Thread Pool 과 Executor Framework 2
1. 우아한 종료
우아한 종료 (graceful shutdown) 자체는 SW에서 매우 중요한 개념이다. "기존에 진행중이던 작업을 완료한 이후 문제 없이 안정적으로 SW를 종료"하는 것을 말한다. 가령, 서버가 재기동되어야 할 때, 현재 처리중이던 요청이 있다면 마무리하고 종료해야 하는 것을 말한다.
- void shoutdown()
- 새로운 작업을 받지 않고, 제출된 작업을 모두 완료한 후 종료한다. Non-Blocking 함수
- 우리가 사용하던 close() 와 동일하다고 보면 된다. (24시간 뒤에 안되면 shutdownNow() 호출)
- List<Runnable> shutdownNow()
- 긴급 중단. 실행 중인 작업들을 중단하고 대기중인 작업들은 반환된다. Non-Blocking 함수
- 인터럽트를 통해 작업들을 중단하기 때문에, 실행중인 작업들은 인터럽트 지원이 되어야 한다 (상황을 인지하고 있어야 함)
- boolean awaitTermination(time, timeunit)
- 위 두 함수는 Non-Blocking 이기 때문에, 요청 스레드는 대기하지 않는다
- 따라서, 위 두가지 종료 함수 호출 이후 정상적으로 동작하고, 호출 없이하면 즉시 false 를 반환하게 된다.
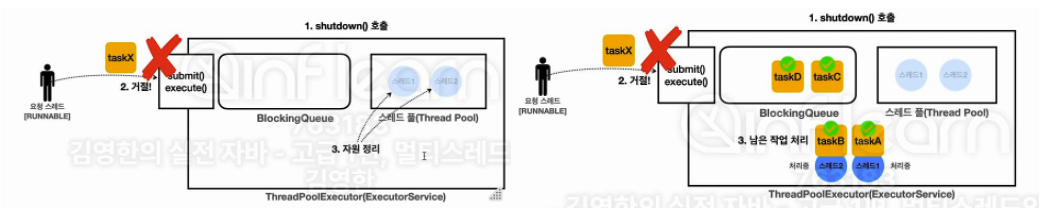
shutdown() 함수가 호출되면 더 이상의 요청은 받을 수 없으며, ES 는 자원을 정리하고 반납하게 된다. 이 때, 거절에 대한 정책도 줄 수 있긴 하지만 기본적으로 RejectedExecutionException 이 발생한다. 이 때 만약 우측처럼 실행중이던 작업이 있다면 해당 작업들을 모두 종료하고, 심지어 Queue 에 남은 작업들이 있다면 해당 작업들까지 모두 완료 후 정리를 시작한다 (이미 한 번 들어온건 끝을 봄)
반면에 shutdownNow() 함수는 큐에 들어있는 작업들은 List<Runnable> 형태로 전달해준다 (ES가 종료되므로 Callable 을 쓸 수 없기 때문에 Runnable 로 반환해주는 디테일..). 실행중인 작업들은 interrupt 를 발생시켜서 중단시키게 된다.
하지만 shutdown 이후에도 큐에 너무 많은 작업이 남아있거나, 작업이 너무 오래걸리거나, 버그가 발생한 상황이라서 종료가 너무 오래걸릴 수도 있다. 종료가 필요한 시점에 예상보다 너무 늦어지거나, 종료되지 않는 문제 또한 버그이므로, 우아한 종료 시간을 지정하는게 일반적이다. close 는 24시간을 대기해주기 때문에 너무 길어서, 이 요구사항에 대한 해결과 함께 close 를 사용해보자.
// 공식 메뉴얼의 방식이기도 하다 (약간 편하게)
private static void shutdownAndAwaitTermination(ExecutorService es) {
// 정상종료 먼저 수행
es.shutdown(); // non-blocking, 새로운 작업을 받지 않고 나머지는 종료를 대기해보자 -> 작업 내부에서 Thread.sleep 이 있으므로 인터럽트가 발생한다
try {
boolean isFinished = es.awaitTermination(10, TimeUnit.SECONDS); // 10초간 요청스레드를 대기시켜본다. 결과적으로 종료되었는지? 를 확인.
if (!isFinished) { // 문제가 발생함 -> 정상 종료가 너무 오래걸린다
log("서비스 정상 종료 실패 :: 강제 종료 진행");
es.shutdownNow();
// 이후 작업 취소까지도 시간이 필요
if (!es.awaitTermination(10, TimeUnit.SECONDS)) {
log("shutdown 시도 종료 :: ES는 현재 종료되지 않았습니다");
// 이 때도 특정 시간동안 안되면 정말 뭔가 이상한 것. 자바 재기동 해야한다
}
}
} catch (InterruptedException e) { // 여긴 뭐 요구사항에 맞게 구현하기 나름
// 대기중인 요청 스레드가 인터럽트 걸릴 수도 있다
es.shutdownNow();
throw new RuntimeException(e);
}
}
Main 함수에서는 10초걸리는 작업 3개와 100초가 걸리는 작업을 전달한다. 작업 4가지를 맡겨놓은 뒤 바로 shutdownAndAwaitTermination 함수를 수행하면, 전달된 작업들은 빠르게 완료시키겠지만, 100초 작업은 완료하지 못한다. 위 코드에서 설계된대로, 10초가 지나도 정상적으로 종료되지 않는다면, shutDownNow 함수를 수행한다. 이 때, 작업 스레드가 만약 interrupt 가 구현되어 있지 않으면 shutdownNow 에도 동작하지 않는다.
서비스가 종료된다면 우아한 종료가 기본적인 방안이며, 우아한 종료에 대해서 대기 시간을 잘 제어해보는 것까지가 정석적인 처리 방안이라 할 수 있다. 자바 앱 뿐만 아니라 어떤 서비스든지 우아한 종료에 대해 알고 있도록 하자.
2. ExecutorService 의 ThreadPool 관리
ExecutorService 의 생성자로 전달될 때는 corePoolSize, maxPooliSize, keepAlive, BlockingQueue 가 전달되는 것을 이미 확인햇다. 각 PoolSize 가 어떤 것인지 좀 더 알아보자. core, max 가 각각 2, 4 인 ES를 만들어보자.
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(2);
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4
, 3000, TimeUnit.MILLISECONDS, workQueue);
printState(executor);
executor.execute(new RunnableTask("TASK1"));
printState(executor, "TASK1");
executor.execute(new RunnableTask("TASK2"));
printState(executor, "TASK2");
--------------
00:59:14.739 [ main] [pool= 0, active= 0, queuedTask= 0, completedTask= 0]
00:59:14.745 [pool-1-thread-1] TASK1 시작!
00:59:14.755 [ main] TASK1 -> [pool= 1, active= 1, queuedTask= 0, completedTask= 0]
00:59:14.755 [ main] TASK2 -> [pool= 2, active= 2, queuedTask= 0, completedTask= 0]
00:59:14.755 [pool-1-thread-2] TASK2 시작!
00:59:15.747 [pool-1-thread-1] TASK1 완료!
00:59:15.761 [pool-1-thread-2] TASK2 완료!

Task 를 두 개 넣으면 그냥 순서대로 잘 동작한다. 이 때 세 개를 넣어보자. max 가 4 개인 ExecutorService 니까 아마 하나를 늘려서 active 3 까지 만들지 않을까 싶다.
...
executor.execute(new RunnableTask("TASK3"));
printState(executor, "TASK3");
...
---------------
01:01:27.169 [ main] [pool= 0, active= 0, queuedTask= 0, completedTask= 0]
01:01:27.178 [pool-1-thread-1] TASK1 시작!
01:01:27.188 [ main] TASK1 -> [pool= 1, active= 1, queuedTask= 0, completedTask= 0]
01:01:27.189 [ main] TASK2 -> [pool= 2, active= 2, queuedTask= 0, completedTask= 0]
01:01:27.189 [pool-1-thread-2] TASK2 시작!
01:01:27.189 [ main] TASK3 -> [pool= 2, active= 2, queuedTask= 1, completedTask= 0]
01:01:28.184 [pool-1-thread-1] TASK1 완료!
01:01:28.185 [pool-1-thread-1] TASK3 시작!
01:01:28.191 [pool-1-thread-2] TASK2 완료!
01:01:29.189 [pool-1-thread-1] TASK3 완료!

하지만 예상과는 반대로 pool 내 Thread 와 active task 를 늘리지 않고, queing 시켜놨다가 TASK1 이 완료되어서 소비자가 생기면 그 때 Task3 를 할당하는 모습을 확인할 수 있다. BlockingQueue 의 사이즈는 2개로 생성해둔 걸 기억하자. 이 때 두개의 TASK 를 더 넣어보자.
...
executor.execute(new RunnableTask("TASK4"));
printState(executor, "TASK4");
executor.execute(new RunnableTask("TASK5"));
printState(executor, "TASK5");
...
-------------------
01:05:59.571 [ main] [pool= 0, active= 0, queuedTask= 0, completedTask= 0]
01:05:59.578 [pool-1-thread-1] TASK1 시작!
01:05:59.588 [ main] TASK1 -> [pool= 1, active= 1, queuedTask= 0, completedTask= 0]
01:05:59.589 [ main] TASK2 -> [pool= 2, active= 2, queuedTask= 0, completedTask= 0]
01:05:59.589 [pool-1-thread-2] TASK2 시작!
01:05:59.589 [ main] TASK3 -> [pool= 2, active= 2, queuedTask= 1, completedTask= 0]
01:05:59.590 [ main] TASK4 -> [pool= 2, active= 2, queuedTask= 2, completedTask= 0]
01:05:59.590 [ main] TASK5 -> [pool= 3, active= 3, queuedTask= 2, completedTask= 0]
01:05:59.590 [pool-1-thread-3] TASK5 시작!
01:06:00.585 [pool-1-thread-1] TASK1 완료!
01:06:00.585 [pool-1-thread-1] TASK3 시작!
...
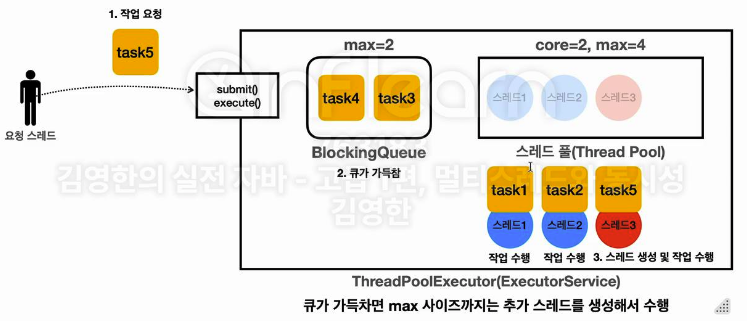
TASK4 가 들어오고 다음 TASK5 가 들어와서 BlockingQueue 가 다 차니까, 그제서야 pool size 와 active 갯수를 늘려 더 많은 Thread 를 돌리기 시작한다. BlockingQueue 가 다 찬 상황은 긴급 상황으로, 대기 작업이 꽉 찰 정도로 요청이 많다는 뜻이기 때문에, pool size 를 늘리는 것이다. 그리고 가장 먼저 대기한 Task3 을 주는게 아니라 초과된 순간 들어온 큐에 못 넣으니 들어온 Task5 부터 실행하는 모습도 확인할 수 있다. Queue 까지 다 차서 더이상 방법이 없을 때, 그제서야 PoolSize 를 늘리고, 더 넣으면 Thread 수 네 개 까지는 늘려줄 것이다. 만약 이 상황에서 하나 더 넣으면 어떻게 될까?
...
executor.execute(new RunnableTask("TASK6"));
printState(executor, "TASK6");
executor.execute(new RunnableTask("TASK7"));
printState(executor, "TASK7");
...
--------------------
...
01:17:15.037 [ main] TASK6 -> [pool= 4, active= 4, queuedTask= 2, completedTask= 0]
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task thread.sec11_executor_1.RunnableTask@3c0ecd4b rejected from java.util.concurrent.ThreadPoolExecutor@6108b2d7[Running, pool size = 4, active threads = 4, queued tasks = 2, completed tasks = 0]
...

TASK6이 들어오면 Thread Pool 도 max 까지 가득 차고, queue 도 이미 가득 찬 상태이다. 따라서 RejectedExecution Exception 이 발생해서 해당 Task7 은 할당되지 못하게 된다. 나중에 넣고 뭘 처리해주는게 아니라, 그냥 거절한 상태로 ES 는 이를 무시하는 것이다.
...
Thread.sleep(3000);
log("====== 작업 수행 완료 ======");
printState(executor);
...
-------------------
...
01:22:43.034 [ main] ====== 작업 수행 완료 ======
01:22:43.035 [ main] [pool= 4, active= 0, queuedTask= 0, completedTask= 6]
ExecutorService 는 한번 생성한 스레드를 굳이 종료시키진 않기 때문에, Thread Pool 에 4개의 스레드를 재사용하며 이를 유지하고 있다. 하지만 처음에 생성자에서 keepAlive 시간을 제시한 것을 기억하자. 그리고 3초를 더 기다려보자.
...
Thread.sleep(3000);
log("====== 초과되어 생성된 maxPool 들의 대기 시간 초과 ======");
printState(executor);
...
--------------------
...
01:30:07.572 [ main] ====== 초과되어 생성된 maxPool 들의 대기 시간 초과 ======
01:30:07.573 [ main] [pool= 2, active= 0, queuedTask= 0, completedTask= 6]
...
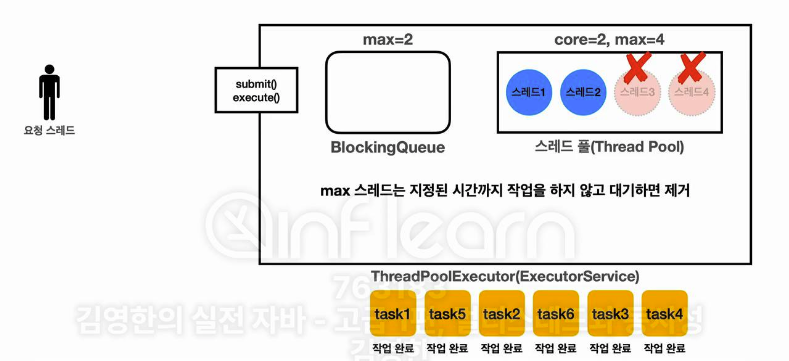
초과된 Pool 들은 제한된 keepAlive 시간을 초과하면 정리된다. 그리고 ExecutorService 의 ThreadPool 은 corePool 수를 유지하려고 한다. 즉, maximum 까지 늘리는건 Queue 가 가득찬 [긴급상황] 일 경우 늘리는 것으로 생각하면 된다. "긴급상황이 좀 진정됐나? " 하는 시간을 가지고, 진정되었다고 판단하면 종료하는 것이다. 정말 섬세한 처리라고 생각이 든다..
참고로 ExecutorService 는 기본적으로 요청이 오면 그제서야 스레드를 생성하기 시작하는데, 빠른 처리를 위해 먼저 만들어 놓을 수도 있다. init 시 ThreadPooling 을 해놓는 것이다.
ExecutorService es = Executors.newFixedThreadPool(1000);
ThreadPoolExecutor poolExecutor = (ThreadPoolExecutor) es;
poolExecutor.prestartAllCoreThreads(); // 작업이 할당되기 전에 미리 스레드를 준비해놔라
아무튼 이렇게 prestart, coreSize, maxSize, keepAlive, queueSize 등 설정이 정말 많고, 이들을 어떻게 조합하냐에 따라서 Pooling 전략이 달라진다. 내가 쓰고싶은 상황에 적합한 풀링 전략을 어떻게 가져갈 수 있을지, 대표적인 전략들에 대해서 살펴보며 이를 더 이해해보자.
3. ExecutorService 사용 전략 - 고정 풀 전략: newFixedThreadPool(nThreads)
// Executors.newFixedThreadPool(n); 이것과 동일
new ThreadPoolExecutor(n, n, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
고정 스레드 풀을 기본적으로 "초과 스레드 정책"을 가져가지 않고, 기본 스레드 갯수 n 개 만큼을 가져가고 활용하는 ExecutorService 를 만드는 것이다. 하지만, BlockingQueue 를 Linked 로 사용해서, 큐 사이즈에 제한이 없다 (그래서 초과 스레드를 관리하지 않는 것). 이 방식의 최고 장점은 스레드 수가 고정되어 있어서 CPU 및 메모리 같은 리소스 사용량을 어느정도 예측할 수 있는 안정적인 방식이다.
그냥 기본적으로 2개만 지속 사용하고, 작업들은 큐에 계속 쌓아가며 대기시키는 방식이다. 기다리든 말든 그냥 신경 안쓰고 일 오면 하는 두 명의 일꾼을 두는 방식이다. 하지만 너무 많은 작업 요청이 오는 서버는 큐가 매우 커질 수 있기 때문에, 조금 위험할 수도 있다는 생각도 든다. 그리고 단점은 역시 사용자 확대 및 갑작스런 요청 Burst 에 있다.
newFixedThreadPool 을 사용하면 요청자가 갑자기 많아진다 해도 고정 스레드를 두기 때문에 CPU, 메모리 사용량이 확 늘어나진 않는다. 하지만 이 방식은 큐가 무한이기 때문에, 사람들을 모두 대기시키고, 두 스레드만이 세월아 네월아 하며 작업하고 있는 것이다. 서비스 초반에 서버 모니터링을 위해선 좋을 수 있지만, Burst 가 존재하면 시간이 굉장히 오래걸릴 수 있다. CPU 와 메모리는 지금 힘들지 않은데, 작업자가 두 개 뿐이니 여유가 있음에도 사용자만 느려질 수 있는 큰 단점이 존재하는 것이다. 따라서 FixedThreadPool 을 사용할 때는 모니터링을 위한 로그를 가져가는 것도 매우 중요할 것 같다.
4. ExecutorService 사용 전략 - 캐시 풀 전략: newCachedThreadPool()
// Executors.newCachedThreadPool()
new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
캐시 풀에서 생성하는 스레드들은 재사용하는게 하나도 없고, 생존 주기만을 가진 초과 스레드만을 가지는 스레드 풀을 말한다. 단, 초과 스레드의 수는 제한이 없다. SynchronousQueue 를 사용해서 작업을 큐에 넣어두지 않고, 소비자 스레드가 생성되어 바로바로 처리하는 화끈한 전략이다. 초과 스레드가 무제한으로 생성되므로 모든 작업이 큐에 들어가서 대기할 필요 없이 바로바로 처리된다.
SynchronousQueue 는 직거래하는 공간이다. 버퍼의 사이즈가 0이라 저장시키지 않고, 생산자가 작업을 주면 소비자가 해당 큐에서 작업을 꺼내갈때까지 들고 있는데, 큐에 넣지 않는 것 뿐이다 (살짝 헷갈렸는데, S-Q는 저장소가 없다고 한다. 생산자 스레드가 작업을 들고 왔을 때 소비자가 없으면 "직접 대기" 하는 느낌인 것 같다 (일반 B-Q는 생산자가 작업을 놓고 사라짐)).
스레드도 기본이 0이니까 '남는 스레드 없음 인식'으로 바로 긴급상황 1번이고, 큐도 작업을 저장할 수 없으므로 '저장공간이 없다고 인식'해서 바로 긴급상황 2번을 인지하여, 초과 스레드를 바로 생성하기 시작한다. 코드로 살펴보자.
public static void main(String[] args) throws InterruptedException {
// ExecutorService es = Executors.newCachedThreadPool(); - keepAliveTime 제어를 위해
ExecutorService es = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 3, TimeUnit.SECONDS, new SynchronousQueue<>());
log("pool 생성");
printState(es);
for (int i = 0; i < 4; i++) {
String taskName = "task" + i;
es.execute(new RunnableTask(taskName));
printState(es, taskName);
}
Thread.sleep(3000);
log("작업 수행 완료");
printState(es);
es.close();
log("종료");
}
---------------------------
13:15:38.236 [ main] [pool= 0, active= 0, queuedTask= 0, completedTask= 0]
13:15:38.241 [pool-1-thread-1] task0 시작!
13:15:38.255 [ main] task0 -> [pool= 1, active= 1, queuedTask= 0, completedTask= 0]
13:15:38.256 [ main] task1 -> [pool= 2, active= 2, queuedTask= 0, completedTask= 0]
13:15:38.256 [pool-1-thread-2] task1 시작!
13:15:38.256 [ main] task2 -> [pool= 3, active= 3, queuedTask= 0, completedTask= 0]
13:15:38.256 [pool-1-thread-3] task2 시작!
13:15:38.257 [pool-1-thread-4] task3 시작!
13:15:38.257 [ main] task3 -> [pool= 4, active= 4, queuedTask= 0, completedTask= 0]
...
13:15:41.261 [ main] 작업 수행 완료
13:15:41.262 [ main] [pool= 4, active= 0, queuedTask= 0, completedTask= 4]
13:15:41.264 [ main] 종료
Task 가 전달되는 만큼 [긴급 상황]으로 인지한 ExecutorService 는 무한정 스레드를 만들어내고, 기본 1분동안 keepAlive 를 유지하다가 더 일이 없으면 다시 active 한 스레드를 0으로 유지한다. 캐시 풀 전략은 매우 빠르고 유연한 전략이다. 작업 요청이 오면 초과 스레드를 만들어 바로바로 작업을 처리하기 때문이다. CPU, 메모리만 여유롭다면 상황이 요청하는만큼 스레드를 만들어서 처리할 수 있다.
캐시 풀 전략은 또한 무조건 스레드를 만드는 것이 아니다. KeepAlive 시간이 60초이기 때문에, 작업이 끝난 초과 스레드가 있다면 어느정도 재사용성 또한 가져가는 전략이다. 현 요청 상황에 맞게 작업중이거나 관리중인 스레드가 증가/감소 하므로 매우 유연한 전략이다. 하지만 항상 단점도 존재하는 법이다.
사용자가 일시적으로 폭등했다고 생각해보자 (이벤트 따위의 처리). 시스템이 매우 느려져 모니터링을 해보니, CPU 사용량이 100% 이며 메모리도 매우 높았다. 스레드 수를 확인해보니 스레드 수가 수 천개가 실행중일 수 있는 것이다 (재사용 전에 요청이 지속 누적). 캐시 풀 전략은 스레드를 무한으로 생성할 수 있기 때문에, 너무 많은 스레드로 시스템이 잠식되어 시스템 다운이 발생할 위험이 큰 전략이다. 따라서 고정 풀과 완전 정반대인 느낌이다. 고정 풀은 "사용자한테 기다리라해!" 하는 느낌이라면, 캐시 풀은 "서버 상황은 모르겠고 무조건 빨리 해!!" 하는 느낌이다. 중간은 없는가..?
5. ExecutorService 사용 전략 - 사용자 정의 풀 전략
사실 저런 전략에 의존하지 않고, ExecutorService 가 사용하라고 만들어진대로 사용하면, 어느정도 대응을 할 수 있다. 서버의 대표적인 상황을 다음과 같이 나누어 보자.
- 일반 - CPU, 메모리 자원 모니터링이 쉽도록 고정 크기의 스레드로 서비스를 안정적으로 운영
- 긴급 - 요청이 매우 많아져, 추가 스레드가 필요한 상황
- 거절 - 긴급 대응이 어렵다면 사용자의 요청을 거절 (아예 다운되는 것보단 훨씬 나은 것)
위 세가지 상황 모두 ExecutorService 스레드 풀의 동작 원리를 이해해보면서 나왔던 상황들이다. 가령, 좀 더 실전적인 풀 전략을 다음과 같이 가져가 볼 수 있다.
ExecutorService es = new ThreadPoolExecutor(100, 200, 60, SECONDS
, new ArrayBlockingQueue<>(1000));
LinkedBlockingQueue 를 사용하지 않고 1000개의 공간만을 할당한다. 1000개를 넘어가면 100개 까지의 초과 스레드를 생하고, 그래도 안되면 거절하는 상황으로 가져갈 수 있다. 위에서 한 실습이긴 하지만, 다음과 같은 상황으로 테스트해보자.
static final int TASK_SIZE = 1100; // 일반
// static final int TASK_SIZE = 1200; // 긴급
// static final int TASK_SIZE = 1201; // 거절
public static void main(String[] args) throws InterruptedException {
ExecutorService es = new ThreadPoolExecutor(100, 200
, 60, SECONDS, new ArrayBlockingQueue<>(1000));
printState(es);
long start = System.currentTimeMillis();
for (int i = 0; i < TASK_SIZE; i++) {
String taskName = "TASK" + i;
try {
es.execute(new RunnableTask(taskName));
printState(es, taskName);
} catch (RejectedExecutionException e) {
log(taskName + " -> " + e);
}
}
es.close();
long end = System.currentTimeMillis();
log("time: " + (end - start));
}
--------------------
14:37:58.671 [pool-1-thread-1] TASK0 시작!
14:37:58.680 [ main] TASK0 -> [pool= 1, active= 1, queuedTask= 0, completedTask= 0]
14:37:58.680 [ main] TASK1 -> [pool= 2, active= 2, queuedTask= 0, completedTask= 0]
14:37:58.680 [pool-1-thread-2] TASK1 시작!
...
14:37:58.724 [pool-1-thread-100] TASK99 시작!
14:37:58.724 [ main] TASK100 -> [pool= 100, active= 100, queuedTask= 1, completedTask= 0]
14:37:58.724 [ main] TASK101 -> [pool= 100, active= 100, queuedTask= 2, completedTask= 0]
14:37:58.724 [ main] TASK102 -> [pool= 100, active= 100, queuedTask= 3, completedTask= 0]
...
14:37:58.802 [ main] TASK1099 -> [pool= 100, active= 100, queuedTask= 1000, completedTask= 0]
14:37:59.676 [pool-1-thread-1] TASK0 완료!
...
14:38:09.775 [ main] time: 11106
일반 상황일 때는 별다른 차이 없이 안정적으로 1100 개의 작업을 처리한다. 100개의 기본 스레드가 일을 계속 처리하며, 1000개의 작업은 Queue 에 들어가서 처리를 대기한다. 처음에는 QueuedTask 없이 바로바로 100개의 스레드까지 Task를 바로바로 물어가서 작업을 하지만, 그 이후 1000개의 작업은 queue 에 넣어서 queuedTask 수가 올라간다. 그 이후로는 순차적으로 작업들이 완료된다. 시간은 총 약 11초 정도 걸린 것을 볼 수 있다 (이것만 하더라도 1100초 걸려야 하는 일을.. 멀티 스레딩의 강력함을 알 수 있다).
// static final int TASK_SIZE = 1100; // 일반
static final int TASK_SIZE = 1200; // 긴급
// static final int TASK_SIZE = 1201; // 거절
...
--------------------
14:41:21.000 [pool-1-thread-1] TASK0 시작!
14:41:21.011 [ main] TASK0 -> [pool= 1, active= 1, queuedTask= 0, completedTask= 0]
14:41:21.012 [ main] TASK1 -> [pool= 2, active= 2, queuedTask= 0, completedTask= 0]
14:41:21.012 [pool-1-thread-2] TASK1 시작!
... // core 갯수의 스레드만큼 100개 작업을 바로 문 이후는 Queue 에 넣는다
14:41:21.062 [ main] TASK100 -> [pool= 100, active= 100, queuedTask= 1, completedTask= 0]
14:41:21.062 [ main] TASK101 -> [pool= 100, active= 100, queuedTask= 2, completedTask= 0]
... // 1000 개의 작업이 Queue 를 넘어가면서 초과 스레드를 생성하여 작업을 바로 물리기 시작
14:41:21.153 [ main] TASK1100 -> [pool= 101, active= 101, queuedTask= 1000, completedTask= 0]
14:41:21.153 [pool-1-thread-101] TASK1100 시작!
14:41:21.154 [ main] TASK1101 -> [pool= 102, active= 102, queuedTask= 1000, completedTask= 0]
14:41:21.154 [pool-1-thread-102] TASK1101 시작!
14:41:21.154 [ main] TASK1102 -> [pool= 103, active= 103, queuedTask= 1000, completedTask= 0]
14:41:21.154 [pool-1-thread-103] TASK1102 시작!
... // 200개까지 늘린 이후 지속 재사용
14:41:21.175 [pool-1-thread-199] TASK1198 시작!
14:41:21.176 [ main] TASK1199 -> [pool= 200, active= 200, queuedTask= 1000, completedTask= 0]
14:41:21.176 [pool-1-thread-200] TASK1199 시작!
14:41:22.005 [pool-1-thread-1] TASK0 완료!
14:41:22.006 [pool-1-thread-1] TASK100 시작!
... // 순차적으로 작업 실행
14:41:27.205 [ main] time: 6208
긴급 상황일 경우는, 버퍼 사이즈를 넘어서 100개의 작업을 더 부과했을 경우, 100개의 초과스레드를 생성해서 작업을 시키는 모습을 확인할 수 있다. 즉, 어느정도 긴급상황에 대한 대응을 하고 있는 모습이다. active 와 pool 갯수가 모두 200개까지 늘어난 이후 순차적으로 작업을 지속 수행한다. 초과 스레드까지 모두 재사용되어 200개의 스레드를 돌리기 때문에, 작업 시간이 오히려 11초 -> 6초로 빨라진 모습까지도 확인할 수 있다. 중간 중간에 "14:41:25.192 [pool-1-thread-198] TASK696 완료!" 이런 로그를 확인할 수 있는데, 198 번 스레드 (초과 스레드) 가 계속 다른 작업들까지 수행하고 있는 모습이다.
// static final int TASK_SIZE = 1100; // 일반
// static final int TASK_SIZE = 1200; // 긴급
static final int TASK_SIZE = 1201; // 거절
...
--------------------
... // 위 상황과 모두 계속 동일
... // 200개까지 늘린 이후 지속 재사용, 거절 로그 확인 가능
14:41:21.175 [pool-1-thread-199] TASK1198 시작!
14:41:21.176 [ main] TASK1199 -> [pool= 200, active= 200, queuedTask= 1000, completedTask= 0]
14:41:21.176 [pool-1-thread-200] TASK1199 시작!
14:51:07.171 [ main] TASK1200 -> java.util.concurrent.RejectedExecutionException: Task thread.sec11_executor_1.RunnableTask@2d6eabae rejected from java.util.concurrent.ThreadPoolExecutor@6108b2d7[Running, pool size = 200, active threads = 200, queued tasks = 1000, completed tasks = 0]
14:41:22.005 [pool-1-thread-1] TASK0 완료!
14:41:22.006 [pool-1-thread-1] TASK100 시작!
... // 순차적으로 작업 실행
14:41:27.205 [ main] time: 6208
자원 상황을 고려했을 때, "이정도 넘으면 거절해야한다" 라는 선을 준비할 수 있다. 그리고 그에 맞춰서 ExecutorService 를 준비해 놓을 수 있다. 위 상황에서는 초과 스레드까지 고려시 MAX 작업은 1200까지인 것이다. 그래서 한 가지 작업에 대해서 거절한 로그를 확인할 수 있다. 만약 위에서 BlockingQueue 를 Linked 로 활용해서 제한을 주지 않는다면, 초과 스레드는 Queue 가 꽉찼다고 인지하지 않아서 [긴급상황] 인식을 하지 않으므로, 동작하지 않는다. 이는 실제로 실무에서 자주하는 실수로, LinkedBlockingQueue 로 넣는다면 초과 스레드를 사용하지 않겠다는 뜻임을 확실히 인지하자.
이렇게 직접 자신의 자원 상황을 고려하여, ThreadPool 을 직접 제어해서 활용하는 것이 Best Practice 사례라고 할 수 있다. ExecutorService 의 [긴급상황] 전략에 대해 잘 이해하는 것이 중요하고, 만약 정말 사용한다면 위에서 살펴본 예시대로 문제에 대한 인식을 하기 위한 [정확한 스레드 풀 상황 로깅] 이 정말 정말 정말 중요한 것 같다!!
6. Executor 예외 정책
ThreadPoolExecutor 를 사용할 때 기본적으로 초과 스레드를 넘어선 요청은 RejectException 을 터뜨리면서 거절한다고 배웠다. 사실 Executor 는 더 다양한 작업 거절 정책을 제안한다. RejectedExecutionException 을 터뜨리는 것은 기본 정책인 AbortPolicy 이다. DiscardPolicy 는 아무 notify 없이 버리고, CallerRunsPolicy 는 요청 스레드 (생산자)한테 "야, 니가해!" 라고 하는 것이다(CallerRunsPolicy 는 상당히 재밌는게, 피자 받으러 온 사람한테 바쁘니까 님이 와서 좀 만드세요 하는 모습이라고 한다 ㅋㅋㅋ). 또한, RejectedExecutionHandler 로 직접 거절 정책을 만들고 설정할 수도 있다. 참고로 여기서 설정된 정책은 shutdown() 함수 이후 들어오는 작업들에 대해 동일하게 적용된다.
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0, TimeUnit.SECONDS
, new SynchronousQueue<>(), new ThreadPoolExecutor.AbortPolicy());
마지막으로 전달되는 인자는 "RejectedExecutionHandler" 의 구현체를 전달한다. 직접 제어를 원하면 구현해서 전달하면 된다. 스레드 풀이 더이상 못받는데 싶으면 내부의 rejectedExecution 함수를 호출하는 것이다. AbortPolicy 는 예외를 터뜨리기 때문에, try/catch 없이는 후속 로직을 실행하지 못한다. 하지만 DiscardPolicy 는 다음과 같이 try/catch 없이도 "조용히 버리기 때문"에 아무 로깅이나 예외도 남기지 않는다.
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
라이브러리를 살펴보면 그냥 빈 함수인 것도 확인할 수 있다. 그냥 버린다. CallerRunsPolicy 까지 살펴보면, 다음과 같은 함수가 구현된 모습을 확인할 수 있다.
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
rejectedExecution 은 요청스레드가 인지하고 호출하는 구조이다. 따라서, e 가 종료중인 상태가 아니였다면, 전달 받은 Runnable 을 직접 run() 함수로 스스로 수행하는 모습을 확인할 수 있다. shutdown 을 체킹하는 이유는 es.close 이후에도 정책대로 거절하기 때문에, 종료된거라면 작업을 실행하지 않기 위해서이다.
public static void main(String[] args) {
// 바로 거절되는걸 보기 위해 버퍼 0 짜리로 만듬
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0, TimeUnit.SECONDS
, new SynchronousQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());
executor.submit(new RunnableTask("TASK1"));
executor.submit(new RunnableTask("TASK2")); // 거절당할 것임
executor.close();
}
--------------------
15:18:31.020 [ main] TASK2 시작! // main 이 TASK2 를 실행한다
15:18:31.020 [pool-1-thread-1] TASK1 시작!
15:18:32.063 [pool-1-thread-1] TASK1 완료!
15:18:32.063 [ main] TASK2 완료!
위 예제에서는 CallerRunsPolicy 를 적용했는데, main 함수가 직접 Task2 를 실행하는 재미있는 모습을 볼 수 있다. 이 방식의 주된 포인트는 물론 작업 분할도 있지만, "생산 속도 조절"의 측면이 더 크다고 한다. 생산자의 역할을 하는 요청 스레드에게 "생산 잠깐 그만하고 일 좀 해"라고 한다면, 생산 속도를 지연시켜서 작업 처리의 안정성을 가져갈 수 있다. 마지막으로, 만약 원하는대로 처리하고 싶으면, RejectedHandler 를 구현하면 된다.
static class MyRejectedExecutionHandler implements RejectedExecutionHandler {
static AtomicInteger cnt = new AtomicInteger(0);
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 실행은 중요하지 않은데, 거절된 작업이 몇갠지는 알고 있자.
int i = cnt.incrementAndGet();
log("[경고] 거절된 누적 작업 수 : " + i);
}
}
이와 같이, 거절된 작업이 몇 개인지 로그만 남겨주는 상황을 원한다 (DiscardPolicy 에서 로깅만 더해짐). 그러면 위와 같이 Handler 에 대한 구현체를 만들면 되고, 이를 ExecutorService 에게 전달해주면 된다. rejectedExecution 함수는 어쨌든 요청 스레드가 호출하는 구조인 것은 기억하고 있자 (Runnable r 이 전달되는 이유는 거절 작업 어떻게 할 건지? 를 위해). 그리고 다음과 같이 테스트를 해보면, 거절된 작업들이 몇 개인지 확인할 수 있다.
public static void main(String[] args) {
// 바로 거절되는걸 보기 위해 버퍼 0 짜리로 만듬
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0, TimeUnit.SECONDS
, new SynchronousQueue<>(), new MyRejectedExecutionHandler());
executor.submit(new RunnableTask("TASK1"));
executor.submit(new RunnableTask("TASK2")); // 거절당할 것임
executor.submit(new RunnableTask("TASK3")); // 거절당할 것임
executor.submit(new RunnableTask("TASK4")); // 거절당할 것임
executor.close();
}
---------------------
15:45:11.935 [pool-1-thread-1] TASK1 시작!
15:45:11.935 [ main] [경고] 거절된 누적 작업 수 : 1
15:45:11.940 [ main] [경고] 거절된 누적 작업 수 : 2
15:45:11.941 [ main] [경고] 거절된 누적 작업 수 : 3
15:45:12.943 [pool-1-thread-1] TASK1 완료!
마지막으로 강사님이 해주는 말이 있는데, 오버 엔지니어링에 대한 주의이다. "가장 좋은 최적화는 최적화하지 않는 것" 이라는 명언이 있다고 한다. 많은 개발자가 미래에 발생하지 않을 일 때문에 코드를 최적화하는 경우가 많은데, 배보다 배꼽이 큰 상황인 경우가 정말 태반이라고 한다. 나 스스로도 정말 많았고, 지금도 회사에선 이런 측면이 99%인 프로젝트도 많다. 항상 "현재 상황에 맞는 최적화가 필요"하다는 것을 명심하자. 요청자가 없는데 최적화하는 모습... 좋지 않다.
왜 이런 얘기가 나오냐면, 풀 전략 선택할 때 너무 고민하지 말라고 하신다. 그냥 처음에는 간단하게 해도 되고, 자체 프로젝트면 고정 풀이나 캐시 풀 쓰면서 시작해도 괜찮기 때문이다. 자원만 괜찮으면 스레드 천 개로 고정풀! 이런 식도 괜찮다. 만약 이 프로젝트가 겁나 잘된다! 하면 그 때 최적화를 하면 된다는 것이다. 오히려 최적화보단 상황 모니터링이 훨씬 중요하구나 싶기도 하다!! 당장 우리가 한 ExecutorUtils 의 로깅만 있어도 상황을 아는데 아주 큰 도움이 되었다. 나중에는 그라파나 이런 것도 적용하면 훨씬 고도화된 모니터링까지 가능하다.
제일 중요한 건 시스템 다운을 막는 것이다 (물론 중요한 방지 정책도 필요). 시스템의 자원을 적절하게 활용하되, 최악의 경우 적절한 거절까지 하면서 서비스를 운영하자 (잠시 후 다시 시도해주세요 같은 처리). 적절한 거절은 서버도 우리 삶에도 반드시 필요하다.
<마지막 퀴즈에서 참고>

이거 틀렸는데, 난 2번이라고 했다. 근데 2번 3번 모두 차이가 있긴 한 것 같다. shutdownNow 는 실행 중인 작업에 대한 이터럽트까지 시도해서 큰 차이긴 하다. 하지만 2번 역시 다른 점은 알아야 한다. shutdownNow 는 큐에 있는 작업을 반환하지만, shutdown 같은 경우는 큐에 있는 작업까지 모두 실행한 다음에 종료된다. 따라서 난 둘 다 정답같긴 하다.

정리하며
이번 강의 역시 꽤 어려웠다. 스레드를 사용함에 있어서 모니터링은 정말 정말 중요하다는 것을 느낄 수 있었고, 스레드 풀이 어떻게 관리되는지를 배우면서 자바의 섬세한 처리를 다시한 번 느낄 수 있었다... 정말 concurrent 패키지는 대단하다고 느낄 수 있었다. 사실 이건 다 자바 내용인데, 스프링은 이와 어떻게 연결되는지 너무너무 궁금하다. 이건 스프링 단이 아니라 톰캣 단까지 당연히 갈 것 같다. 스레드 풀 자체가 톰 캣 단에 있는 것으로 알기 때문이다. 이 연장선까지 공부해볼 수 있으면 좋겠다.
출처
[실전 Java 고급 1편]으로 엮인 모든 포스트들은 교육 사이트 인프런의 지식공유자이신 김영한님의 [김영한의 실전 자바 - 고급 1편, 멀티스레드와 동시성] 강의를 기반으로 작성되었습니다. 열심히 정리하고 스스로 공부하기 위해 만든 포스트이지만, 제대로 공부하고 싶으시면 해당 강의를 꼭 들으시는 것을 추천드립니다.
'Java' 카테고리의 다른 글
| [Java Multi-Threading] 생산자 소비자 Queue 예제 연습해보기 (2) | 2025.05.30 |
|---|---|
| [실전 Java 고급 1편] - 5. Executor Framework 에 대하여 (0) | 2025.04.27 |
| [실전 Java 고급 1편] - 4. CAS와 동시성 컬렉션 (0) | 2025.01.31 |
| [실전 Java 고급 1편] - 3. 생산자 소비자 문제 (BlockingQueue 만들기까지) (0) | 2025.01.31 |
| [실전 Java 고급 1편] - 2. 메모리 가시성과 동기화 (0) | 2025.01.31 |