (실제 객체의 생성을 지연 - JPA 지연 로딩에서 사용되는 것도 프록시 or 캐싱), 부가 기능 제공이 있다. 자바에서는 이를 어떻게 활용했는지 살펴보자.
3. 자바 동시성 컬렉션
java.util 패키지에 있는 컬렉션 프레임워크들은 내부적으로 수많은 연산 (추가, 사이즈 변경, 노드 연결 등등..) 이 함께 동작한다. 따라서 Thread-Safe 하지 않고, sync 함수를 활용하지 않은 이유는 역시 성능 때문이다 (꼭 멀티 스레드 상황을 위해 사용되지 않는 경우도 매우 많음).
참고로 Java 가 util 패키지에서 제공하는 Vector 클래스는, ArrayList 에 sync 함수가 걸려있는 클래스이다. 불필요한 동기화로 인해 사용되지 않는 컬렉션의 대표적인 예시이다
위에서 배운 것처럼 필요할 때 sync 를 적용해 주는 프록시를 만들어서 사용하면 된다. 이게 자바 객체지향의 강력함이고, 다형성의 강력함이다.
public static void main(String[] args) {
List<String> list = Collections.synchronizedList(new ArrayList<>()); // 동기화가 적용된 컬렉션으로 변환
list.add("data1");
list.add("data2");
list.add("data3");
System.out.println(list.getClass());
System.out.println("list = " + list);
}
위와 같이 ArrayList 를 선언하면, Thread-Safe 한 Array List 로 활용할 수 있는, SynchronizedRandomArrayList 객체로 변환되어서 사용된다. 이 객체는 ArrayList 에 synchronzied 액션을 추가하는 프록시 객체이다. 실제로 내부 함수로 들어가보면 함수에 synchronized 가 걸린채로 list.add, remove, indxeOf 등의 함수를 그대로 수행하고 있다.
이처럼 synchronizedList(), ~Collection(), ~Map(), ~Set() 등 Collections 가 제공하는 프록시 기능으로 Thread-Safe 가 필요한 경우 안전한 컬렉션으로 변경해서 사용할 수 있다. 그렇다면 이 방식을 정말 사용할까? 사실 이 방법은 사용하지 않기 때문에, 단점이 왜 발생하는지 이해하는게 더 중요하다.
- 안전하긴 하지만 정말 많은 Sync 함수로 인해 동기화 비용이 크다. 성능 저하 유발
- list.add 함수 내부를 제어하며 동시성 제어를 최적화 할 수 없다 → 프록시를 사용하는 단점
Collections 가 사용하는 프록시 패턴 방법은 다소 무식하게 사용하는 방법이라, 성능 이슈가 크게 걱정되진 않지만 이론상 Thread-Safe 가 필요하긴 할 때 사용할 수 있다. 근데 예전에 등장했던 concurrent 패키지에 더 좋은 객체들이 있어서 사용하지 않긴 한다. 이는 프록시 패턴은 사용하지 않고, 그냥 내부적으로 동기화를 최적화한 새로운 Thread-Safe 한 자료구조 객체들을 적용하는 것이다.
3. 자바 동시성 컬렉션
위에서 말한 컬렉션들은 정교한 잠금 메커니즘을 사용하여(I & E Lock, CAS, Segment Lock 등) 필요한 경우에만 동기화를 적용하여 최적화된 동기화 전략을 제공한다 - ConcurrentHashMap, CopyOnWriteArrayList, BlockingQueue 등이 대표적이다. 내부 최적화는 매우 어렵기 때문에, 필요한 상황에 대한 인지 & 컬렉션 활용을 할 수 있으면 된다.
ArrayList → CopyOnWriteArrayList
HashSet → CopyOnWriteHashSet
HashMap → ConcurrentHashMap (많이 씀)
Queue → ConcurrentLinkedQueue (CAS 기반, 스레드 차단하지 않음)
BlockingQueue → ArrayBlockingQueue 등등.. (Lock 활용하여 스레드 Block)
...
공부하는게 아닌 실무에서는 성능이 가장 중요하기 때문에, 웬만하면 제공된 concurrent 패키지 자료구조를 필요에 맞게 활용하는 것을 권장한다. 참고로 멀티스레드 상황에서 일반 컬렉션을 사용하면 정말 해결하기 어려운 버그가 발생할 수 있다 (가장 해결하기 어려운 버그가 멀티 스레드 버그, 디버깅 모드도 어렵).

출처
[실전 Java 고급 1편]으로 엮인 모든 포스트들은 교육 사이트 인프런의 지식공유자이신 김영한님의 [김영한의 실전 자바 - 고급 1편, 멀티스레드와 동시성] 강의를 기반으로 작성되었습니다. 열심히 정리하고 스스로 공부하기 위해 만든 포스트이지만, 제대로 공부하고 싶으시면 해당 강의를 꼭 들으시는 것을 추천드립니다.
김영한의 실전 자바 - 고급 1편, 멀티스레드와 동시성 강의 | 김영한 - 인프런
김영한 | 멀티스레드와 동시성을 기초부터 실무 레벨까지 깊이있게 학습합니다., 국내 개발 분야 누적 수강생 1위, 제대로 만든 김영한의 실전 자바[사진][임베딩 영상]단순히 자바 문법을 안다?
www.inflearn.com
'Java' 카테고리의 다른 글
| [실전 Java 고급 1편] - 6. Executor Framework 에 대하여 2 (0) | 2025.05.04 |
|---|---|
| [실전 Java 고급 1편] - 5. Executor Framework 에 대하여 (0) | 2025.04.27 |
| [실전 Java 고급 1편] - 3. 생산자 소비자 문제 (BlockingQueue 만들기까지) (0) | 2025.01.31 |
| [실전 Java 고급 1편] - 2. 메모리 가시성과 동기화 (0) | 2025.01.31 |
| [실전 Java 고급 1편] - 1. Thread 의 제어 (0) | 2025.01.31 |